DeepSeek in Action
- 名词解释
- 背景介绍
- DeepSeek-R1 的核心创新点
- 技术原理
- DeepSeek-R1
- DeepSeek-V3
- 快速使用 Deepseek-R1 模型
- 通过腾讯云 API 调用
- 大小模型效果对比 (DeepSeek-R1-Distill-Qwen-1.5B VS. DeepSeek-R1)
- Tools
- Refer
名词解释
-
AI(Artificial Intelligence) 人工智能。指通过计算机系统实现的一种模拟人类智能行为的技术,它是一种非常广泛的概念,包括了很多不同的方法和技术,如机器学习,深度学习,专家系统和自然语言处理等。主要是让计算机可以像人一样执行各种任务,比如识别语音,识别图像,能对自然语言进行处理等。AI 的目标是使计算机系统能够模仿人类智能的某些特定方面,如感知,理解,学习,推理和决策等。 -
AGI(Aritificial General Intelligence),是指一种能够在各种不同任务和环境中都表现出类似于人类智能的系统。它能处理各种类型的任务,而不像 AI 仅仅是处理特定领域的任务。AGI 的发展目标是使计算机能够像人类一样思考和行动,从而使其能够自主的解决各种问题,其实这才是人类真正惧怕人工智能的源头。 -
AIGC(Aritificial Intelligence Generated Content),指的是人工智能生成内容。比如,ChatGPT和DeepSeek的应用。
背景介绍
DeepSeek 是由深度求索公司推出的大语言模型。其中:
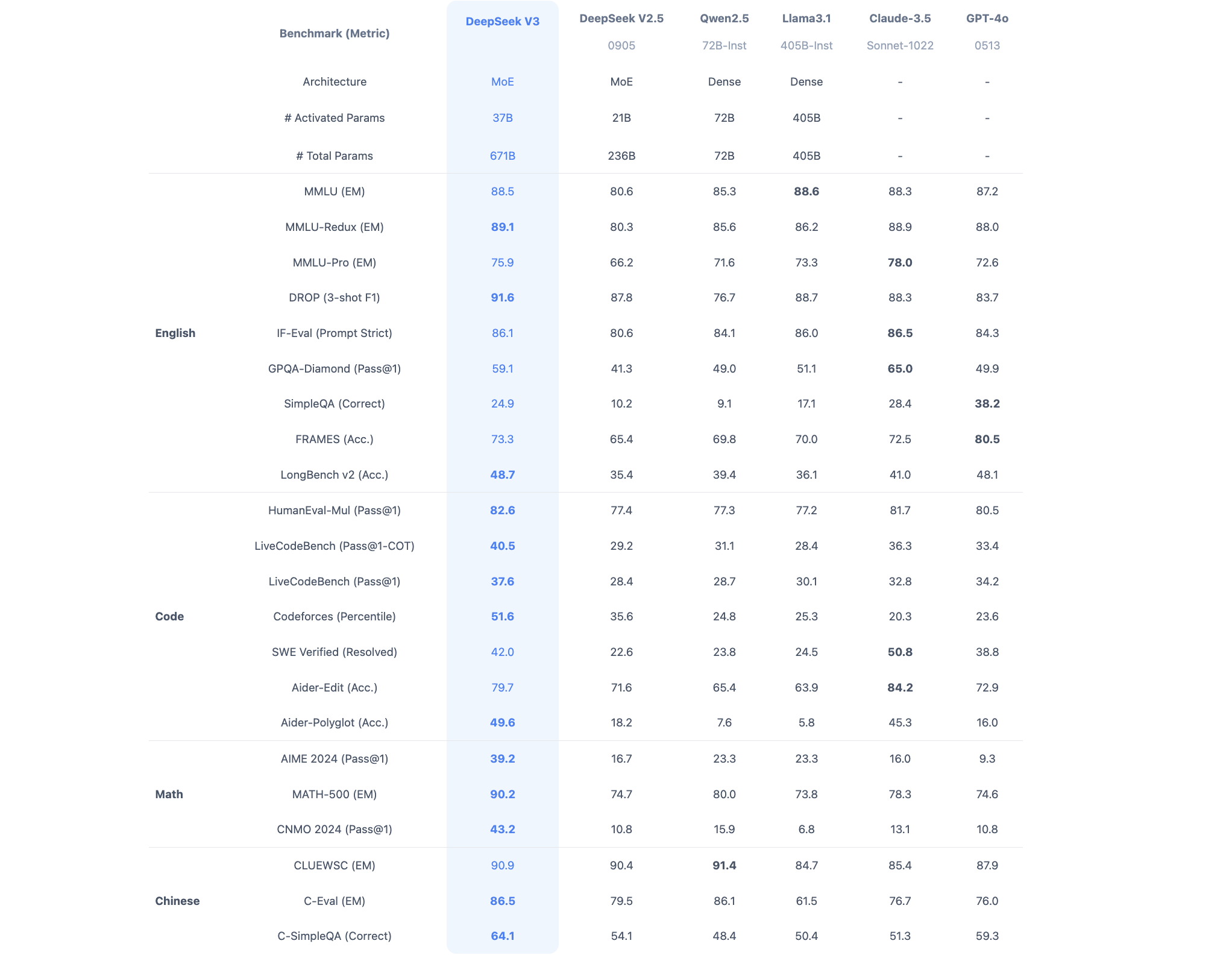
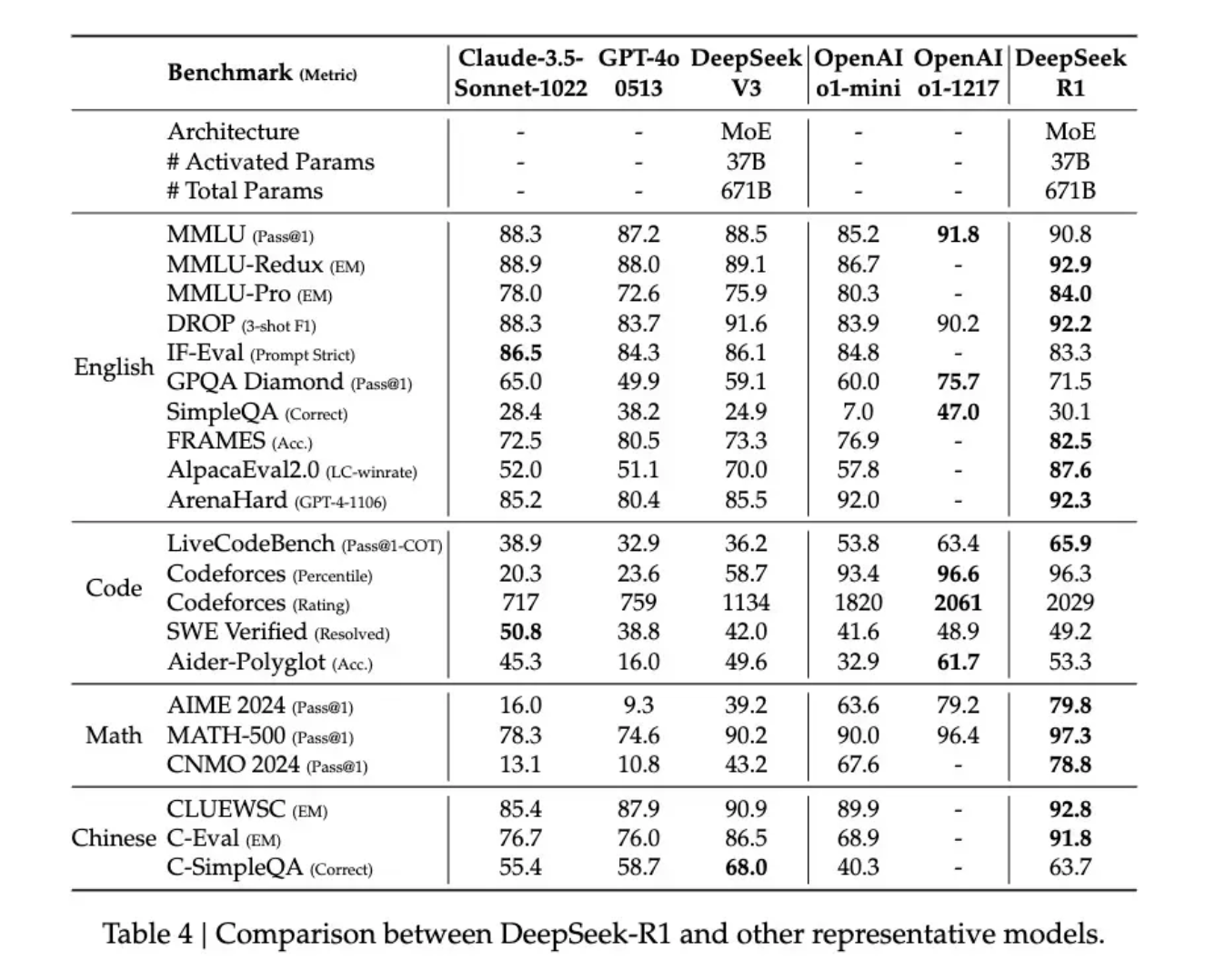
DeepSeek-V3是在14.8万亿高质量 token 上完成预训练的一个强大的混合专家 (MoE) 语言模型,拥有6710亿参数。作为通用大语言模型,其在知识问答、内容生成、智能客服等领域表现出色。DeepSeek-R1是基于DeepSeek-V3-Base训练生成的高性能推理模型,在数学、代码生成和逻辑推断等复杂推理任务上表现优异。DeepSeek-R1-Distill是使用DeepSeek-R1生成的样本对开源模型进行有监督微调(SFT)得到的小模型,即蒸馏模型。拥有更小参数规模,推理成本更低,基准测试同样表现出色。
DeepSeek-V3 在推理速度上相较历史模型有了大幅提升。在目前大模型主流榜单中,DeepSeek-V3 在开源模型中位列榜首,与世界上最先进的闭源模型不分伯仲。论文:https://github.com/deepseek-ai/DeepSeek-R1/blob/main/DeepSeek_R1.pdf
前 Meta AI 工作人员、知名 AI 论文作者 Elvis 在推特发文,DeepSeek-R1 的论文堪称瑰宝,因为它探索了提升大语言模型推理能力的多种方法,并发现了其中更明确的涌现特性。

另一位 AI 圈大V Yuchen Jin 则认为,DeepSeek-R1 论文中提出的,模型利用纯 RL 方法引导其自主学习和反思推理这一发现,意义非常重大。
英伟达 GEAR Lab 项目负责人 Jim Fan 在推特中也提到了,DeepSeek-R1 用通过硬编码规则计算出的真实奖励,而避免使用任何 RL 容易破解的学习奖励模型。这使得模型产生了自我反思与探索行为的涌现。

DeepSeek-R1 的核心创新点
群体相对策略优化 GRPO (Group Relative Policy Optimization) 算法
DeepSeek-R1 采用的群体相对策略优化(GRPO)算法通过群体内策略对比来优化模型,避免了依赖复杂的单一评价函数或传统的监督微调方法。与 GPT-4 相比,GRPO 使得训练更加高效,减少了模型参数量 40%-60%,提升了训练速度 3.2 倍,且不依赖复杂的价值模型,使得整体计算效率大幅提高。
纯强化学习驱动
DeepSeek-R1 是首个完全基于强化学习驱动推理进化的 AI 系统,无需借助监督微调(SFT)或人类反馈强化学习(RLHF)的结合。这一点与 GPT-4 等传统模型不同,后者通常依赖人工调整和外部反馈。DeepSeek-R1 在完全自主学习和推理上展示了新的潜力,是 AI 推理和自主学习的重要进步。
自我进化能力
在训练过程中,DeepSeek-R1 能够展示自我进化的特性,如内建的反思机制和多步验证能力。与 GPT-4 等传统模型相比,DeepSeek-R1 在强化学习过程中具备自主回顾并优化推理步骤的能力,类似人类的思维反思,优化推理路径,而 GPT-4 则缺乏这种自我调整机制。
多阶段训练框架
DeepSeek-R1 用冷启动数据、强化学习和监督微调相结合的多阶段训练框架。冷启动数据帮助模型快速稳定地开始学习,再通过强化学习进一步提升推理能力,最后利用监督微调进行细节优化。多阶段的训练方法保证了模型在不同阶段的学习稳定性和效率,相比之下,GPT-4 依赖更长时间的训练并缺乏专门的思维链引导机制,导致训练过程可能更加缓慢且复杂。
技术原理
- 纯 RL 方法训练模型是指什么?
- 模型出现的
Aha Moment,又凭什么能证明 AI 具有了涌现能力? - DeepSeek-R1 的这一重要创新对于 AI 领域未来的发展,究竟意味着什么?
用最简单的配方,回归最纯粹的强化学习
在 o1 推出之后,推理强化成了业界最关注的方法。一般来说,一个模型在训练过程中只会尝试一种固定训练方法来提升推理能力。而 DeepSeek 团队在 R1 的训练过程中,直接一次性实验了三种截然不同的技术路径:直接强化学习训练(R1-Zero)、多阶段渐进训练(R1)和模型蒸馏,还都成功了。多阶段渐进训练方法和模型蒸馏都包含着很多创新意义元素,对行业有着重要影响。其中最让人激动的,还是直接强化学习这个路径。因为 DeepSeek-R1 是首个证明这一方法有效的模型。
训练 AI 的推理能力传统的方法通常是什么?一般是通过在监督微调 (SFT) 加入大量的思维链 (COT)范例,用例证和复杂的如过程奖励模型 (PRM) 之类的复杂神经网络奖励模型,来让模型学会用思维链思考。甚至会加入蒙特卡洛树搜索 (MCTS),让模型在多种可能中搜索最好的可能。但 DeepSeek-R1-Zero 选择了一条前所未有的路径“纯”强化学习路径,它完全抛开了预设的思维链模板 (Chain of Thought) 和监督式微调 (SFT),仅依靠简单的奖惩信号来优化模型行为。这就像让一个天才儿童在没有任何范例和指导的情况下,纯粹通过不断尝试和获得反馈来学习解题。DeepSeek-R1-Zero 有的只是一套最简单的奖励系统,来激发 AI 的推理能力。
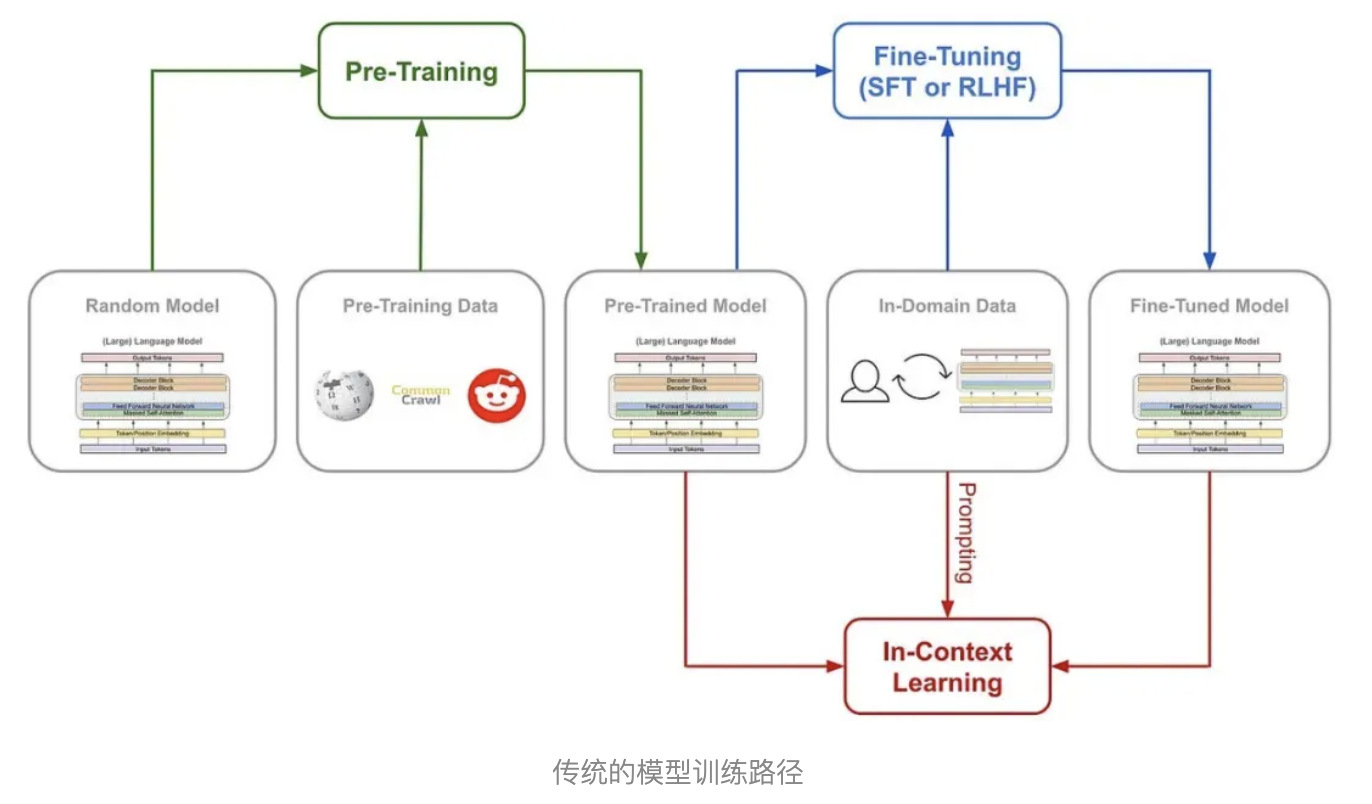
简单来说,可以把它想象成老师出题,每道题让模型同时回答多次,然后用上面的奖惩规则给每个答案打分,根据追求高分、避免低分的逻辑更新模型。流程大概是这样的:输入问题 → 模型生成多个答案 → 规则系统评分 → GRPO (Group Relative Policy Optimization) 计算相对优势 → 更新模型。这种直接训练方法带来了几个显著的优势。首先是训练效率的提升,整个过程可以在更短的时间内完成。其次是资源消耗的降低,由于省去了 SFT 和复杂的奖惩模型,计算资源的需求大幅减少。更重要的是,这种方法真的让模型学会了思考,而且是以“顿悟”的方式学会的。这种顿悟往往是模型思维能力跃升的时刻。
用自己的语言,在“顿悟”中学习
我们是怎么看出模型在这种非常“原始”的方法下,是真的学会了“思考”的呢?论文记录了一个引人注目的案例:在处理一个涉及复杂数学表达式的问题时,模型突然停下来说 “Wait, wait. Wait. That’s an aha moment I can flag here”(等等、等等、这是个值得标记的啊哈时刻),随后重新审视了整个解题过程。这种类似人类顿悟的行为完全是自发产生的,而不是预先设定的。

因为根据 DeepSeek 的研究,模型的进步并非均匀渐进的。在强化学习过程中,响应长度会出现突然的显著增长,这些”跳跃点”往往伴随着解题策略的质变。这种模式酷似人类在长期思考后的突然顿悟,暗示着某种深层的认知突破。
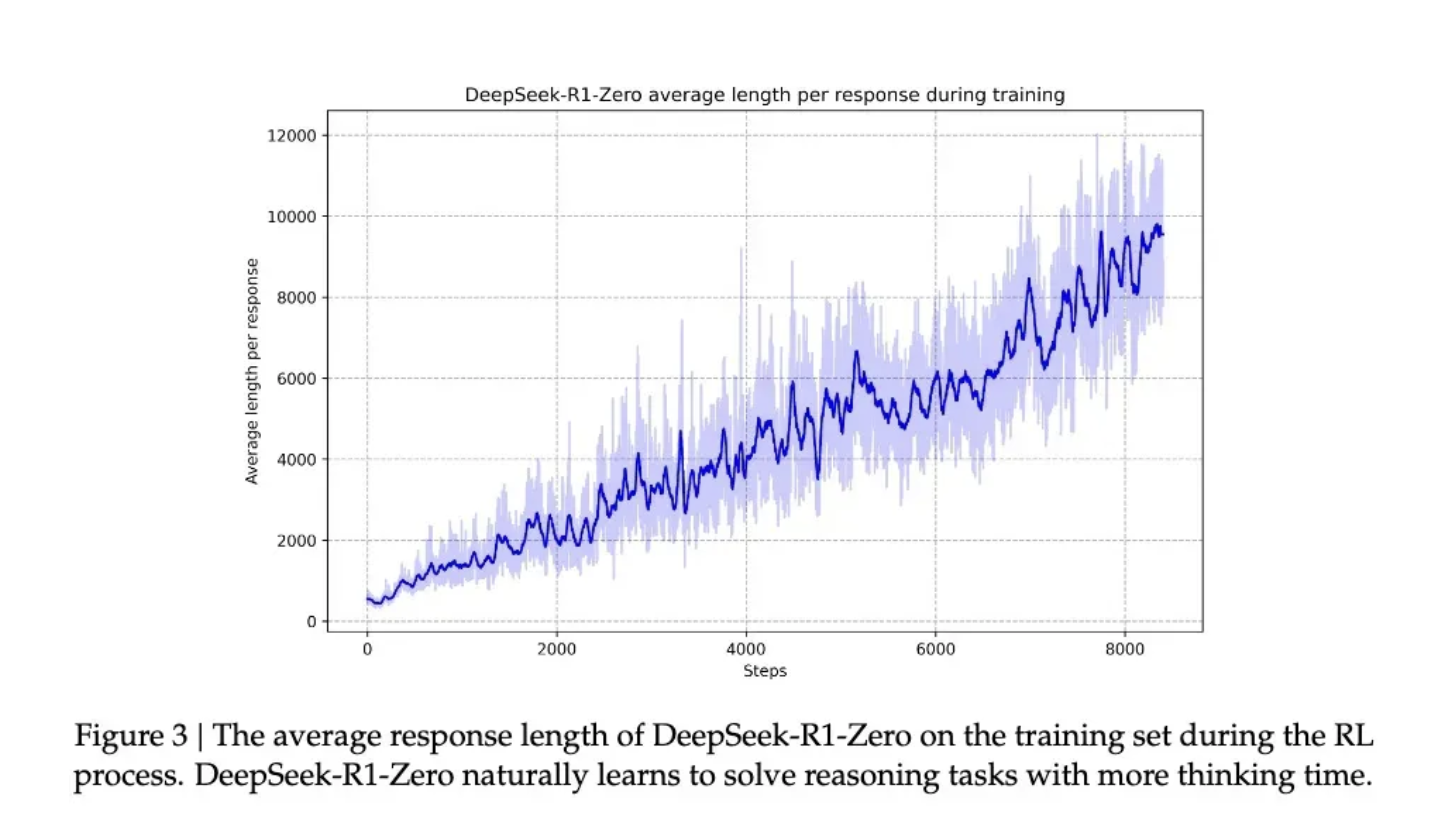
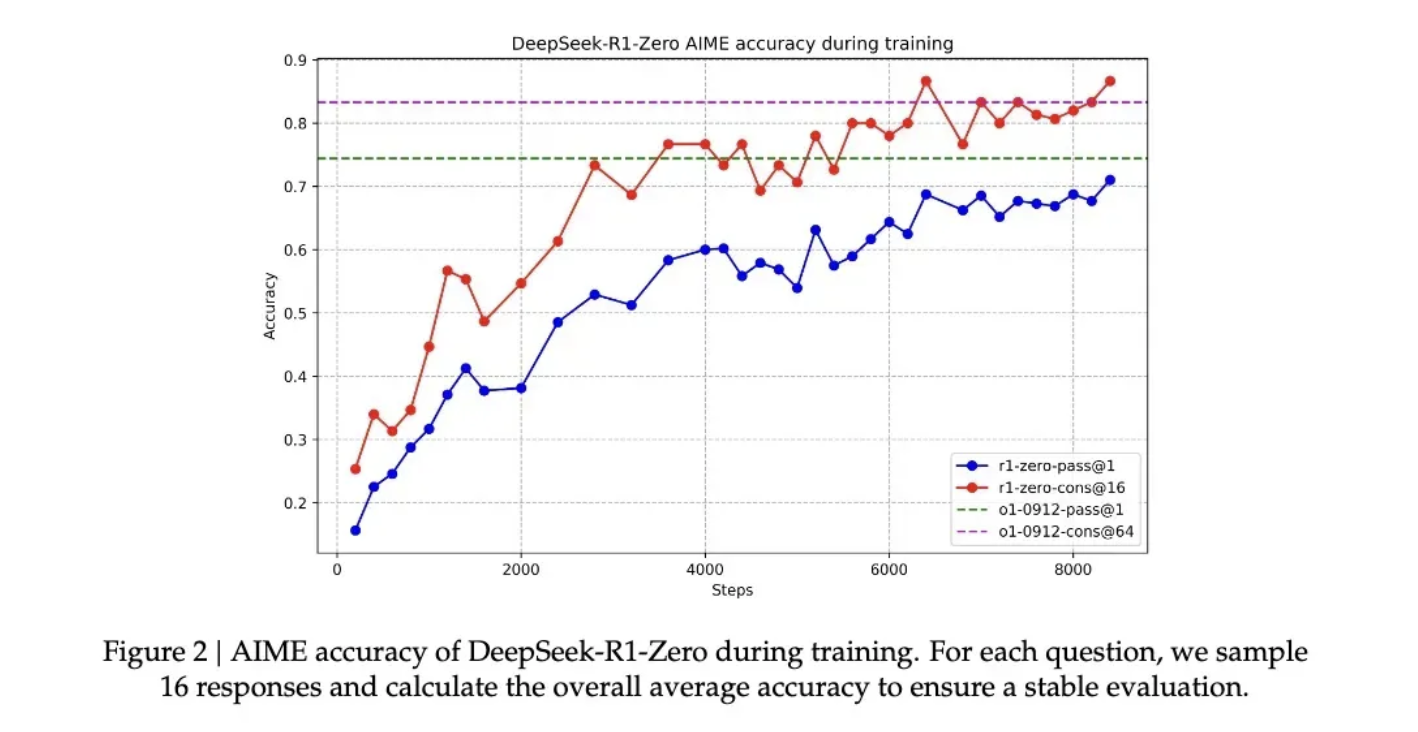
在这种伴随着顿悟的能力提升下,R1-Zero 在数学界享有盛誉的 AIME 竞赛中从最初的 15.6% 正确率一路攀升至 71.0% 的准确率。而让模型对同一问题进行多次尝试时,准确率甚至达到了 86.7%。这不是简单的看过了就会做了——因为AIME的题目需要深度的数学直觉和创造性思维,而不是机械性的公式应用。模型基本必须能推理,才可能有这样的提升。另一个模型确实通过这种方法学会了推理的另一个核心证据,是模型响应长度会根据问题的复杂度自然调节。这种自适应行为表明,它不是在简单地套用模板,而是真正理解了问题的难度,并相应地投入更多的”思考时间”。就像人类面对简单的加法和复杂的积分会自然调整思考时间一样,R1-Zero 展现出了类似的智慧。最有说服力的或许是模型展现出的迁移学习能力。在完全不同的编程竞赛平台 Codeforces 上,R1-Zero 达到了超过 96.3% 人类选手的水平。这种跨域表现表明,模型不是在死记硬背特定领域的解题技巧,而是掌握了某种普适的推理能力。
一个聪明但口齿不清的天才
尽管 R1-Zero 展现出了惊人的推理能力,但研究者们很快发现了一个严重的问题:它的思维过程往往难以被人类理解。论文坦诚地指出,这个纯强化学习训练出来的模型存在 “poor readability”(可读性差)和 “language mixing”(语言混杂)的问题。这个现象其实很好理解:R1-Zero 完全通过奖惩信号来优化其行为,没有任何人类示范的”标准答案”作为参考。就像一个天才儿童自创了一套解题方法,虽然屡试不爽,但向别人解释时却语无伦次。它在解题过程中可能同时使用多种语言,或者发展出了某种特殊的表达方式,这些都让其推理过程难以被追踪和理解。
正是为了解决这个问题,研究团队开发了改进版本 DeepSeek-R1。通过引入更传统的 “cold-start data”(冷启动数据)和多阶段训练流程,R1 不仅保持了强大的推理能力,还学会了用人类易懂的方式表达思维过程。这就像给那个天才儿童配了一个沟通教练,教会他如何清晰地表达自己的想法。在这一调教下之后,DeepSeek-R1 展现出了与 OpenAI o1 相当甚至在某些方面更优的性能。在 MATH 基准测试上,R1 达到了 77.5% 的准确率,与 o1 的 77.3 %相近;在更具挑战性的 AIME 2024 上,R1 的准确率达到 71.3%,超过了 o1 的 71.0%。在代码领域,R1 在 Codeforces 评测中达到了 2441 分的水平,高于 96.3% 的人类参与者。然而,DeepSeek-R1 Zero 的潜力似乎更大。它在 AIME 2024 测试中使用多数投票机制时达到的 86.7% 准确率——这个成绩甚至超过了 OpenAI 的 o1-0912。这种”多次尝试会变得更准确”的特征,暗示 R1-Zero 可能掌握了某种基础的推理框架,而不是简单地记忆解题模式。论文数据显示,从 MATH-500 到 AIME,再到 GSM8K,模型表现出稳定的跨域性能,特别是在需要创造性思维的复杂问题上。这种广谱性能提示 R1-Zero 可能确实培养出了某种基础的推理能力,这与传统的特定任务优化模型形成鲜明对比。所以,虽然口齿不清,但也许 DeepSeek-R1-Zero 才是真正理解了推理的“天才”。
