一致性共识算法在互联网场景中的应用
世界上只有一种一致性算法就是Paxos(帕克索斯)。在工程上通常使用其简化版本的Raft算法。算法的核心思想都是,在保证CP的前提下,只要大多数的节点可以互联,系统便一直处于可用状态(A)。
背景
为什么会有一致性算法的需求?
演变:摩尔定律(预计18个月会将芯片的性能提高一倍,更多的晶体管使其更快) -> 当摩尔定律无法满足时,需要分布式 -> 在分布式场景下,需要解决容错/一致性或共识问题。
Google, LADIS 2009报告称:硬件的不可靠性,必须从软件层面解决。

分布式系统的事务处理的文章,讲述了常见的处理一致性问题的方法。一致性的问题主要来源于:
- 一台服务器的性能不足以提供足够的能力服务于所有的网络请求。 – 需要扩容,解决性能问题
- 我们总是害怕我们的这台服务器停机,造成服务不可用或是数据丢失。 – 需要扩容,解决单点问题
因此,通常的做法是:
- 数据分区:就是把数据分块放在不同的服务器上(如:uid % 16,一致性哈希等)。
- 数据镜像:让所有的服务器都有相同的数据,提供相当的服务。
通过上述做法,可以解决性能(A)和单点(p)问题,但是却无法在分区的情况下保证数据的一致性(C)。即,CAP只能满足其二。
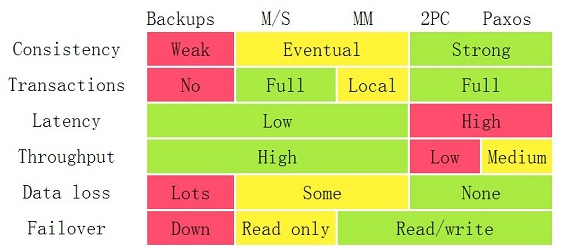
分布式共识原理
一致性算法,也称为分布式共识。共识 (Consensus)的定义是:
系统中有n个节点,其中最多有f个节点可能崩溃。节点i从一个输入值v_i开始,所有节点必须要从全部输入值中最终选择一个值,并且满足以下条件。
- 一致性
- 可终止性
- 有效性
思考:Paxos算法满足以上要求吗?
Paxos算法不能保证可终止性。例如,如果两个客户端持续地请求票,并且哪一个都不能获得过半数服务器的票,那么系统就会永远卡在那儿。
FLP不可能原理:在网络可靠,存在节点失效(即便只有一个)的最小化异步模型系统中,不存在一个可以解决一致性问题的确定性算法。
理解这一原理的一个不严谨的例子是:三个人在不同房间,进行投票(投票结果是 0 或者 1)。三个人彼此可以通过电话进行沟通,但经常会有人时不时地睡着。比如某个时候,A 投票 0,B 投票 1,C 收到了两人的投票,然后 C 睡着了。A 和 B 则永远无法在有限时间内获知最终的结果。如果可以重新投票,则类似情形每次在取得结果前发生。
FLP 原理实际上说明对于允许节点失效情况下,纯粹异步系统无法确保一致性在有限时间内完成。
这岂不是意味着研究一致性问题压根没有意义吗?先别这么悲观,学术界做研究,考虑的是数学和物理意义上最极端的情形,很多时候现实生活要美好的多(感谢这个世界如此鲁棒!)。例如,上面例子中描述的最坏情形,总会发生的概率并没有那么大。工程实现上多试几次,很大可能就成功了。科学告诉你什么是不可能的;工程则告诉你,付出一些代价,我可以把它变成可能 。回答这一问题的是另一个很出名的原理:CAP 原理。 科学上告诉你去赌场赌博从概率上总会是输钱的;工程则告诉你,如果你愿意接受最终输钱的结果,中间说不定偶尔能小赢几笔呢。
常见的分布式共识算法
算法1:带确认的Client和Server算法 + Seq
- 消息传递 -> 消息丢失
- TCP协议(定时器)
- 缺点:不支持多个Client
算法2:单一串行化实现状态复制
- 解决可变消息延迟问题。算法1在多个C和多个S间运行,S接收到的命令顺序可能是不同的,将导致不一致的状态。
- 缺点:单点故障
算法3:锁,2PC
- 确保任何时候最多只有一个C在执行,Gray, 1978
- 单点故障。
- MySQL XA分布式事务
- 缺点:异常处理复杂

算法4:朴素的基于投票的协议
- 票(Ticket)是弱化形式的锁
- 特点:解决宕机问题,票可重新发布,可以过期
- 缺点:得到票并不意味着服务器会给客户端保留位置,客户端必须马上去竞争,否则会存在不一致问题