纯粹强化学习,也许才是通向 AGI 的意外捷径
之所以 DeepSeek-R1 的发布让圈内人的焦点都投向了纯强化学习方法,因为它完全可以说得上是打开了AI 进化的一条新路径。R1-Zero 这个完全通过强化学习训练出来的 AI 模型,展现出了令人惊讶的通用推理能力。它不仅在数学竞赛中取得了惊人成绩。更重要的是,R1-Zero 不仅是在模仿思考,而是真正发展出了某种形式的推理能力。因为在过往的训练方法中,尤其在监督微调中使用训练好的神经网络来评估质量的话,模型可能学会触发奖励模型的特定模式,生成对奖励模型”口味”的内容,而不是真正提升推理能力。换句话说,AI 系统找到了获得高奖励但实际上违背训练目标的投机取巧方式。这就是我们常说的奖励欺骗(reward hacking)。但 R1-Zero 用极简的奖励规则基本避免了奖励欺骗的可能性——规则太简单了,没有什么“口味”可以去模仿。模型在这个情况下发展出的推理能力更可信,也更自然。这个发现可能会改变我们对机器学习的认识:传统的 AI 训练方法可能一直在重复一个根本性的错误,我们太专注于让 AI 模仿人类的思维方式了,业界需要重新思考监督学习在 AI 发展中的角色。通过纯粹的强化学习,AI 系统似乎能够发展出更原生的问题解决能力,而不是被限制在预设的解决方案框架内。
虽然 R1-Zero 在输出可读性上存在明显缺陷,但这个”缺陷”本身可能恰恰印证了其思维方式的独特性。就像一个天才儿童发明了自己的解题方法,却难以用常规语言解释一样。这提示我们:真正的通用人工智能可能需要完全不同于人类的认知方式。这才是真正的强化学习。就像著名教育家皮亚杰的理论:真正的理解来自于主动建构,而不是被动接受。
DeepSeek-R1
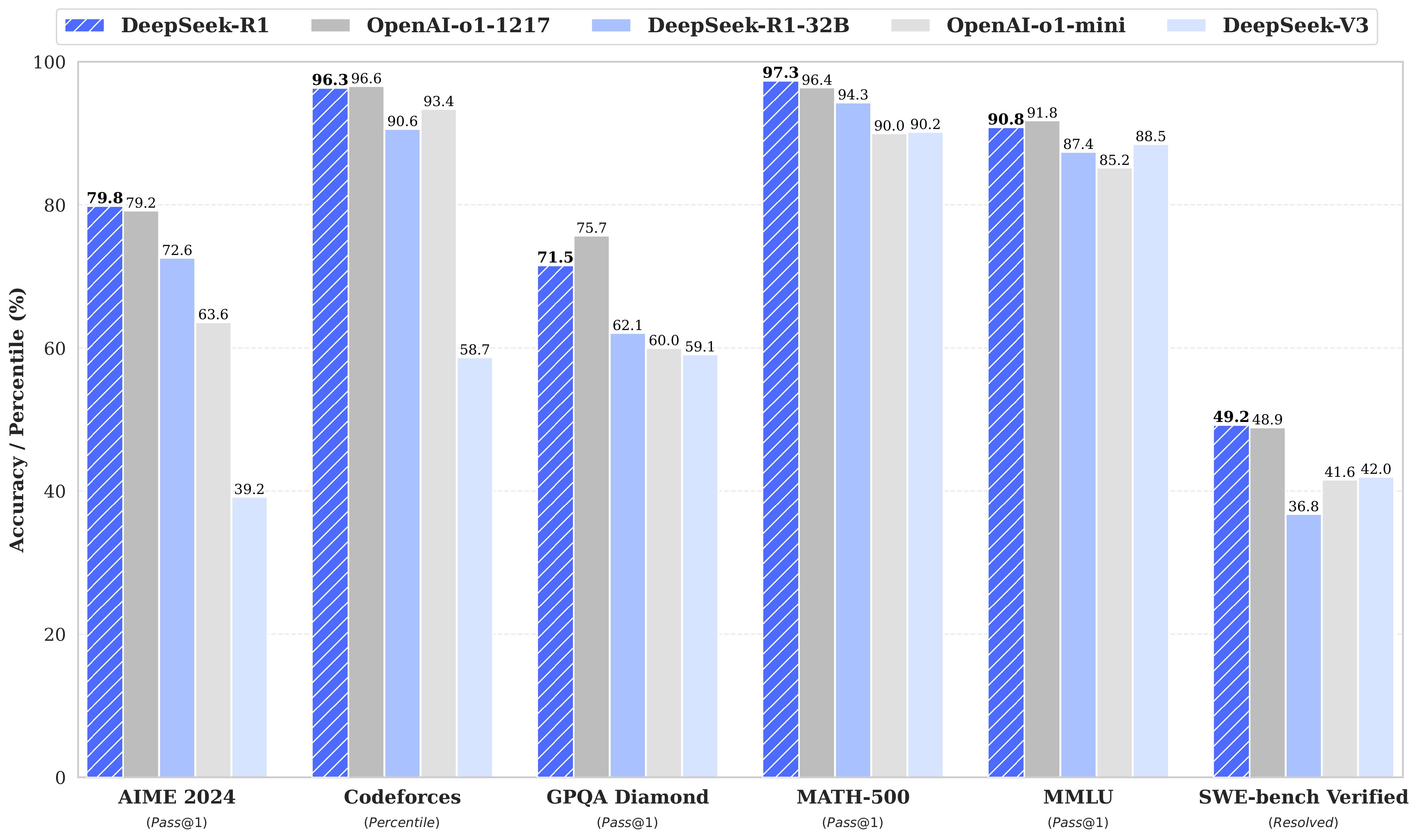
We introduce our first-generation reasoning models, DeepSeek-R1-Zero and DeepSeek-R1. DeepSeek-R1-Zero, a model trained via large-scale reinforcement learning (RL) without supervised fine-tuning (SFT) as a preliminary step, demonstrated remarkable performance on reasoning. With RL, DeepSeek-R1-Zero naturally emerged with numerous powerful and interesting reasoning behaviors. However, DeepSeek-R1-Zero encounters challenges such as endless repetition, poor readability, and language mixing. To address these issues and further enhance reasoning performance, we introduce DeepSeek-R1, which incorporates cold-start data before RL. DeepSeek-R1 achieves performance comparable to OpenAI-o1 across math, code, and reasoning tasks. To support the research community, we have open-sourced DeepSeek-R1-Zero, DeepSeek-R1, and six dense models distilled from DeepSeek-R1 based on Llama and Qwen. DeepSeek-R1-Distill-Qwen-32B outperforms OpenAI-o1-mini across various benchmarks, achieving new state-of-the-art results for dense models.
DeepSeek-R1-Zero 是一个通过大规模强化学习(RL)训练的模型,没有进行监督微调(SFT)作为预备步骤。这个模型在推理方面表现出了显著的性能。通过RL,DeepSeek-R1-Zero 自然地展现出了许多强大且有趣的推理行为。然而,DeepSeek-R1-Zero 也遇到了一些挑战,如无尽的重复、可读性差和语言混淆等问题。
为了解决这些问题并进一步提高推理性能,他们引入了 DeepSeek-R1,这个模型在RL之前引入了冷启动数据。DeepSeek-R1 在数学、编码和推理任务上的性能与 OpenAI-o1 相当。
为了支持研究社区,他们已经开源了 DeepSeek-R1-Zero、DeepSeek-R1 以及从 DeepSeek-R1 中提炼出的六个基于 Llama 和 Qwen 的密集模型。其中,DeepSeek-R1-Distill-Qwen-32B 在各种基准测试中的表现超过了 OpenAI-o1-mini,为密集模型创造了新的最佳结果。
NOTE: Before running DeepSeek-R1 series models locally, we kindly recommend reviewing the Usage Recommendation section.
Usage Recommendations
We recommend adhering to the following configurations when utilizing the DeepSeek-R1 series models, including benchmarking, to achieve the expected performance:
- Set the temperature within the range of 0.5-0.7 (0.6 is recommended) to prevent endless repetitions or incoherent outputs.
- Avoid adding a system prompt; all instructions should be contained within the user prompt.
- For mathematical problems, it is advisable to include a directive in your prompt such as: “Please reason step by step, and put your final answer within \boxed{}.”
- When evaluating model performance, it is recommended to conduct multiple tests and average the results.
Additionally, we have observed that the DeepSeek-R1 series models tend to bypass thinking pattern (i.e., outputting “
Chat Website & API Platform
You can chat with DeepSeek-R1 on DeepSeek’s official website: chat.deepseek.com, and switch on the button “DeepThink”
We also provide OpenAI-Compatible API at DeepSeek Platform: platform.deepseek.com

How to Run Locally
Please visit DeepSeek-V3 repo for more information about running DeepSeek-R1 locally.
DeepSeek-V3
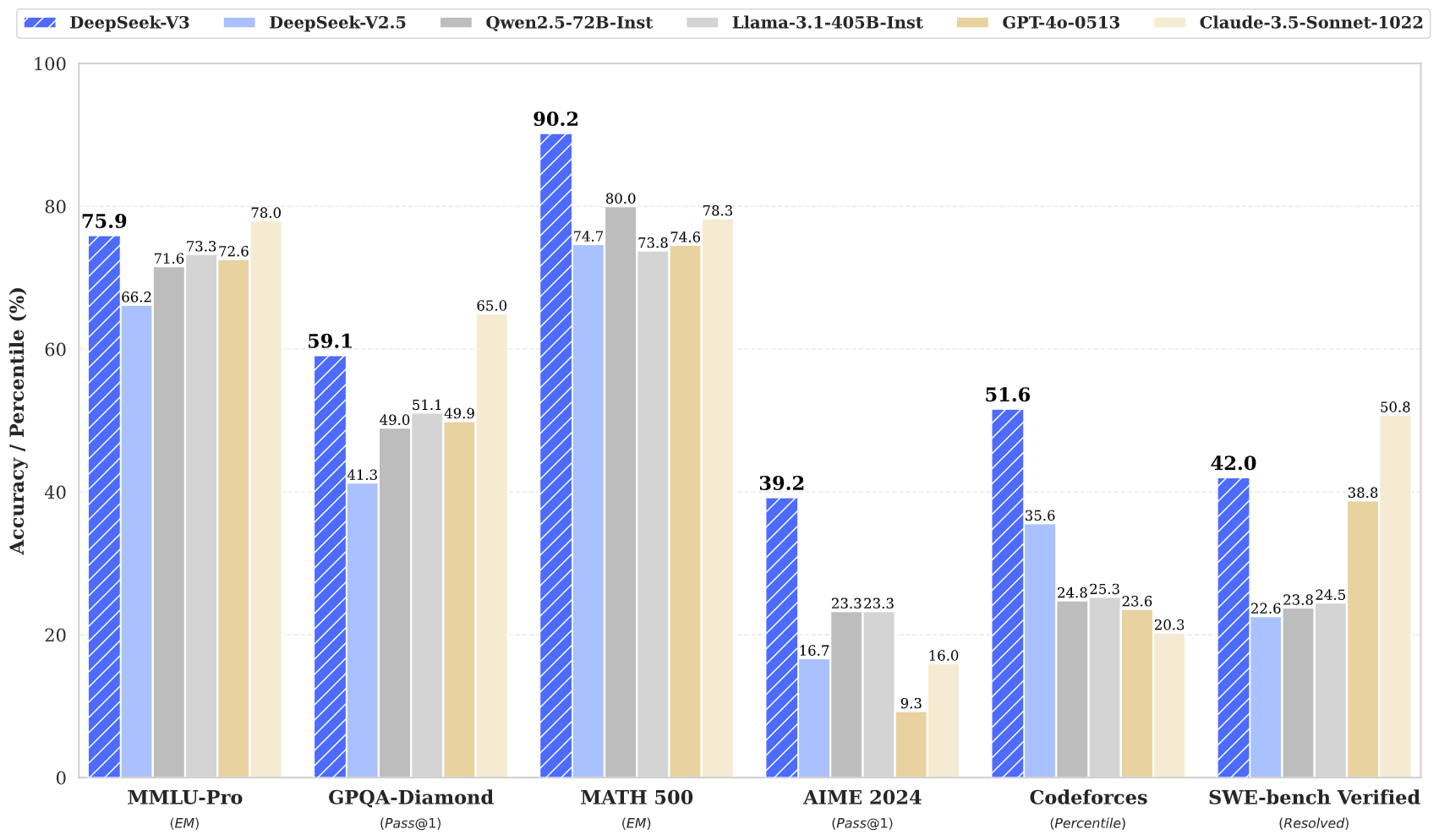
We present DeepSeek-V3, a strong Mixture-of-Experts (MoE) language model with 671B total parameters with 37B activated for each token. To achieve efficient inference and cost-effective training, DeepSeek-V3 adopts Multi-head Latent Attention (MLA) and DeepSeekMoE architectures, which were thoroughly validated in DeepSeek-V2. Furthermore, DeepSeek-V3 pioneers an auxiliary-loss-free strategy for load balancing and sets a multi-token prediction training objective for stronger performance. We pre-train DeepSeek-V3 on 14.8 trillion diverse and high-quality tokens, followed by Supervised Fine-Tuning and Reinforcement Learning stages to fully harness its capabilities. Comprehensive evaluations reveal that DeepSeek-V3 outperforms other open-source models and achieves performance comparable to leading closed-source models. Despite its excellent performance, DeepSeek-V3 requires only 2.788M H800 GPU hours for its full training. In addition, its training process is remarkably stable. Throughout the entire training process, we did not experience any irrecoverable loss spikes or perform any rollbacks.
DeepSeek-V3 是一个强大的专家混合(Mixture-of-Experts,MoE)语言模型,总共有671B(即6710亿)个参数,每个标记(token)激活了37B(即370亿)个参数。为了实现高效的推理和经济有效的训练,DeepSeek-V3 采用了多头潜在注意力(Multi-head Latent Attention,MLA)和DeepSeekMoE架构,这些都在 DeepSeek-V2 中得到了充分的验证。
此外,DeepSeek-V3 首次引入了一个无辅助损失的策略进行负载均衡,并设定了一个多标记预测训练目标以提高性能。我们在14.8万亿个多样化和高质量的标记上预训练了 DeepSeek-V3,然后进行了监督微调和强化学习阶段,以充分发挥其能力。
全面的评估显示,DeepSeek-V3 的性能超过了其他开源模型,并与领先的闭源模型相当。尽管 DeepSeek-V3 的性能出色,但其完全训练只需要2.788M H800 GPU小时。此外,其训练过程非常稳定。在整个训练过程中,我们没有遇到任何无法恢复的损失峰值,也没有进行任何回滚操作。
Chat Website & API Platform
You can chat with DeepSeek-V3 on DeepSeek’s official website: chat.deepseek.com
We also provide OpenAI-Compatible API at DeepSeek Platform: platform.deepseek.com
How to Run Locally
DeepSeek-V3 can be deployed locally using the following hardware and open-source community software:
…
快速使用 Deepseek-R1 模型
DeepSeek-R1 在后训练阶段大规模使用了强化学习技术,在仅有极少标注数据的情况下,极大提升了模型推理能力。在数学、代码、自然语言推理等任务上,性能比肩 OpenAI o1 正式版。通过腾讯云高性能应用服务 HAI 更易用的 GPU 智算服务可快速体验 Deepseek 模型的推理能力。HAI 已提供 DeepSeek-R1 1.5B 及 7B 模型预装环境(DeepSeek-R1-Distill-Qwen-1.5B、DeepSeek-R1-Distill-Qwen-7B),用户可在 HAI 中快速启动,进行测试并接入业务。若有更大尺寸模型(14B、32B、70B)的使用需求,也可根据使用说明中的指引进行快速部署。可参考DeepSeek-R1 高性能应用服务 HAI 开箱即用
创建 Deepseek-R1 应用
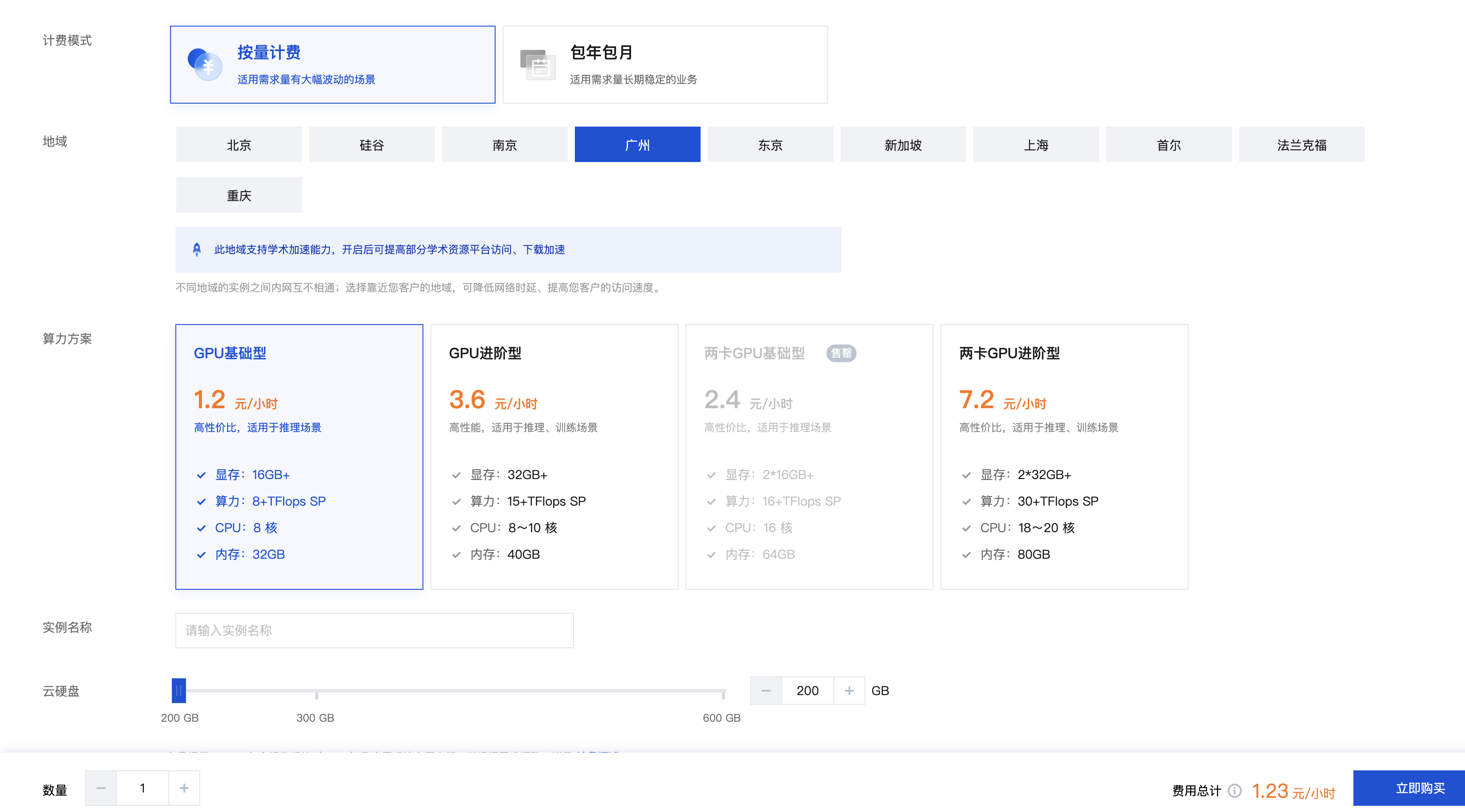
- 登录高性能应用服务 HAI 控制台。
- 单击新建,进入高性能应用服务 HAI 购买页面。
- 选择应用:选择社区应用,应用选择
Deepseek-R1。 - 地域:建议选择靠近自己实际地理位置的地域,降低网络延迟、提高您的访问速度。
- 算力方案:支持基础型及进阶型两类算力方案。
- 实例名称:自定义实例名称,若不填则默认使用实例 ID 替代。
- 购买数量:默认1台。
- 选择应用:选择社区应用,应用选择
- 单击立即购买。
- 核对配置信息后,单击提交订单,并根据页面提示完成支付。
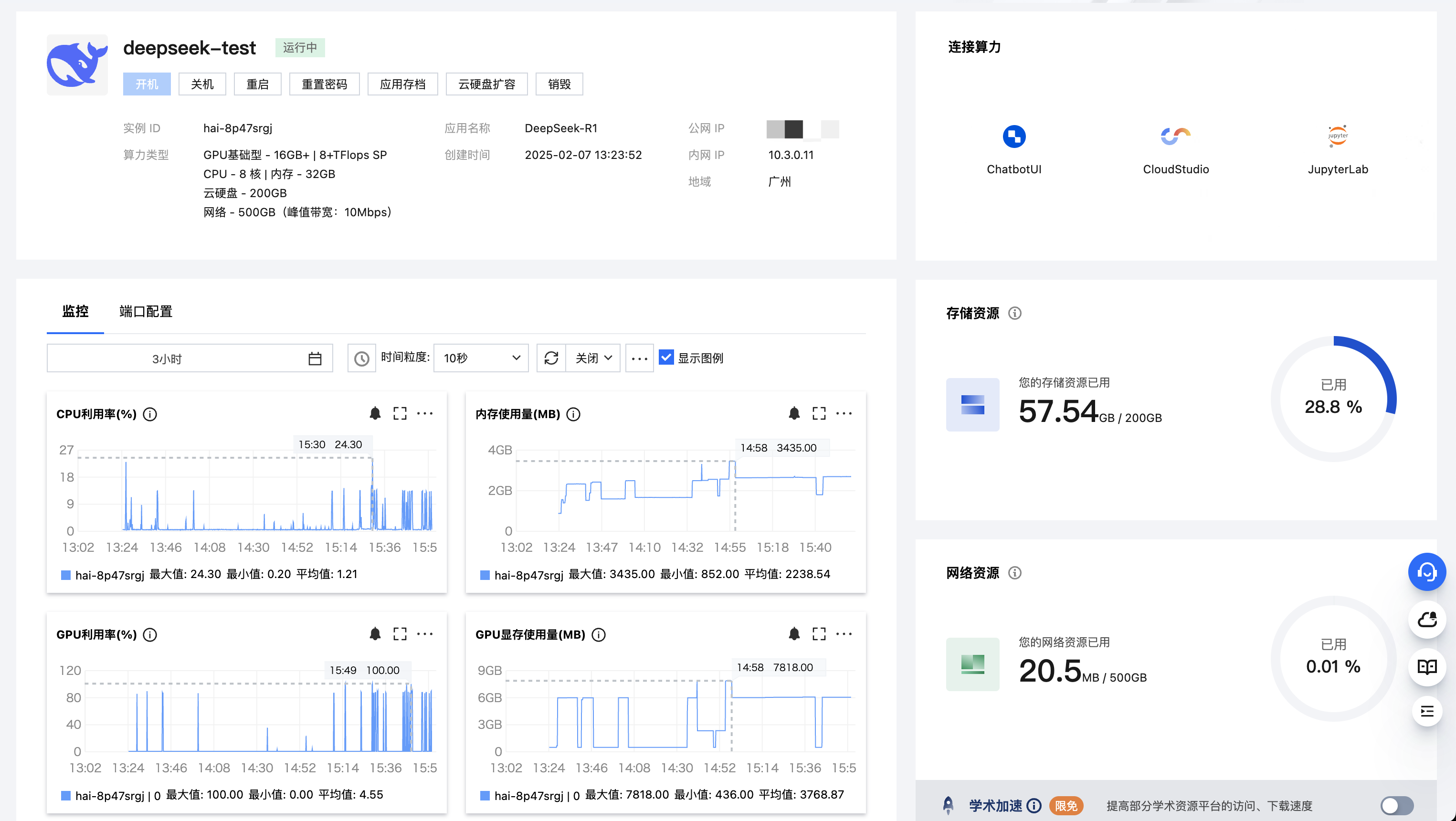
- 等待创建完成。单击实例任意位置并进入该实例的详情页面。
- 可以在此页面查看 Deepseek-R1 详细的配置信息,到此为止,说明 Deepseek-R1 应用实例购买成功。
使用 Deepseek-R1
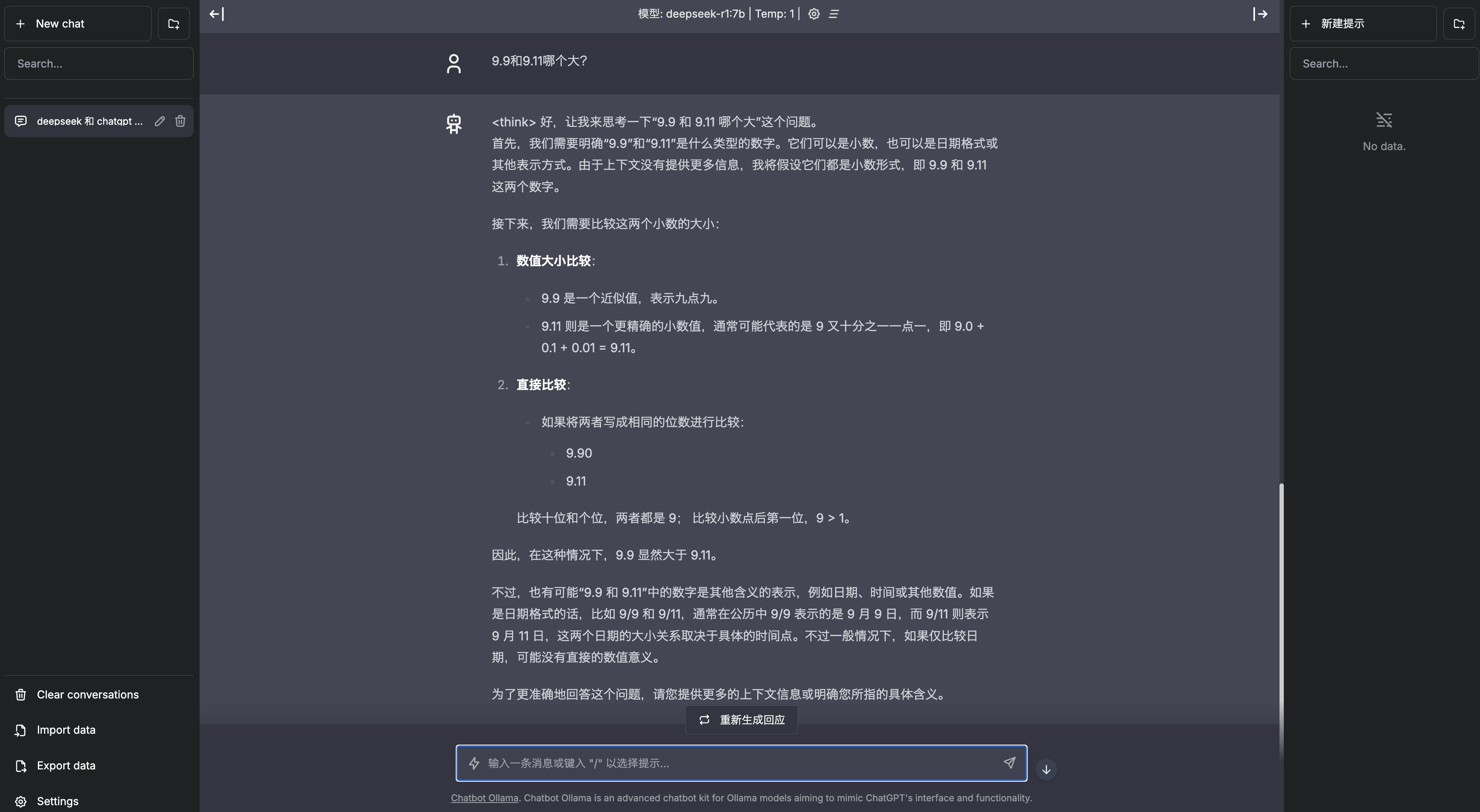
通过可视化界面使用
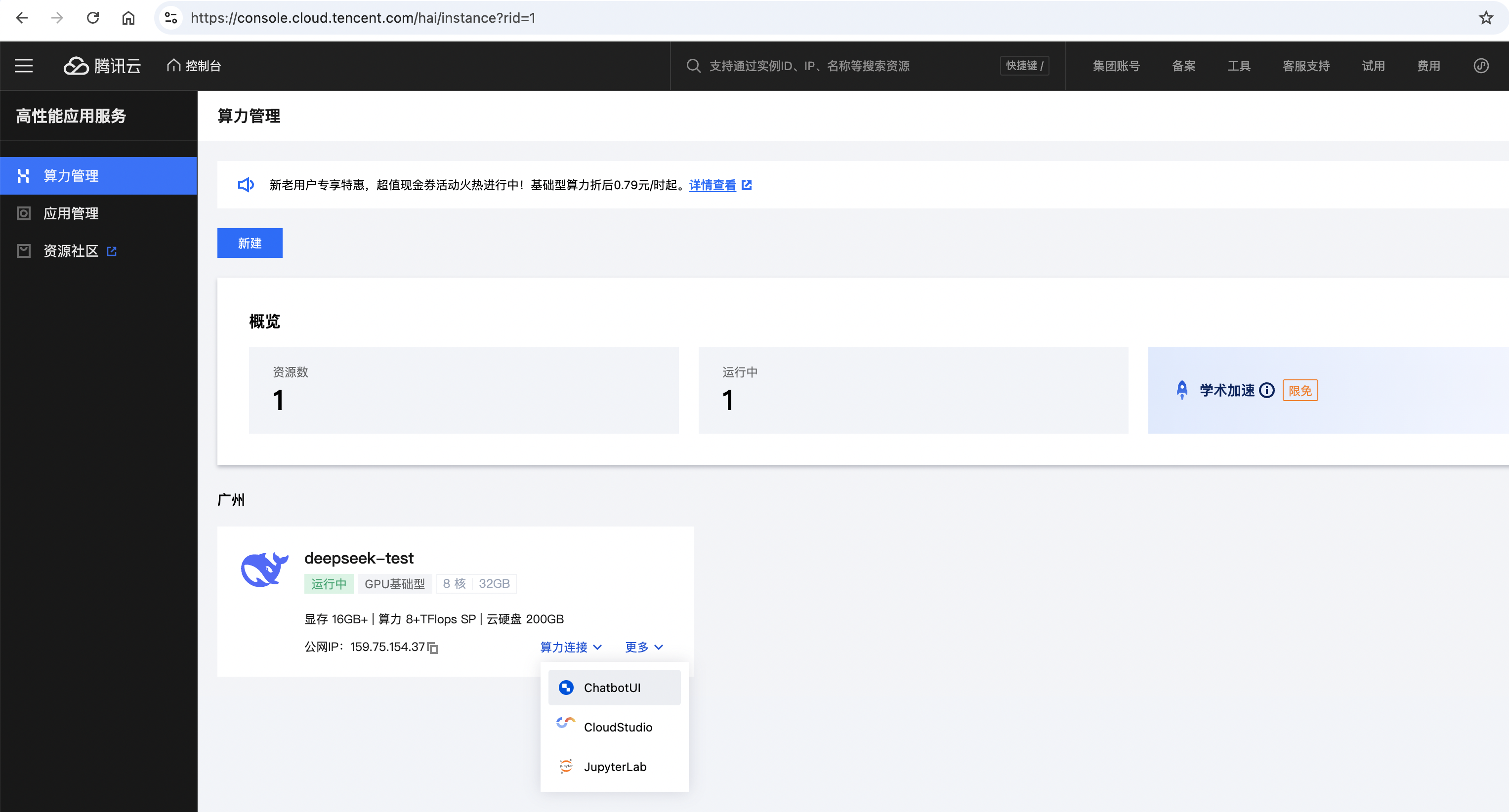
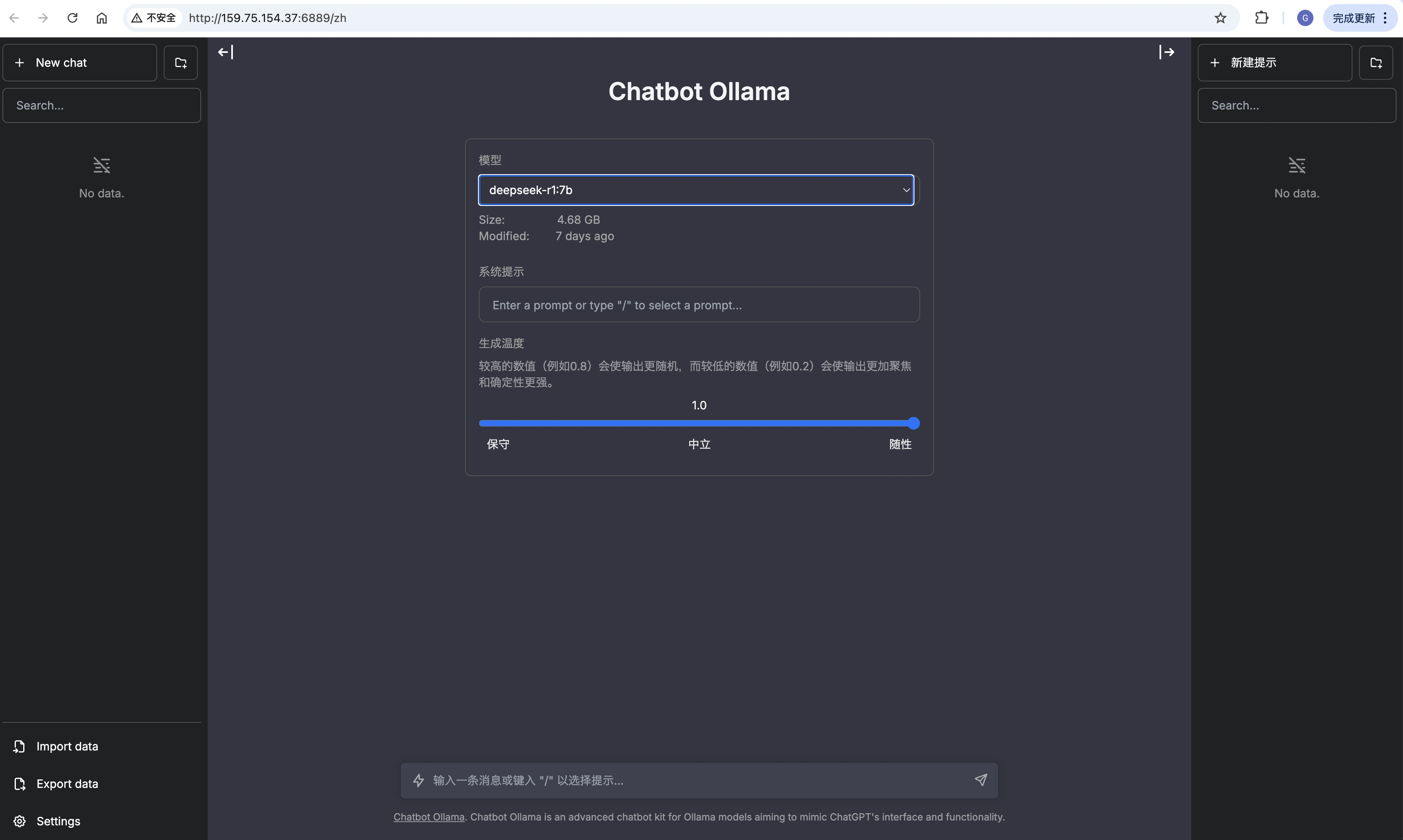
- 登录高性能应用服务 HAI 控制台,选择“算力连接” > “ChatbotUI”