算法5:Paxos (多个提案者+多个接收者)
故事背景是古希腊 Paxon 岛上的多个法官在一个大厅内对一个议案进行表决,如何达成统一的结果。他们之间通过服务人员来传递纸条,但法官可能离开或进入大厅,服务人员可能偷懒去睡觉。Paxos 是第一个被证明的共识算法,其原理基于两阶段提交 并进行扩展。作为现在共识算法设计的鼻祖,以最初论文的难懂(算法本身并不复杂)出名。算法中将节点分为三种类型:
- proposer:提出一个提案,等待大家批准为结案。往往是客户端担任该角色
- acceptor:负责对提案进行投票。往往是服务端担任该角色
- learner:被告知结案结果,并与之统一,不参与投票过程。可能为客户端或服务端
基本过程包括 proposer 提出提案,先争取大多数 acceptor 的支持,超过一半支持时,则发送结案结果给所有人进行确认。一个潜在的问题是 proposer 在此过程中出现故障,可以通过超时机制来解决。极为凑巧的情况下,每次新的一轮提案的 proposer 都恰好故障,系统则永远无法达成一致(概率很小)。
- Leslie Lamport, 1989,获得2013年度图灵奖
- 如何让两个客户端都尝试存储和执行相同的命令
- 服务器不但发布票,而且也发布当前所存储的命令(解决执行顺序问题)
- 客户端生成尝试的全局一致票号(保证最大票号是最新的命令)

- 优点:解决宕机问题。
- 如果客户端在告诉任何一个服务器执行命令之前就宕机了,所有服务器将只有等到下一个客户端成功获得提案之后才可以执行之前已保存的命令。
- 如果一个服务器接收到一个请求去执行命令,它可以通知所有后面到达的客户端已经有一条命令选中了。
- 缺点:
- 超过一半的服务器宕机,将不能工作。
- 是CFT,而不是BFT。

更多介绍:Paxos
算法6:Raft (一个提案者+多个接收者)
Raft属于强一致性算法(CP),在牺牲一定程度的可用性(A)上,来保证一致性(C)。
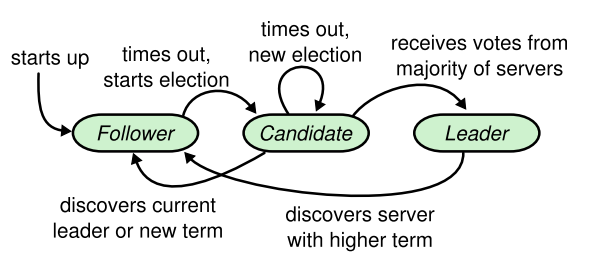
- Raft 算法是Paxos 算法的一种简化实现(一个提案周期内只有一个提案者)。包括三种角色:
leader,candidate和follower - 由leader发起写操作
- 例子:etcd
基本过程:
- Leader选举:每个candidate随机经过一定时间都会提出选举方案,最近阶段中得票最多者被选为leader
- 同步log:leader会找到系统中log最新的记录,并强制所有的follower来刷新到这个记录
1. 都使用`timeout`来重新选择`leader`。
2. 采用`quorum`(法定人数)来确定整个系统的一致性,一般是集群中半数以上的服务器。zk里还提供了带权重的`quorum`实现。
3. 都由`leader`来发起写操作。
4. 都采用心跳检测存活性。
5. leader election都采用先到先得的投票方式。
算法特点:
- 强一致性。leader节点的数据最全。
- 高可靠性。committed的日志不会被修改,少于一半的磁盘故障数据不会丢失。
- 高可用性。少量节点故障或网络异常不影响可用性。
- 高性能。大多数节点成功即可。
More:
算法7:PBFT
- Liskov, 1999,主要应用于联盟链的共识算法。
- 实用的拜占庭容错算法,对Paxos进行了改进,使其可以处理拜占庭错误。
- 一个可能呈现任意行为的节点,被称为拜占庭。(如何保证有效性?)
- 异步模式下的算法时间复杂度:随节点数量n呈指数增长。(2^-(n-f)+1)
- 当前最快的算法的时间复杂度为O(n^2.5),但是仅能容忍f<=1/500n个拜占庭节点。
可用性评估
系统的可用性(Availability) = MTBF(平均故障间隔时间) / MTBF + MTTR(平均故障修复时间)
业界通常用N个9来表示系统的可用性。例如,99.999%代表5个9的可用性,表示全年不可用时间必须保证在5.26分钟以内。
典型应用
Chubby (Google)
使用paxos来保证日志在各个副本上的一致性,在这之上是高容错的分布式数据库层。
ZooKeeper (Yahoo, Hadoop)
- ZAB,设计思想类似于Paxos。
- 分布式配置管理
PhxPaxos (Tencent wechat)
基于Paxos的类库,实现多机的状态拷贝。
TDSQL
基于Raft的共识,主从模式,一个set是1主2备。