- 在新窗口中,可以根据页面指引,完成与模型的交互。
通过命令行使用
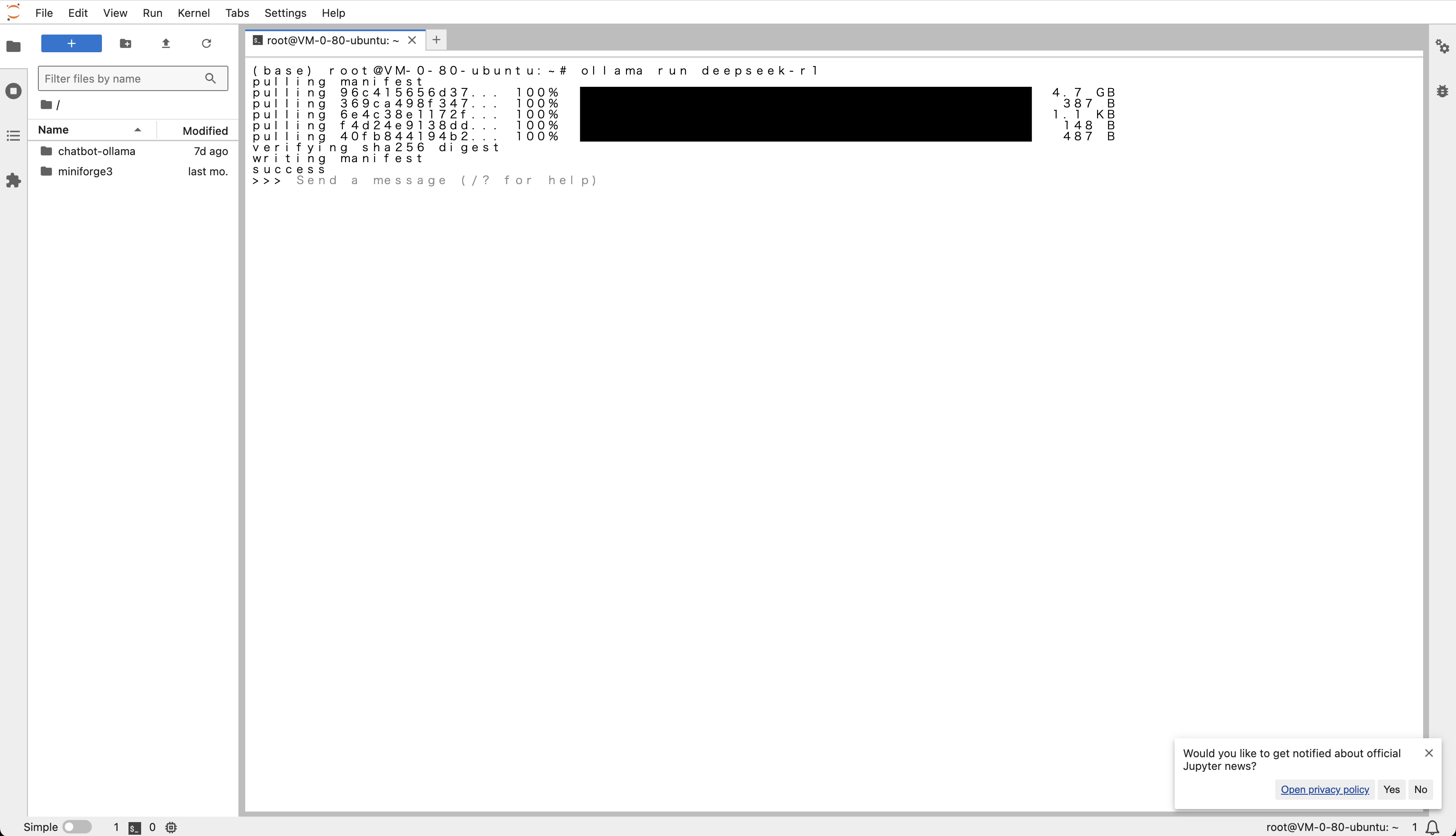
- 在高性能应用服务 HAI 控制台,选择“算力连接” > “JupyterLab”
- 新建一个 “Terminal”。
- 输入以下命令加载默认模型:
ollama run deepseek-r1 - 运行效果
Tips
切换不同参数量级
若默认的 1.5B 蒸馏模型无法满足需求,可通过以下命令自定义模型参数量级:
DeepSeek-R1-Distill-7B: ollama run deepseek-r1:7b
DeepSeek-R1-Distill-8B: ollama run deepseek-r1:8b
DeepSeek-R1-Distill-14B: ollama run deepseek-r1:14b
API 调用
实例环境中已预装并启动 Ollama serve,该服务支持通过 REST API 进行调用。可以参考 Ollama API 文档,以了解具体的调用方式和方法。
搭建个人知识库
Cherry Studio is a desktop client that supports for multiple LLM providers, available on Windows, Mac and Linux. Cherry Studio 是一个支持多模型服务的开源桌面客户端,可以将多服务集成至桌面 AI 对话应用中。
-
参考教程:https://docs.cherry-ai.com/advanced-basic/knowledge-base
-
下载 Cherry Studio:一款支持多个大语言模型(LLM)服务商的桌面客户端。
- 配置 API:进入设置界面,选择“模型服务”中的
Ollama,填写 API 地址及模型名称。- API 地址:将默认的 localhost 替换为 HAI 实例的公网 IP,将端口号由
11434修改为6399。 - 单击下方的“添加”按钮添加模型,模型 ID 输入
deepseek-r1:7b或deepseek-r1:1.5b
- API 地址:将默认的 localhost 替换为 HAI 实例的公网 IP,将端口号由
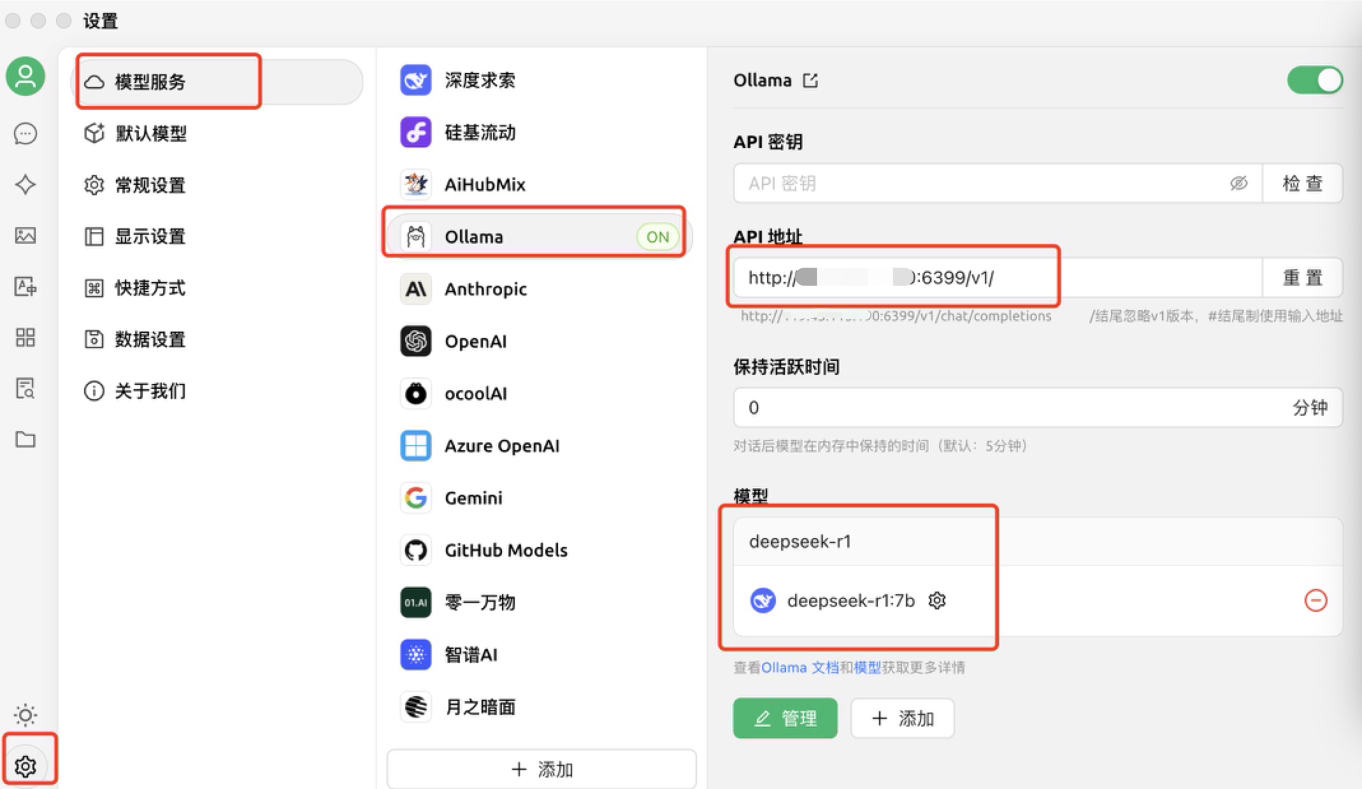
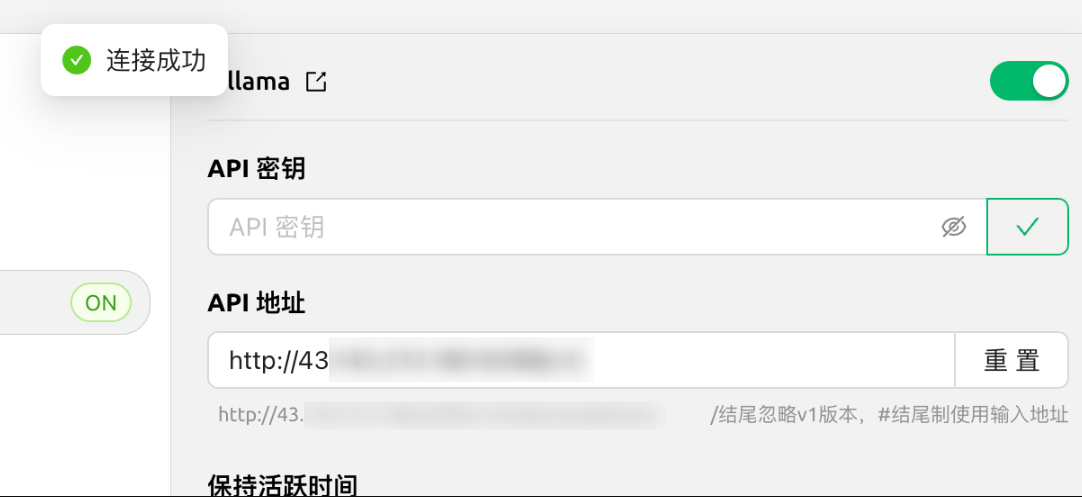
- 检查连通性:单击 API 密钥右侧的“检查”按钮,API 密钥不需填写,页面显示“连接成功”即可完成配置。
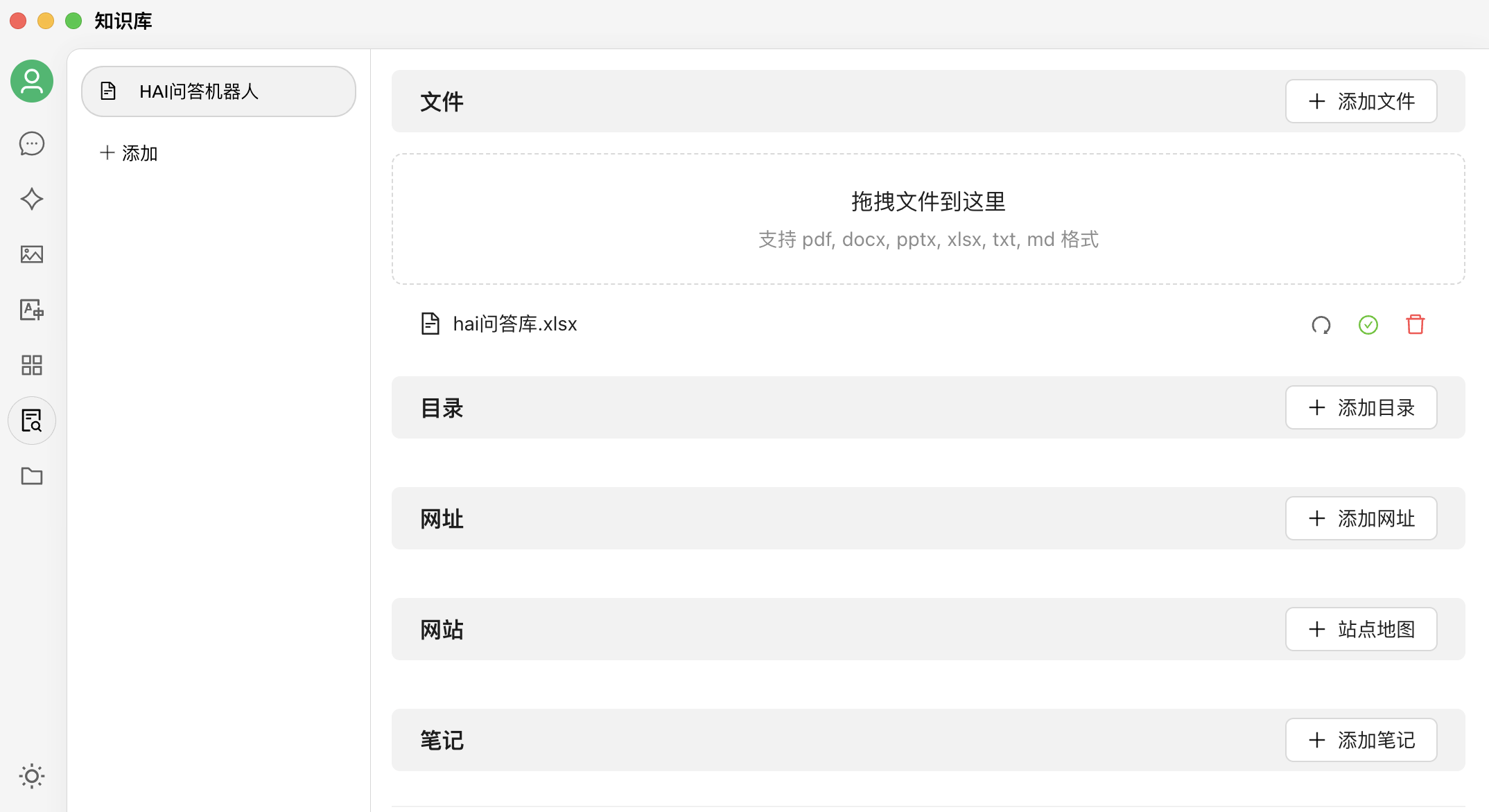
- 添加本地知识库文件并使用:完成 API 配置后,可在“知识库”模块中上传本地文件,并进入聊天界面进行使用。
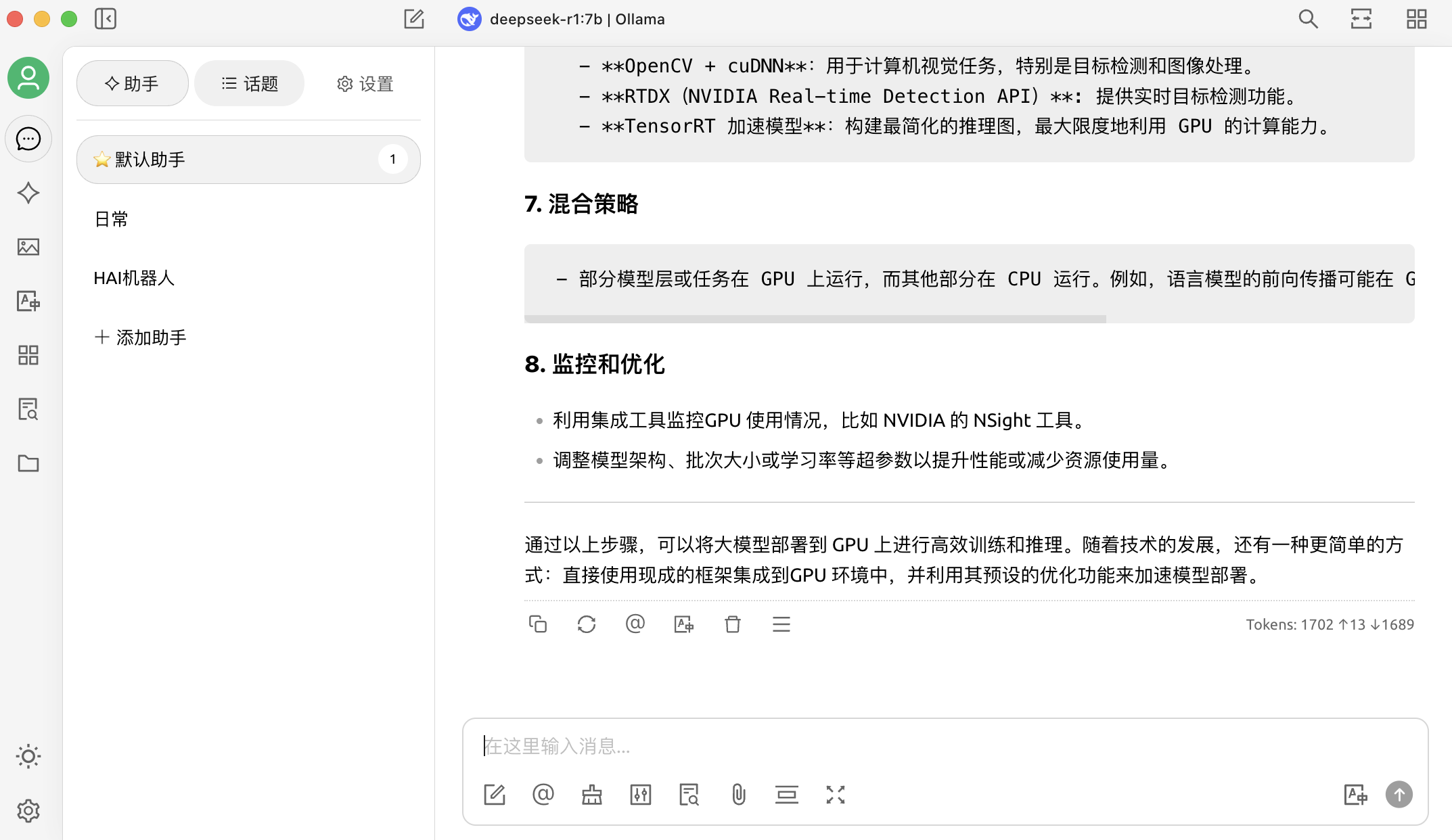
- 使用自己的 agent
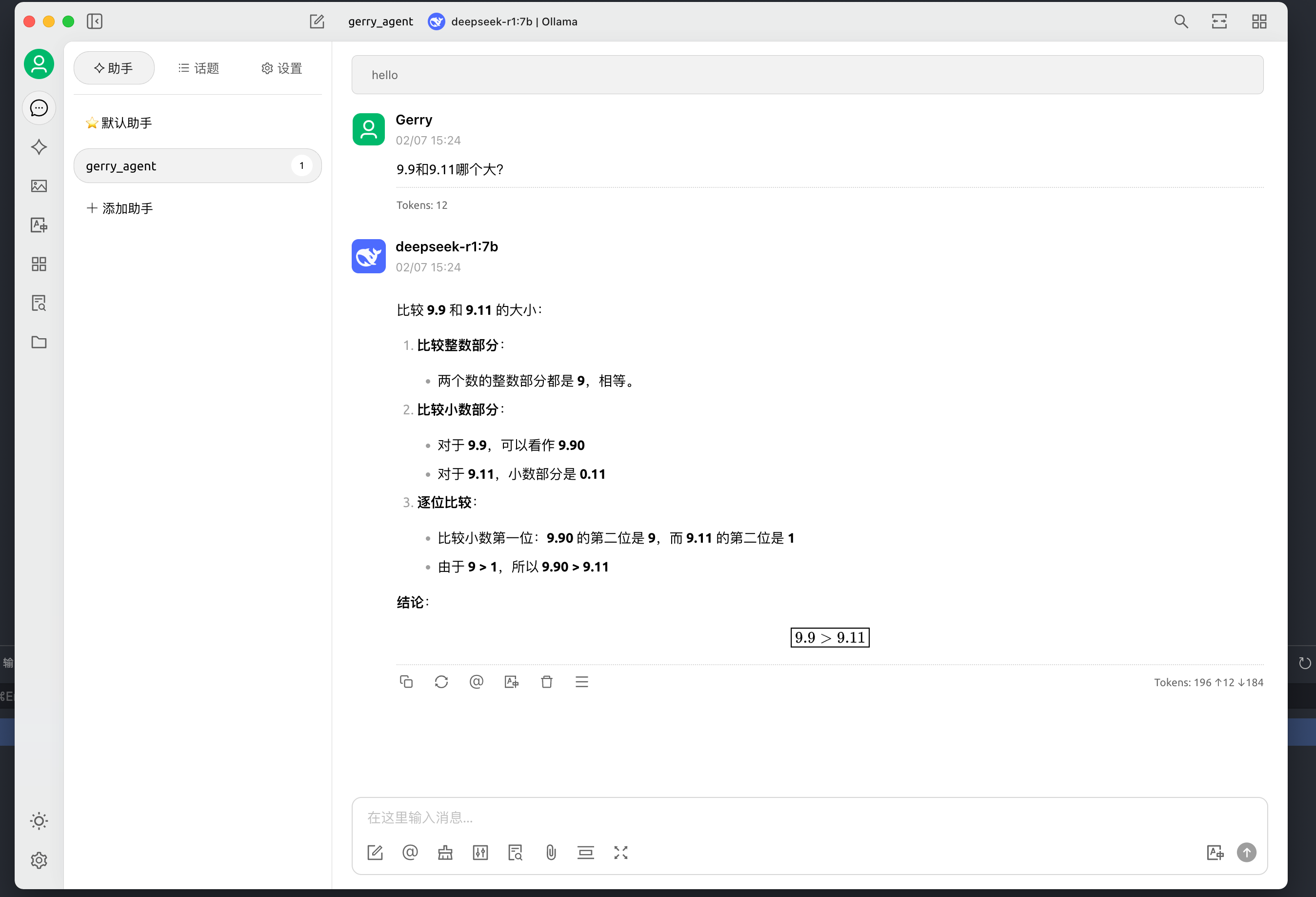
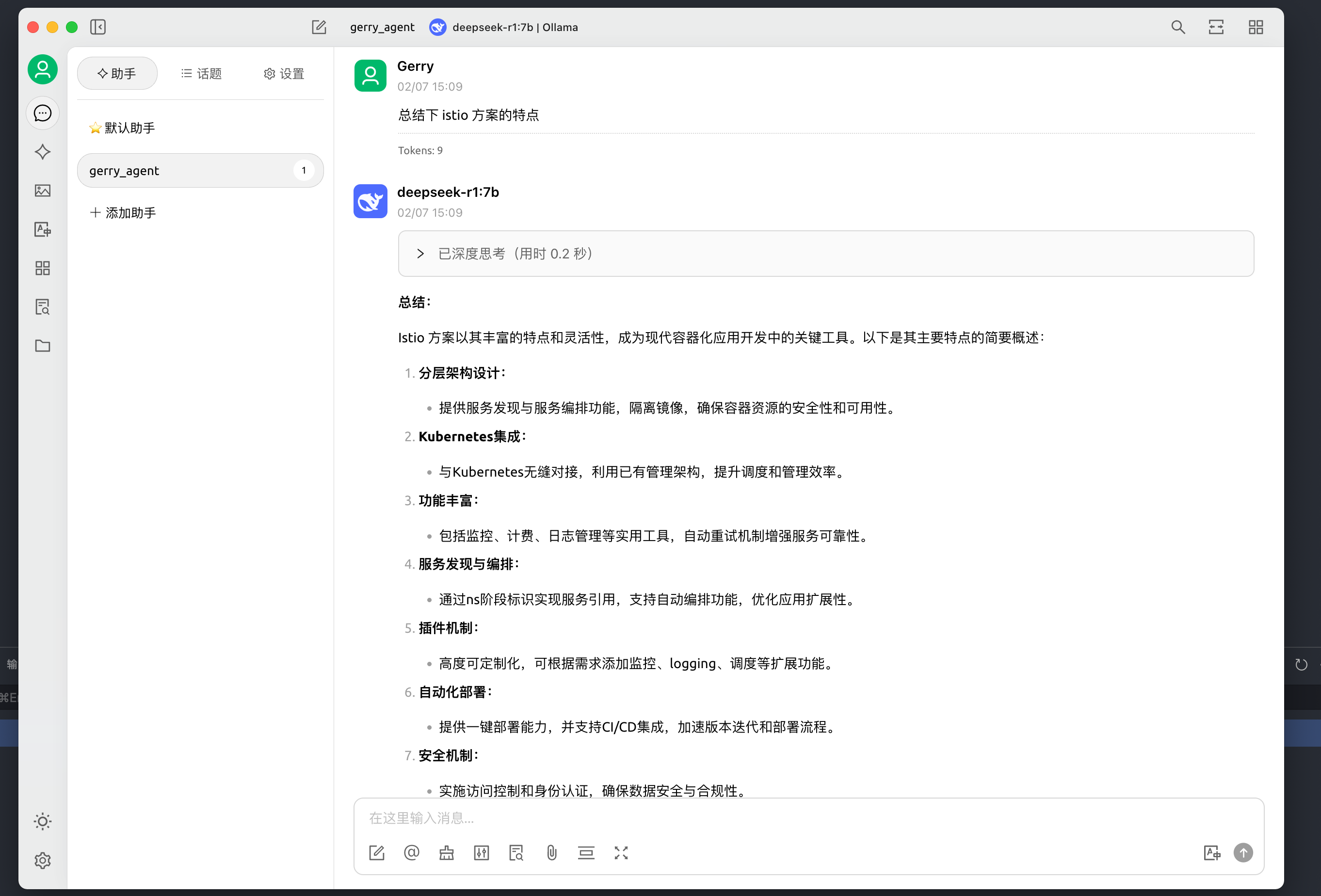
- 上传资料,搜索知识库 (搜索知识库,只有按匹配打分的排序)
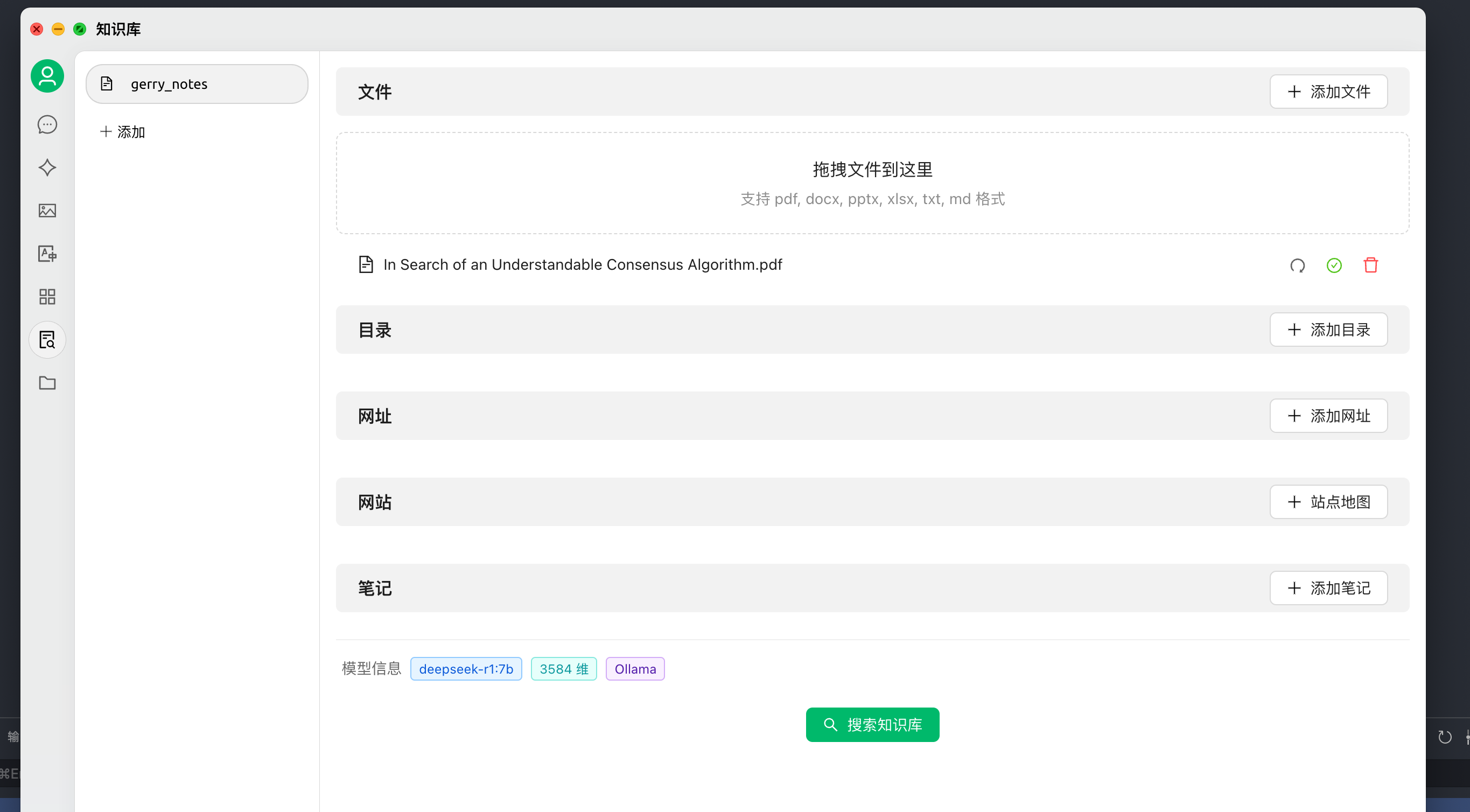
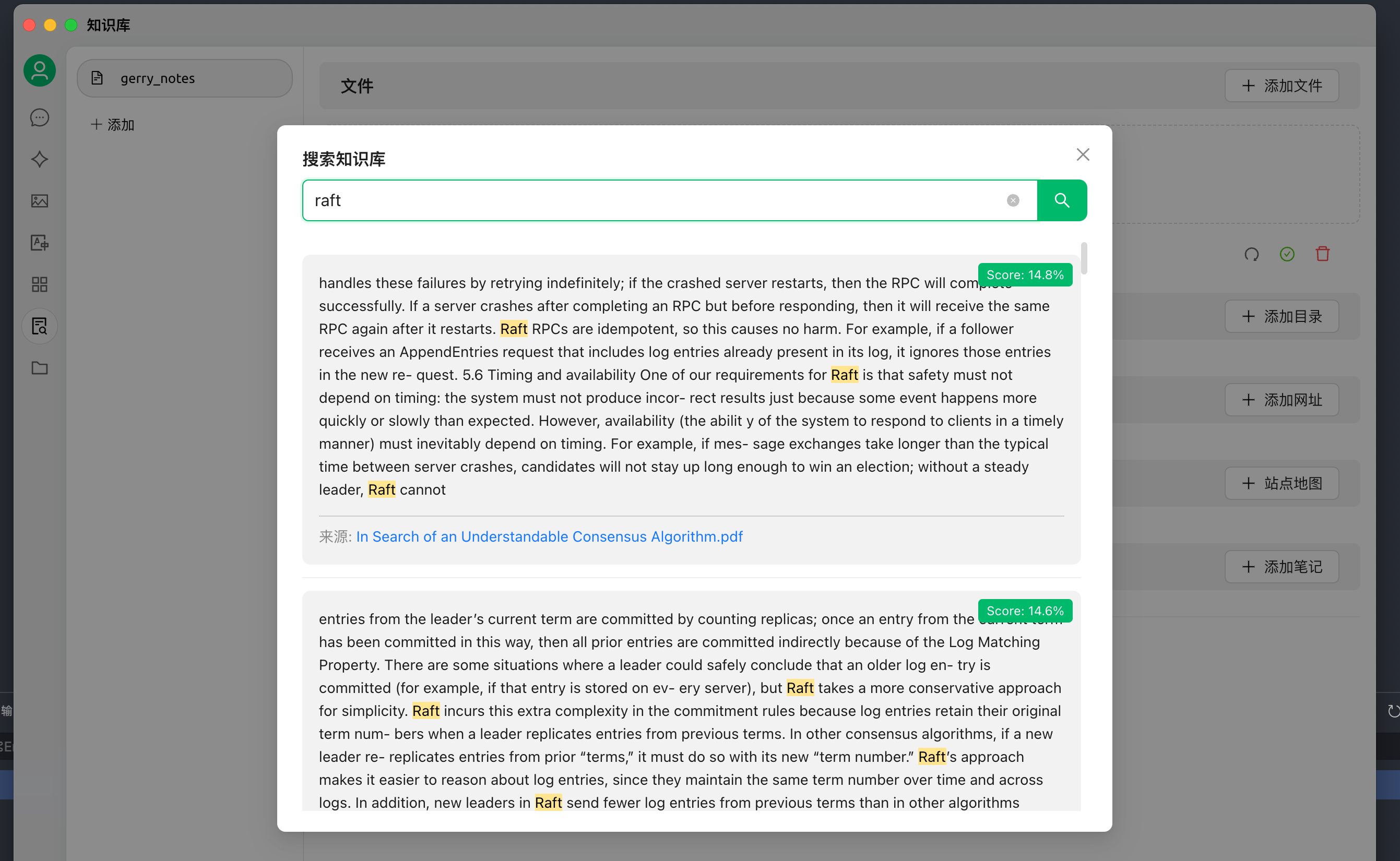
- 对话中引用知识库生成回复 (发现推理总结有时比较混乱)
- 创建一个新的话题,在对话工具栏中,点击知识库,会展开已经创建的知识库列表,选择需要引用的知识库;
- 输入并发送问题,模型即返回通过检索结果生成的答案;
- 同时,引用的数据来源会附在答案下方,可快捷查看源文件。
Q&A
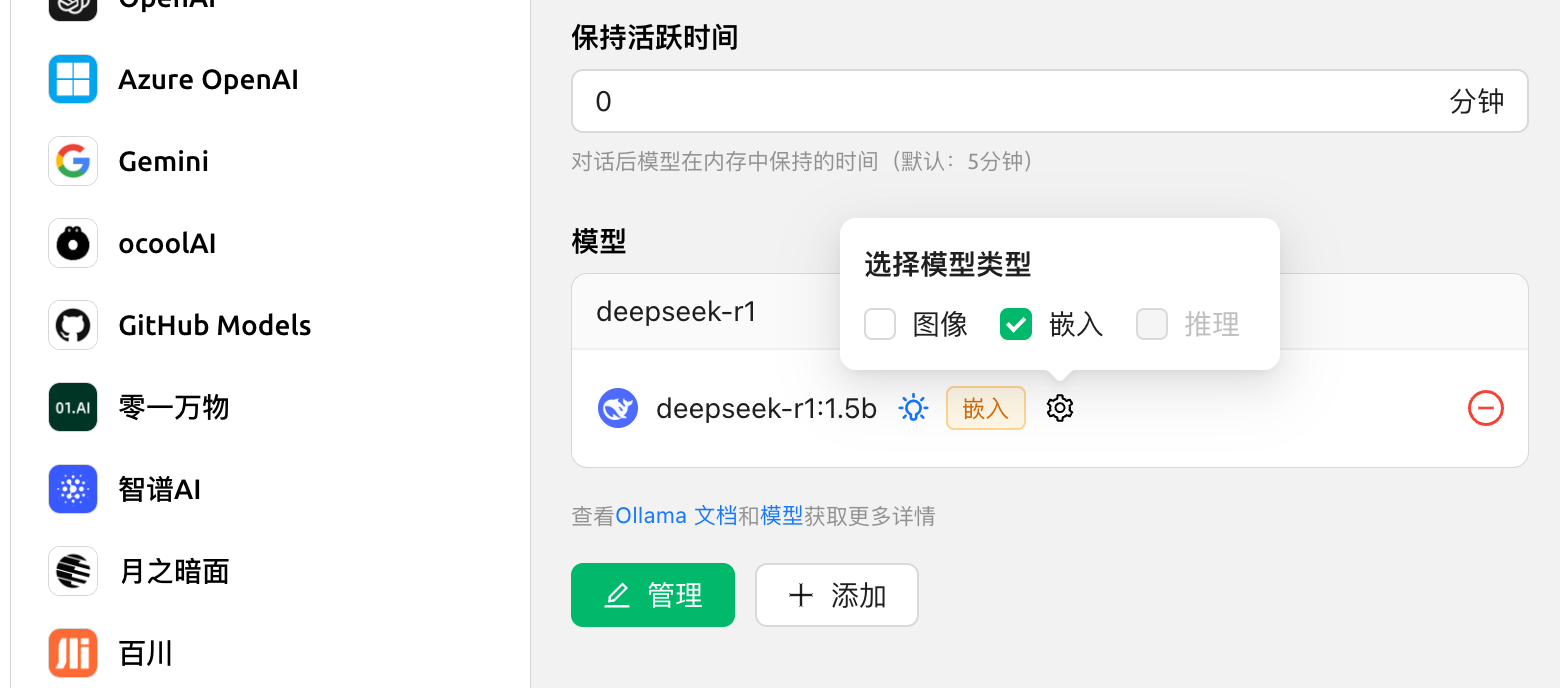
获取嵌入维度失败 #932
在模型服务中,选择 Ollama,将 deepseek-r1:1.5b 选择模型类型勾选:嵌入。
出错了,如果没有配置 API 密钥,请前往设置 > 模型提供商中配置密钥 #1027
选择自己的模型,并重置。
问题解释:https://docs.cherry-ai.com/advanced-basic/knowledge-base
注意:
嵌入类模型、对话类模型、绘画类模型等各自有各自的功能,其请求方式跟返回内容、结构都有所不同,请勿强行将其他类别的模型作为嵌入模型使用;
嵌入类模型 CherryStudio 会自动分类显示在嵌入模型列表中,如果确认为嵌入模型但未被正确分类,可到模型列表中点击对应模型后方的设置按钮勾选嵌入选项;如果无法确认哪些模型是嵌入模型可到对应服务商查询模型信息。
通过腾讯云 API 调用
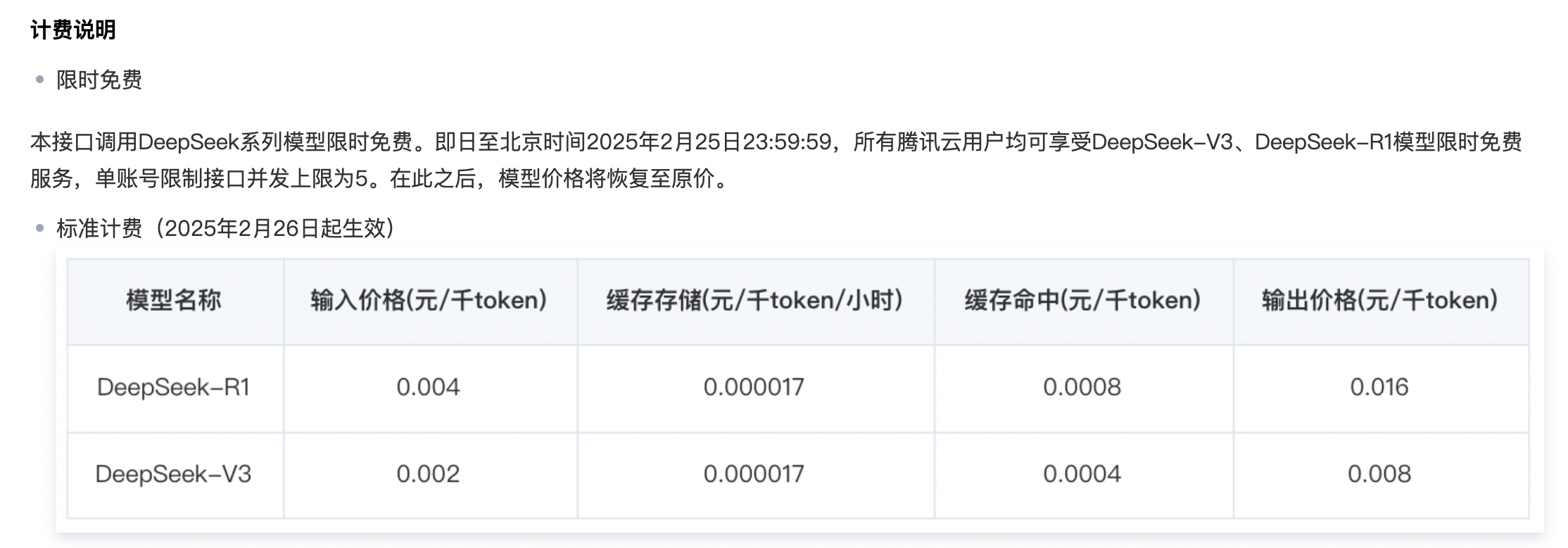
也可直接调用腾讯云上的 DeepSeek API,参考:获取 API 接口文档及费用说明
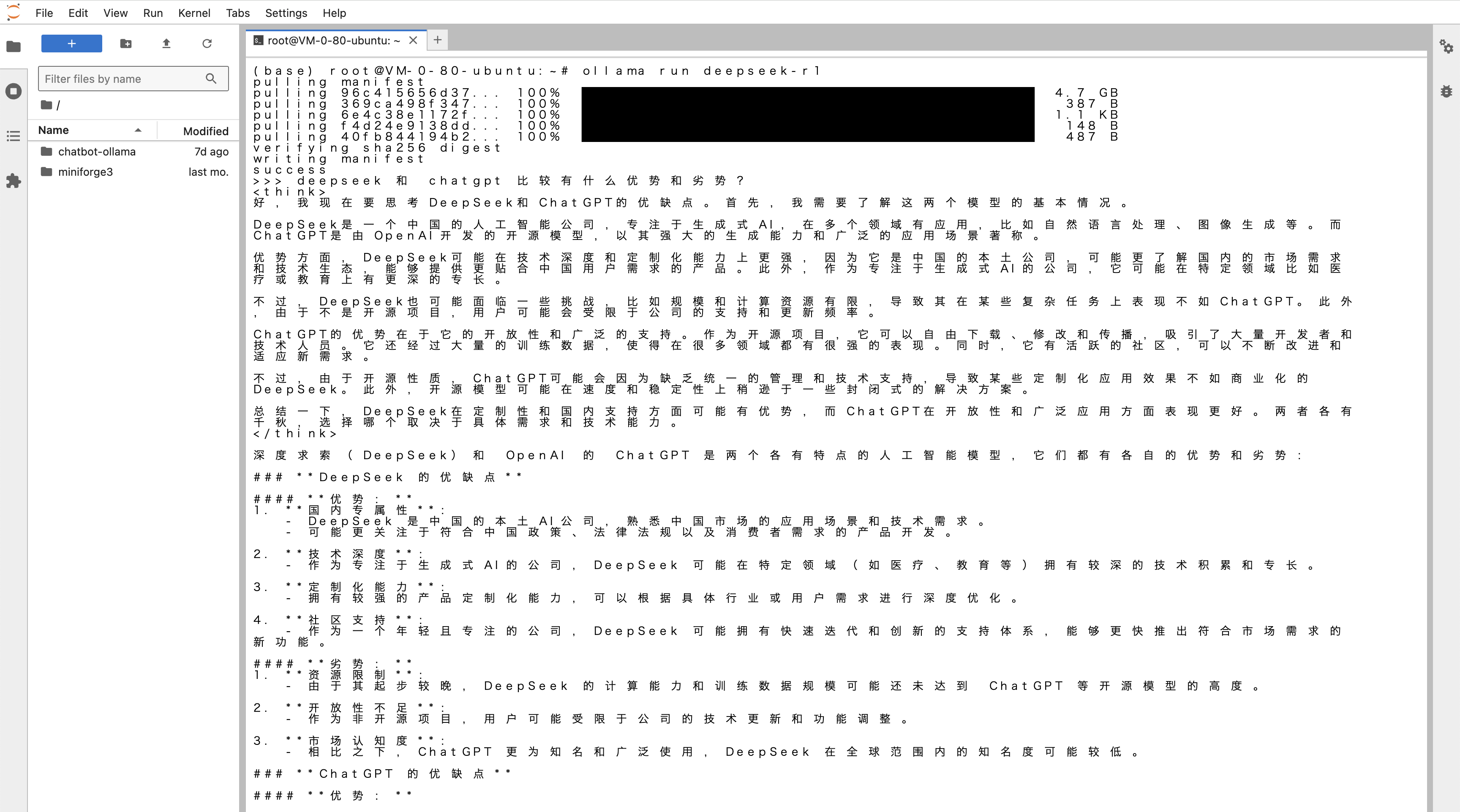
大小模型效果对比 (DeepSeek-R1-Distill-Qwen-1.5B VS. DeepSeek-R1)
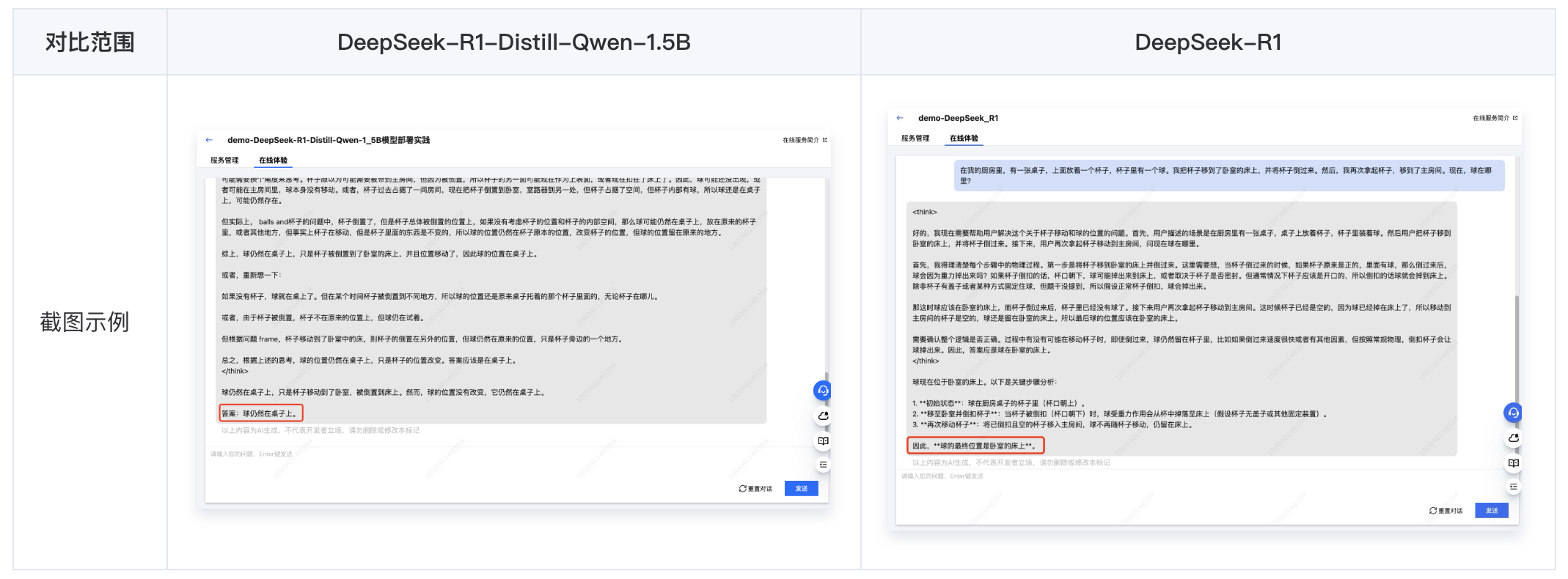
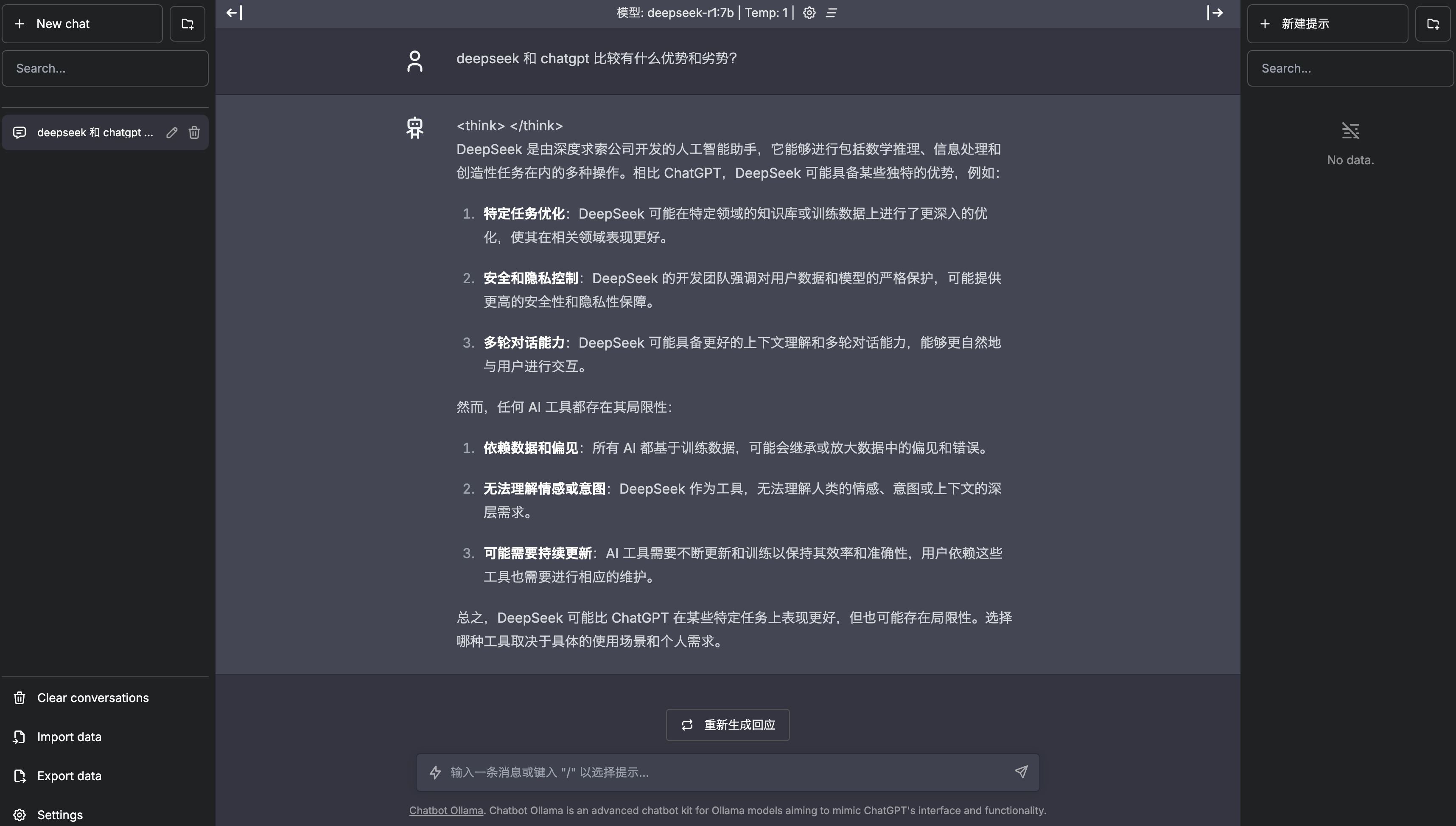
从响应结果中可以明显看出,拥有更大参数量的 DeepSeek-R1 模型在推理效果上更胜一筹,其正确推理出了杯子倒扣时球会掉出并留在床上,即使杯子随后被移动至房间。而参数量较小的 DeepSeek-R1-Distill-Qwen-1.5B 模型仍然认为球在杯中。
另一方面,相比 DeepSeek-R1 模型,更小参数的 DeepSeek-R1-Distill-Qwen-1.5B 模型的响应速度更快、占用资源更少、部署时长更短,在处理较为简单的任务时,仍是不错的选择。
其中,DeepSeek-R1-Distill-Qwen-1.5B 的部署时长预计为 1-2 分钟,DeepSeek-R1 预计为 9-10 分钟(模型需预加载到节点的本地数据盘中)。
由于 R1、V3 模型的参数量较大,其模型体积达到 641 GB,仅从平台存储加载到机器就需要相当长时间(达2小时以上),因此在模型未提前存储到机器的情况下,模型部署时间整体也会较长。
系列模型清单:
DeepSeek-V3
DeepSeek-R1
DeepSeek-R1-Distill-Qwen-1.5B
DeepSeek-R1-Distill-Qwen-7B
DeepSeek-R1-Distill-Llama-8B
DeepSeek-R1-Distill-Qwen-14B
DeepSeek-R1-Distill-Qwen-32B
DeepSeek-R1-Distill-Llama-70B
Tools
Ollama (本地部署 DeepSeek 模型)
Get up and running with large language models. Ollama 是一个开源工具,旨在帮助你在本地轻松运行和部署大型语言模型。
以下选择 macOS 版本,本地机器配置 Apple M1 Pro 32G 内存,下载 https://ollama.com/download/Ollama-darwin.zip 安装完成后:
~ ollama --version
ollama version is 0.5.7
~ ollama --help
Large language model runner
Usage:
ollama [flags]
ollama [command]
Available Commands:
serve Start ollama
create Create a model from a Modelfile
show Show information for a model
run Run a model
stop Stop a running model
pull Pull a model from a registry
push Push a model to a registry
list List models
ps List running models
cp Copy a model
rm Remove a model
help Help about any command
Flags:
-h, --help help for ollama
-v, --version Show version information
Use "ollama [command] --help" for more information about a command.
下载安装第一个模型:
# Run your first model
ollama run llama3.2
Ollama 支持的模型:Ollama supports a list of models available on ollama.com/library
| Model | Parameters | Size | Download |
|---|---|---|---|
| DeepSeek-R1 | 7B | 4.7GB | ollama run deepseek-r1 |
| DeepSeek-R1 | 671B | 404GB | ollama run deepseek-r1:671b |
| Llama 3.3 | 70B | 43GB | ollama run llama3.3 |
| Llama 3.2 | 3B | 2.0GB | ollama run llama3.2 |
| Llama 3.2 | 1B | 1.3GB | ollama run llama3.2:1b |
| Llama 3.2 Vision | 11B | 7.9GB | ollama run llama3.2-vision |
| Llama 3.2 Vision | 90B | 55GB | ollama run llama3.2-vision:90b |
| Llama 3.1 | 8B | 4.7GB | ollama run llama3.1 |
| Llama 3.1 | 405B | 231GB | ollama run llama3.1:405b |
| Phi 4 | 14B | 9.1GB | ollama run phi4 |
| Phi 3 Mini | 3.8B | 2.3GB | ollama run phi3 |
| Gemma 2 | 2B | 1.6GB | ollama run gemma2:2b |
| Gemma 2 | 9B | 5.5GB | ollama run gemma2 |
| Gemma 2 | 27B | 16GB | ollama run gemma2:27b |
| Mistral | 7B | 4.1GB | ollama run mistral |
| Moondream 2 | 1.4B | 829MB | ollama run moondream |
| Neural Chat | 7B | 4.1GB | ollama run neural-chat |
| Starling | 7B | 4.1GB | ollama run starling-lm |
| Code Llama | 7B | 3.8GB | ollama run codellama |
| Llama 2 Uncensored | 7B | 3.8GB | ollama run llama2-uncensored |
| LLaVA | 7B | 4.5GB | ollama run llava |
| Solar | 10.7B | 6.1GB | ollama run solar |

可以发现通过 Ollama 直接下载模型速度非常慢:

为了提高下载模型的速度,可以在 https://modelscope.cn/home 国内的代理服务下载所需的模型,这里测试下载 DeepSeek-R1-Distill-Qwen-7B-GGUF 模型。
ollama run modelscope.cn/unsloth/DeepSeek-R1-Distill-Qwen-7B-GGUF
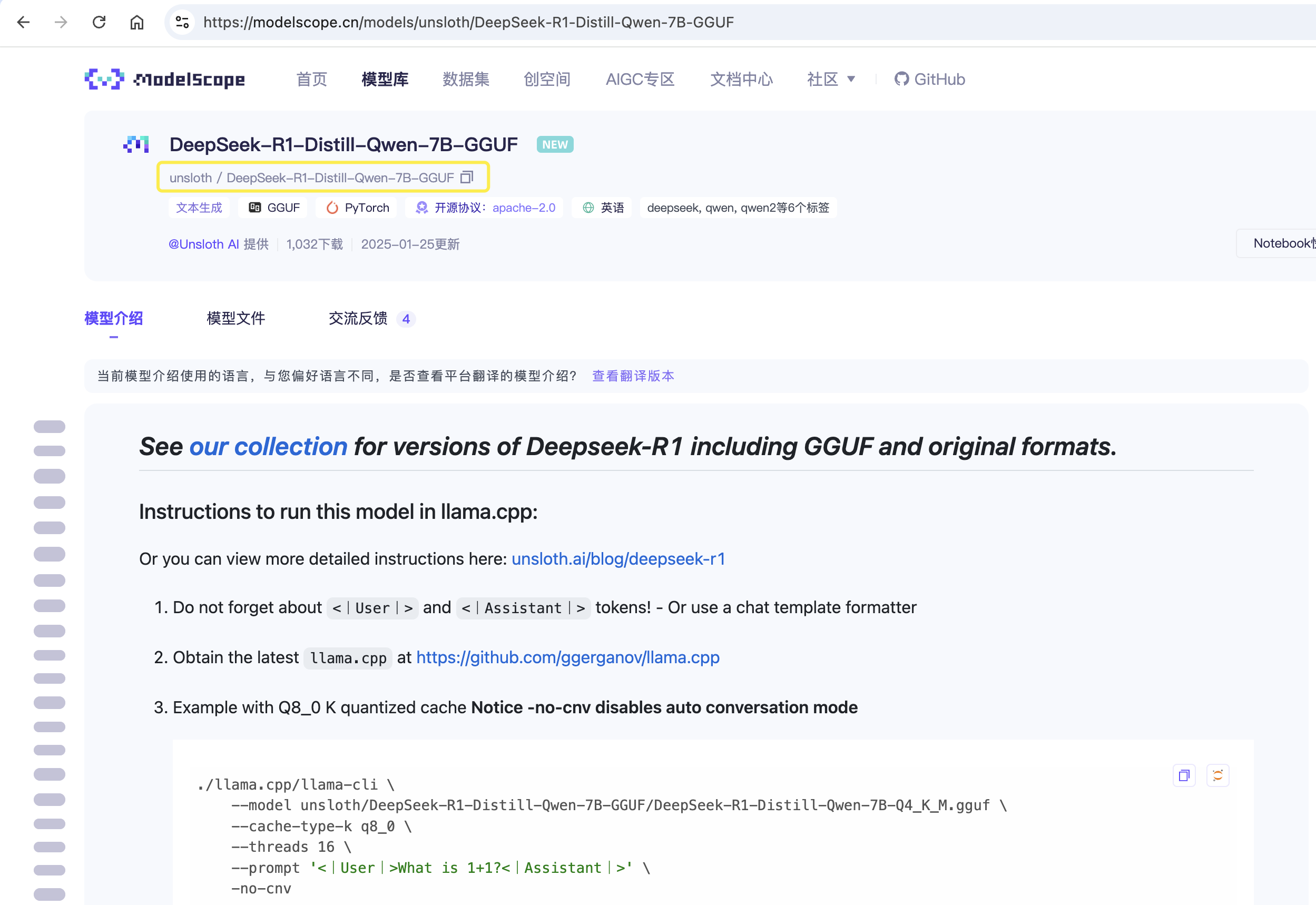

下载完成:
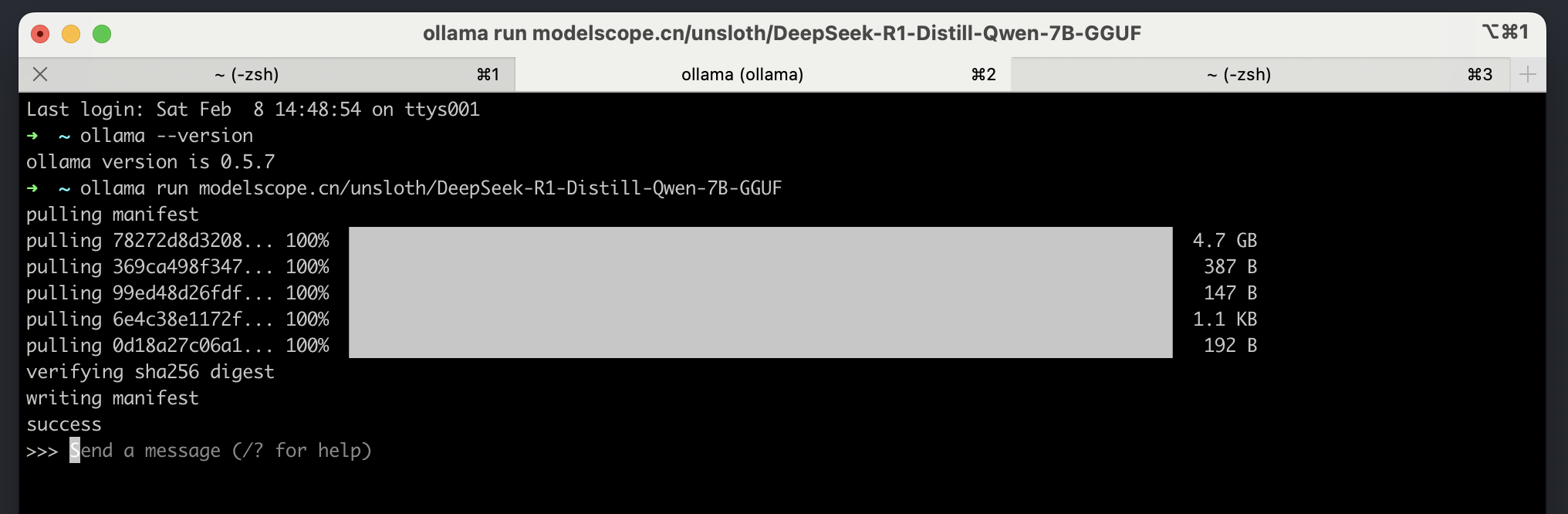

Ollama 空跑时资源开销:
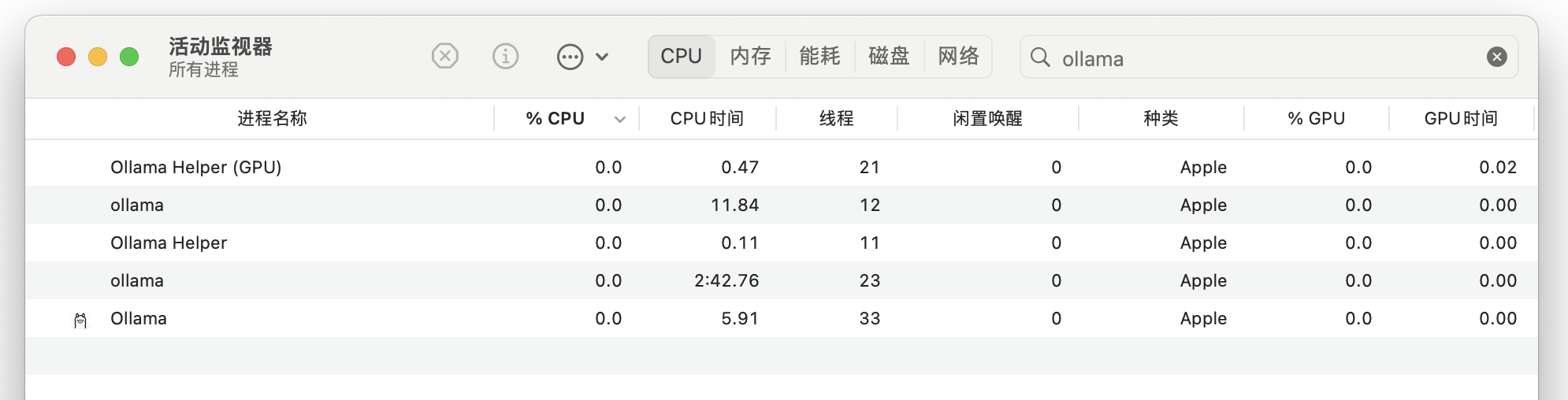
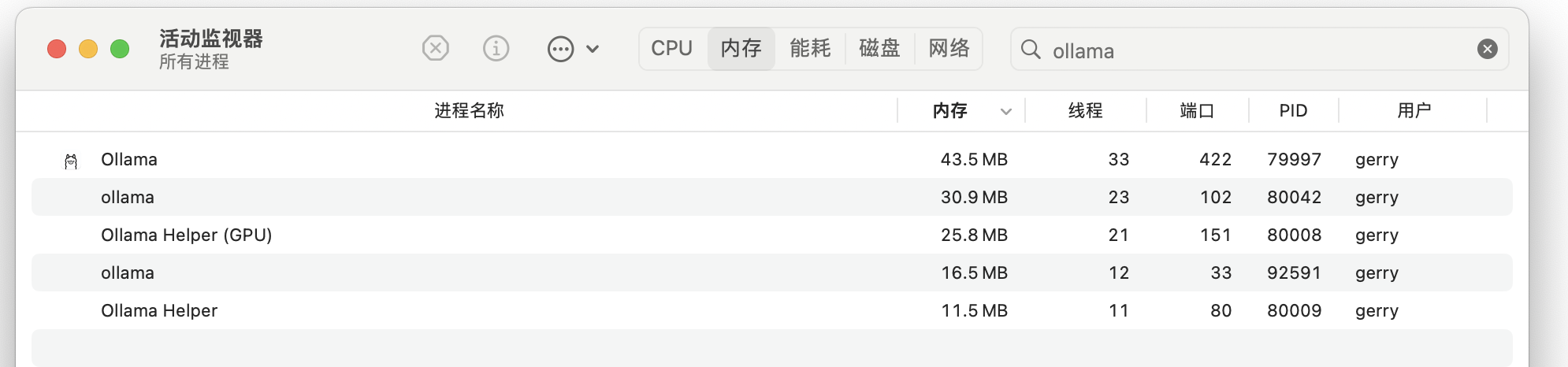
Ollama 推理时资源开销,GPU 跑了 100%。
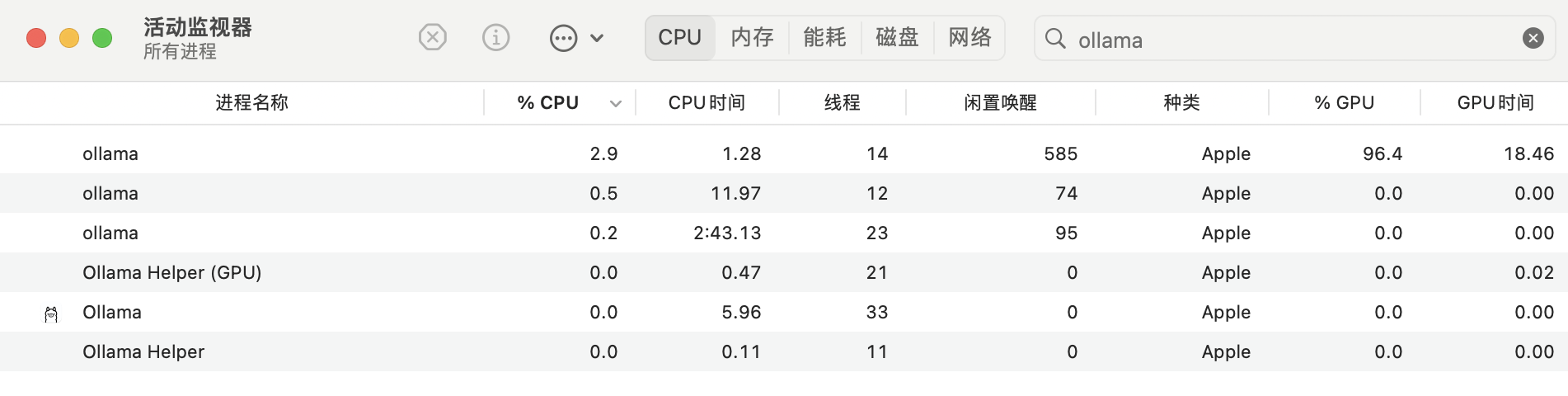
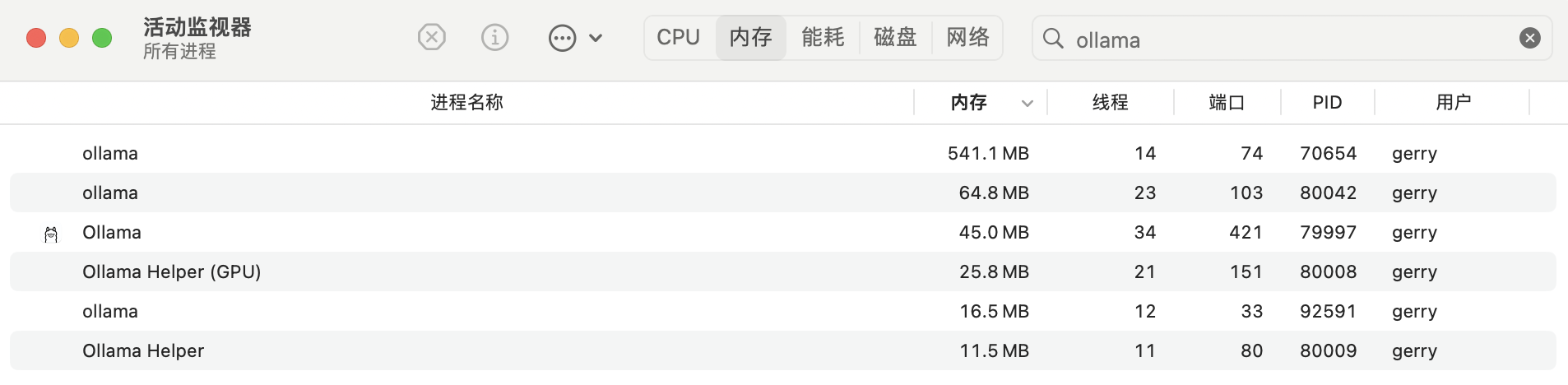
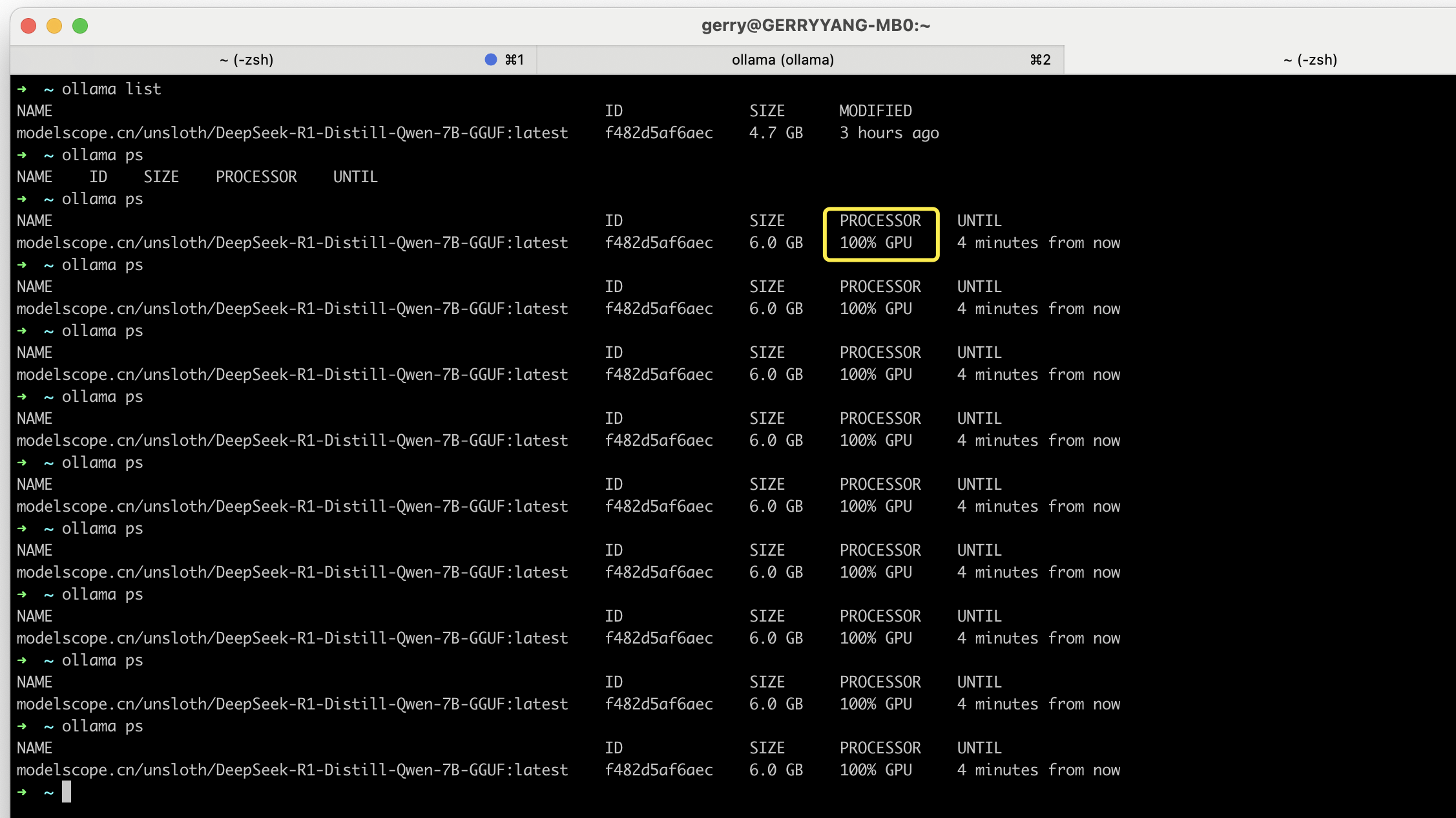
关于 Ollama 资源使用的一些说明:
- Low GPU / High CPU Utilization ==> Slow Performance #4668
- Why doesn’t Ollama use MORE RAM?
- How can I ensure ollama is using my GPU and RAM effectively?
- default num_thread incorrect on some large core count system (non-hyperthreading) #2496
其中一个解释:
I have tested Ollama on different machines yet, but no matter how many cores or RAM I have, it’s only using 50% of the cores and just a very few GB of RAM. For example now I’m running ollama rum llama2:70b on 16 core server with 32 GB of RAM, but while prompting only eight cores are used and just around 1 GB of RAM.
Is there something wrong? In the models descriptions are aleways warning you neet at least 8,16,32,… GB of RAM.
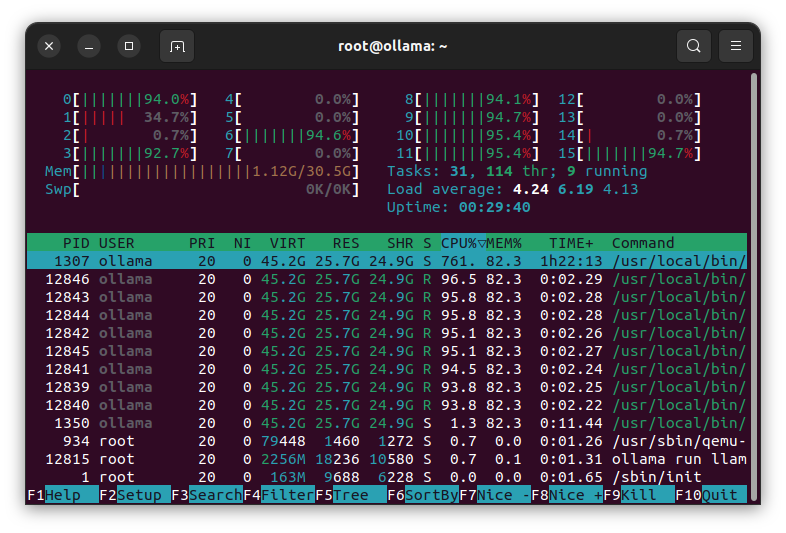
That’s fine & as expected.
Model data is memory mapped and shows up in file cache #. Note too, VIRT, RES & SHR memory # of the Ollama processes.
Generation is memory bandwidth limited, not compute limited. Saturation is generally achieved ~1/2 the number of virtual cores. Using more can actually hurt speeds and interferes unnecessarily with other processes.
首先,Ollama 模型的数据是内存映射的,这意味着模型的数据被存储在文件缓存中,而不是 RAM 中。因此,即使你的系统有大量的 RAM,Ollama 也只会使用一小部分 RAM。这就解释了为什么 Ollama 只使用了大约 1GB 的 RAM。
其次,模型的生成过程主要受限于内存带宽,而不是计算能力。这意味着,即使你的系统有更多的核心,Ollama 也不会使用所有的核心。实际上,使用超过一半的虚拟核心可能会降低速度,并且不必要地干扰其他进程。这就解释了为什么 Ollama 只使用了一半的核心。
因此,这个问题并不是错误,而是 Ollama 的预期行为。虽然模型的描述中警告你需要至少 8GB、16GB、32GB 等的 RAM,但这只是为了确保你的系统有足够的资源来运行模型,而不是说模型会使用所有的这些资源。
英文测试:

中文测试:
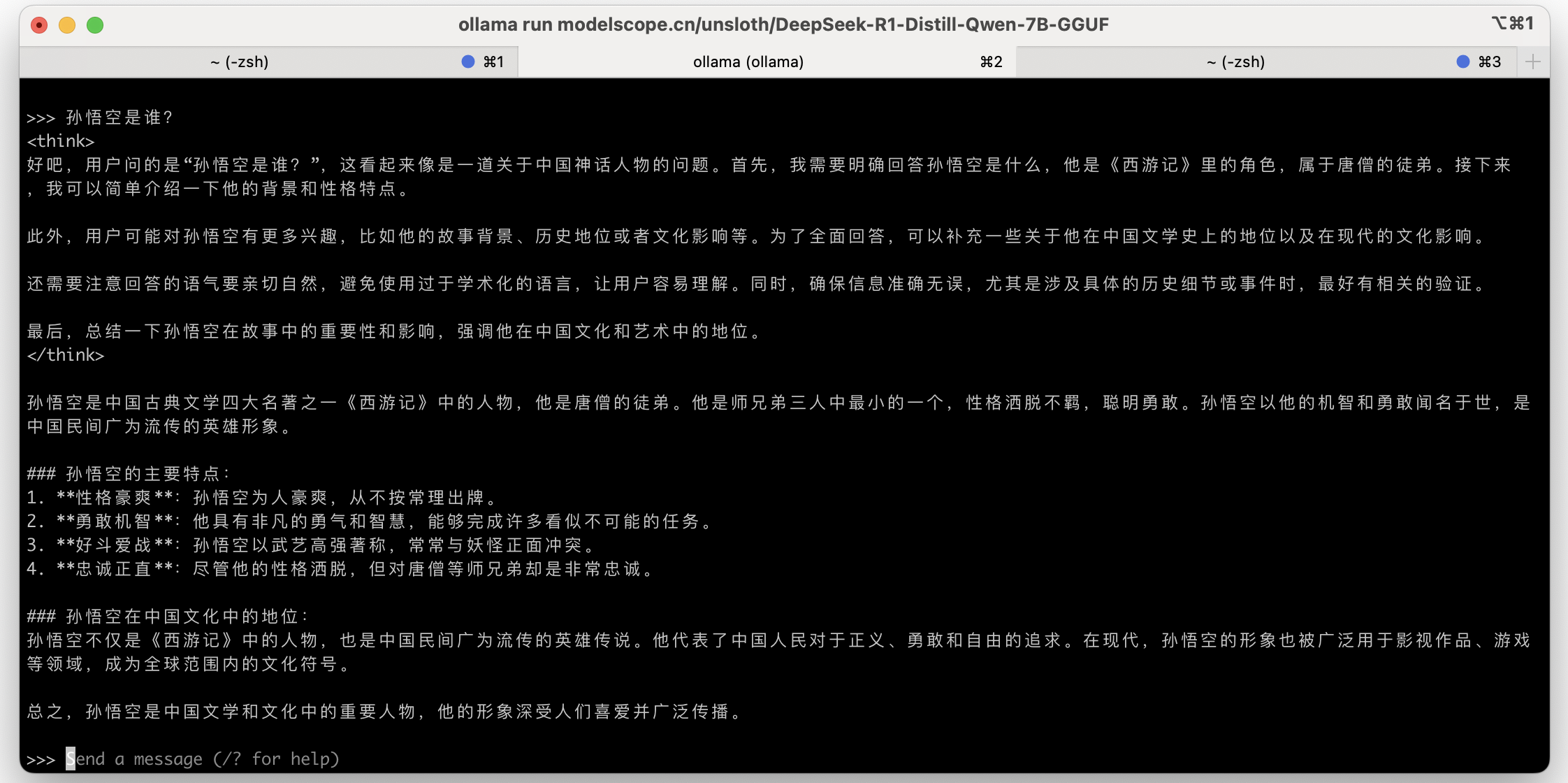
除了通过 Terminal 与大模型交互,也可以通过 Cherry Studio 提供的 GUI 图形界面工具访问本地的大模型。查看 Ollama 在本地监听的地址:localhost:11434,这是 Ollama 服务的默认接口地址。

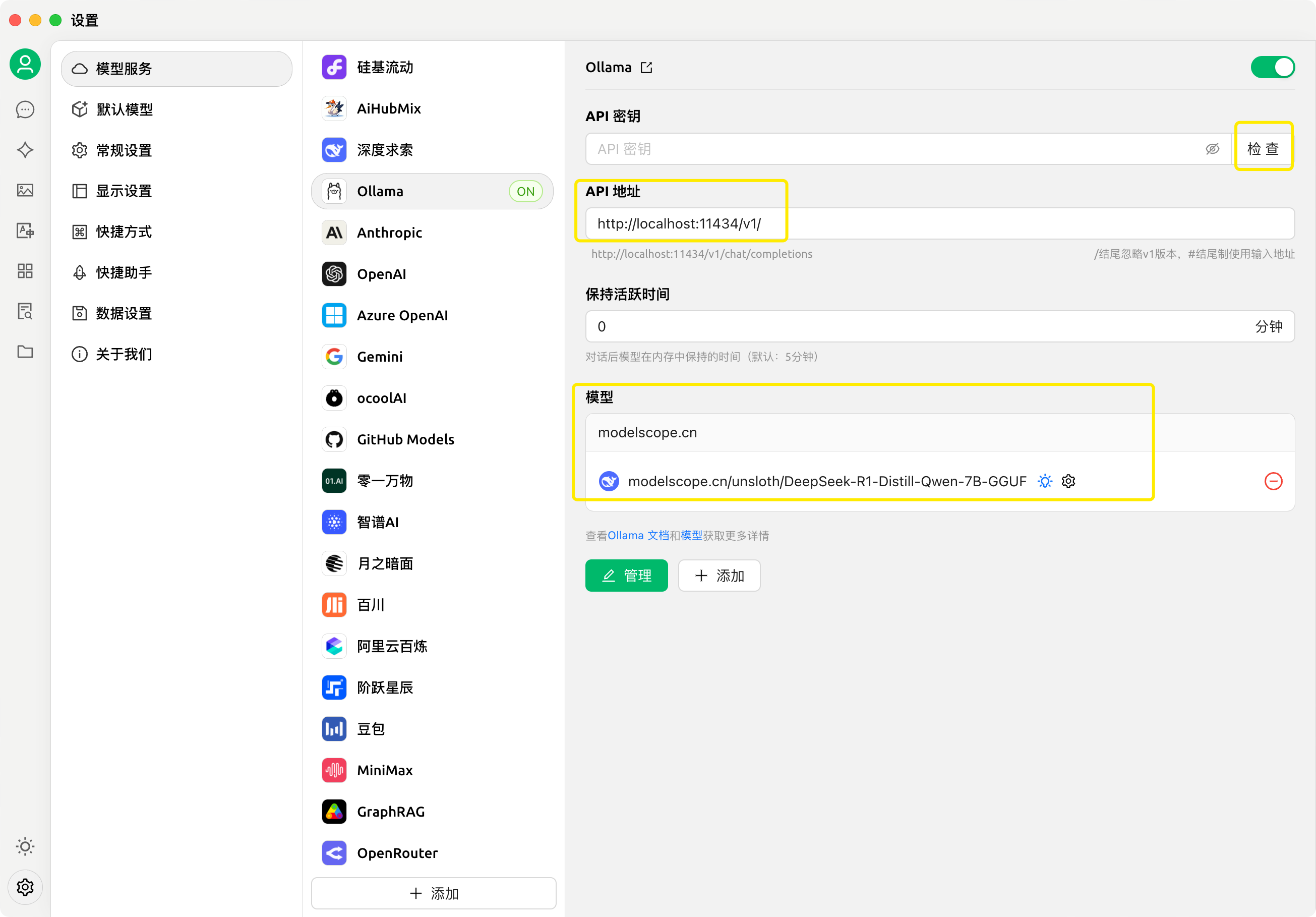
然后在 Cherry Studio 设置 -> 模型服务 -> Ollama 中,将 API 地址设置为 http://localhost:11434/v1/,并添加本地创建的模型,其中模型 ID 为:modelscope.cn/unsloth/DeepSeek-R1-Distill-Qwen-7B-GGUF,添加完成后,点击检查,测试连接是否成功。注意:模型 ID 务必填写与之前下载的模型版本完全一致的名称,否则会连接失败。
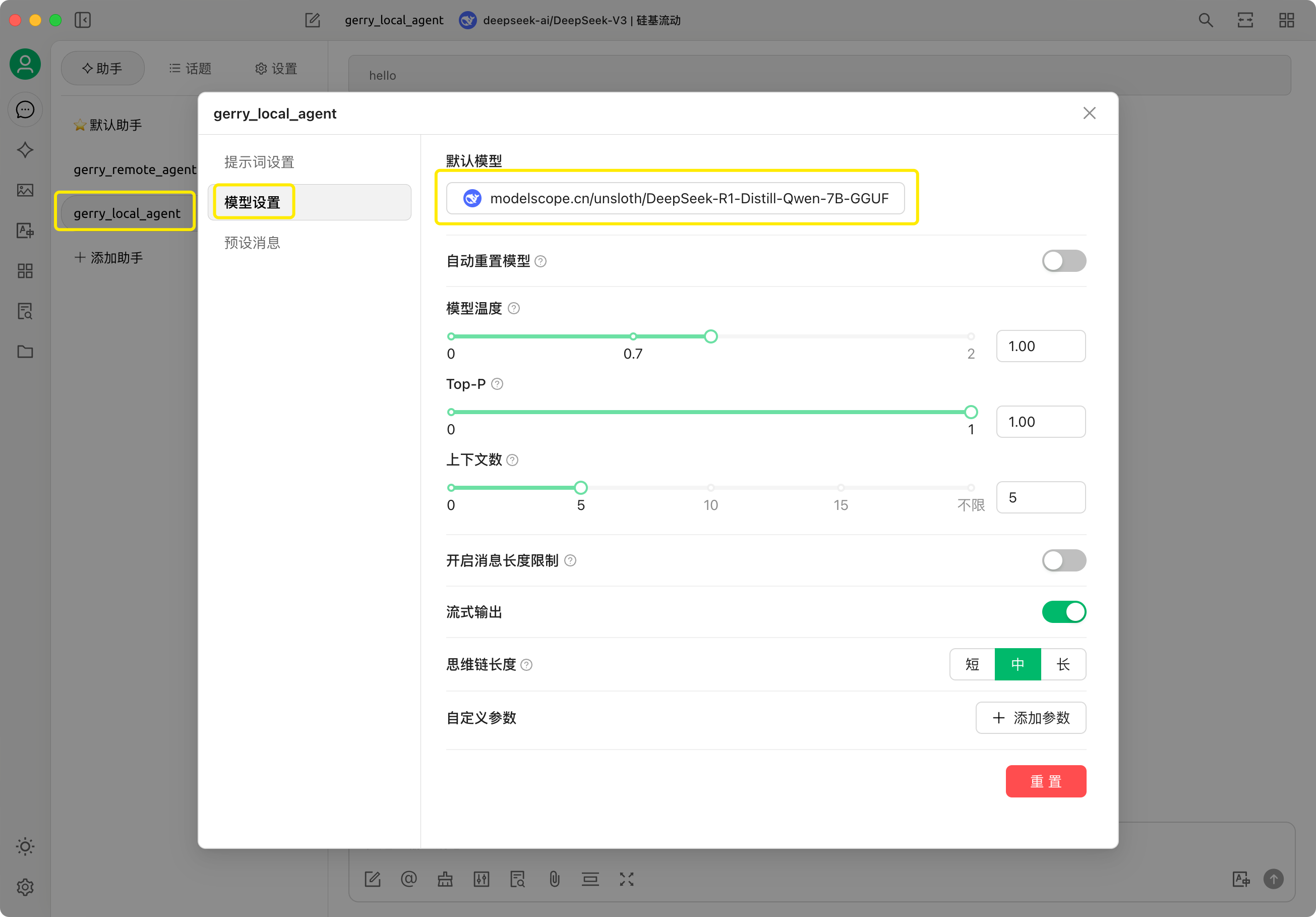
连接成功后,创建一个智能体 agent 命名为 gerry_local_agent 并设置使用本地创建的大模型 modelscope.cn/unsloth/DeepSeek-R1-Distill-Qwen-7B-GGUF。
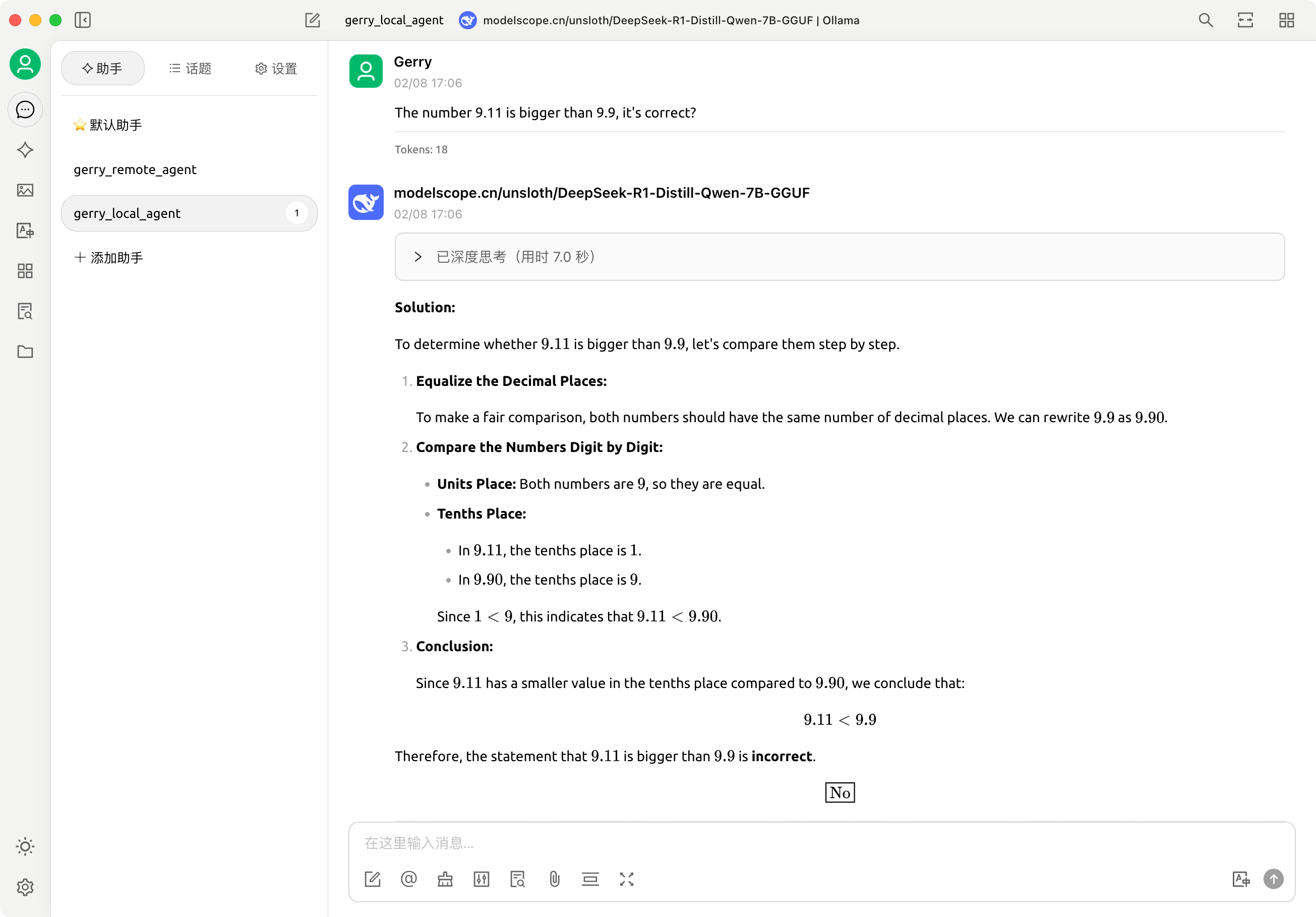
测试功能:
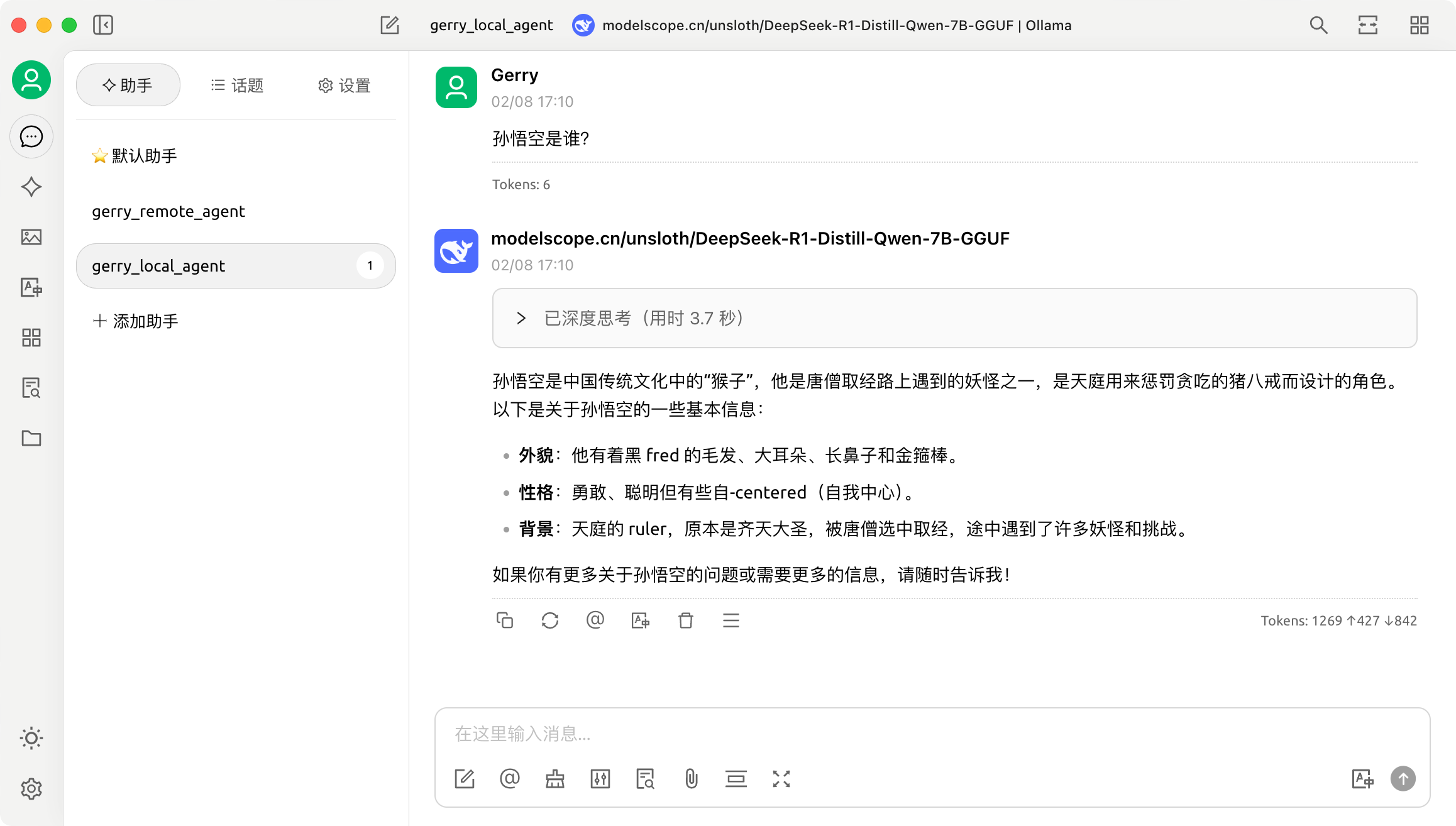
Q&A
How to change place of saving models on ollama
To change the default location where Ollama saves its models, you need to set an environment variable called OLLAMA_MODELS to the desired directory. Here’s how you can do it on different operating systems.
See more: Windows How do I install the model onto a different drive instead of the C drive? #2859
Open WebUI
Open WebUI is an extensible, feature-rich, and user-friendly self-hosted AI platform designed to operate entirely offline. It supports various LLM runners like Ollama and OpenAI-compatible APIs, with built-in inference engine for RAG, making it a powerful AI deployment solution.
For more information, be sure to check out our Open WebUI Documentation.
Cherry Studio
Desktop client with Ollama support.
Continue (vscode 扩展)
Continue is the leading open-source AI code assistant. You can connect any models and any context to build custom autocomplete and chat experiences inside VS Code and JetBrains.
配置选择本地部署的模型服务:
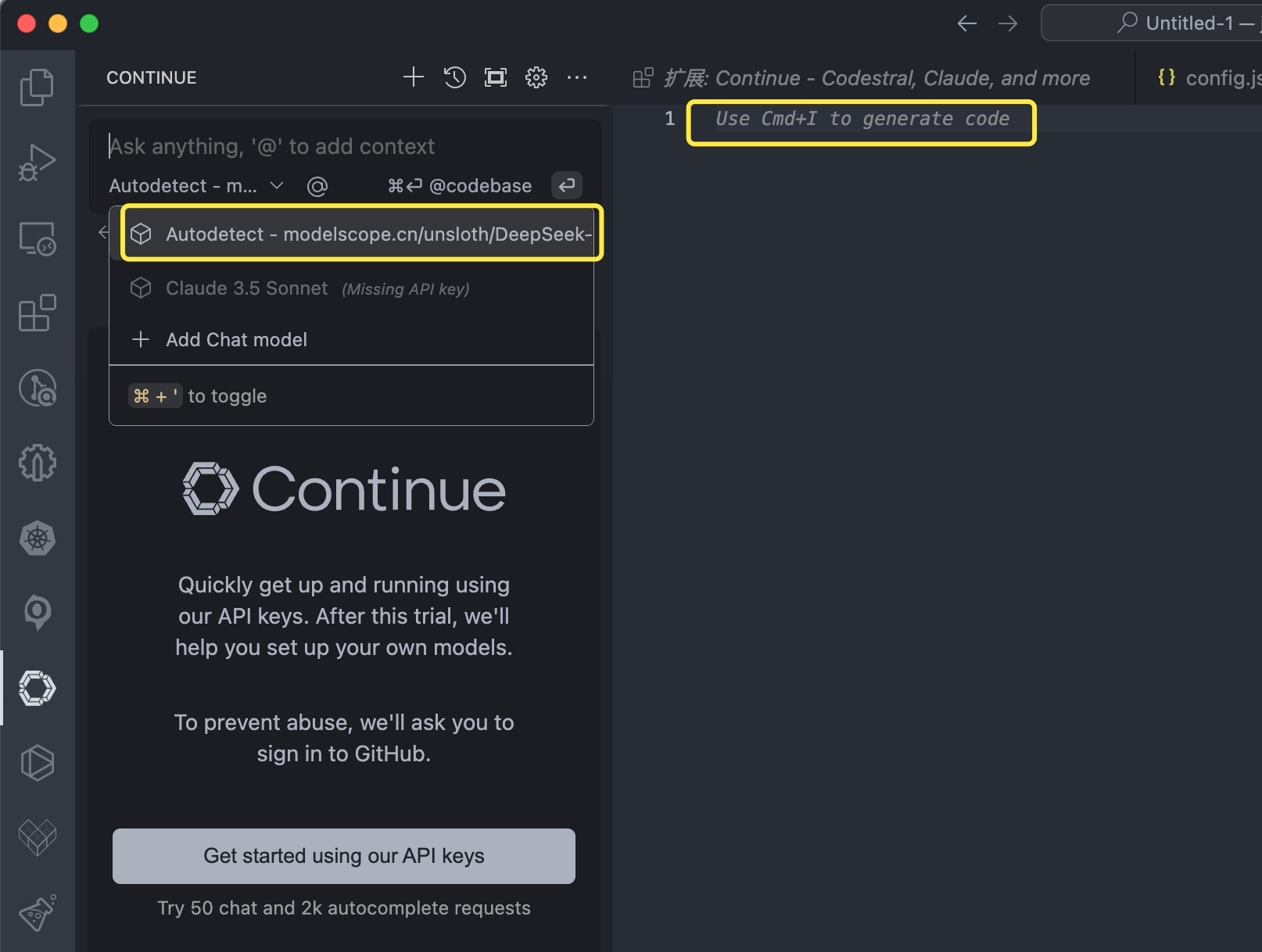
通过 command + I 触发交互命令 (Edit highlighted code),输入:实现计算一个最大公约数的代码。
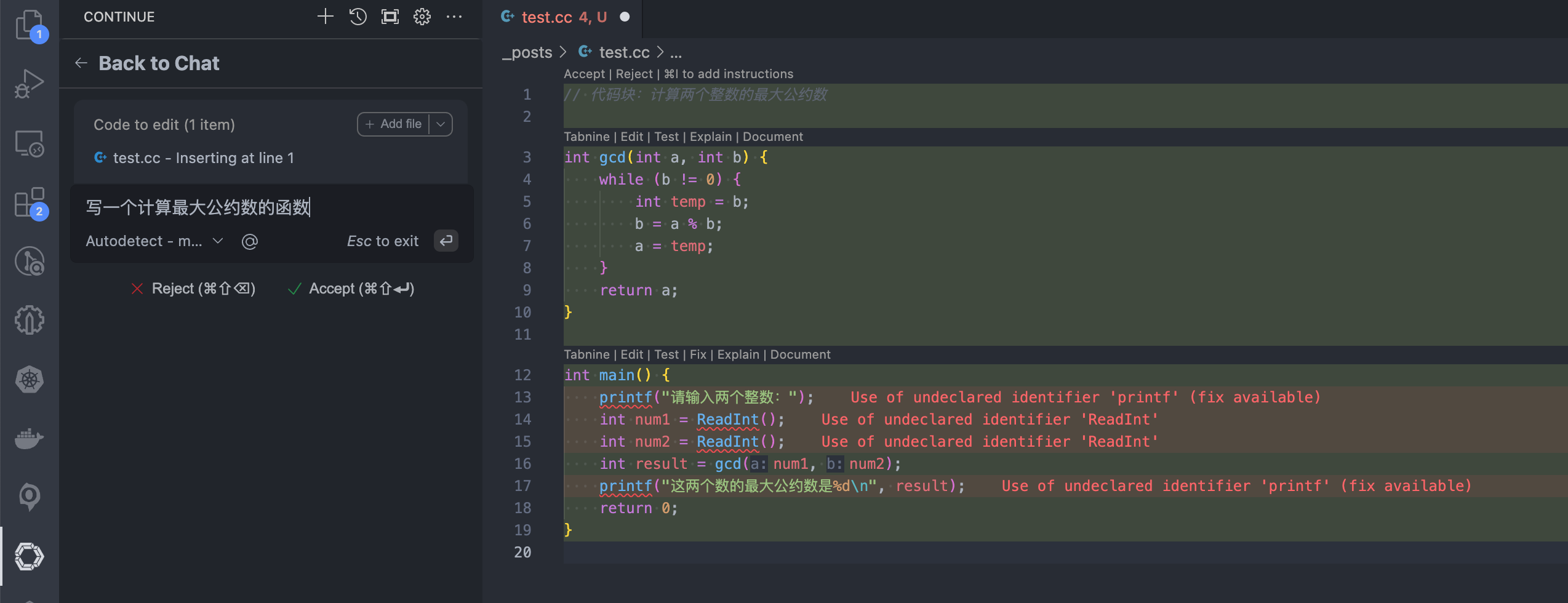
选中需要修改的代码,通过 command + L 获取当前代码内容 (Add to chat),输入下一个指令:对当前代码生成注释。
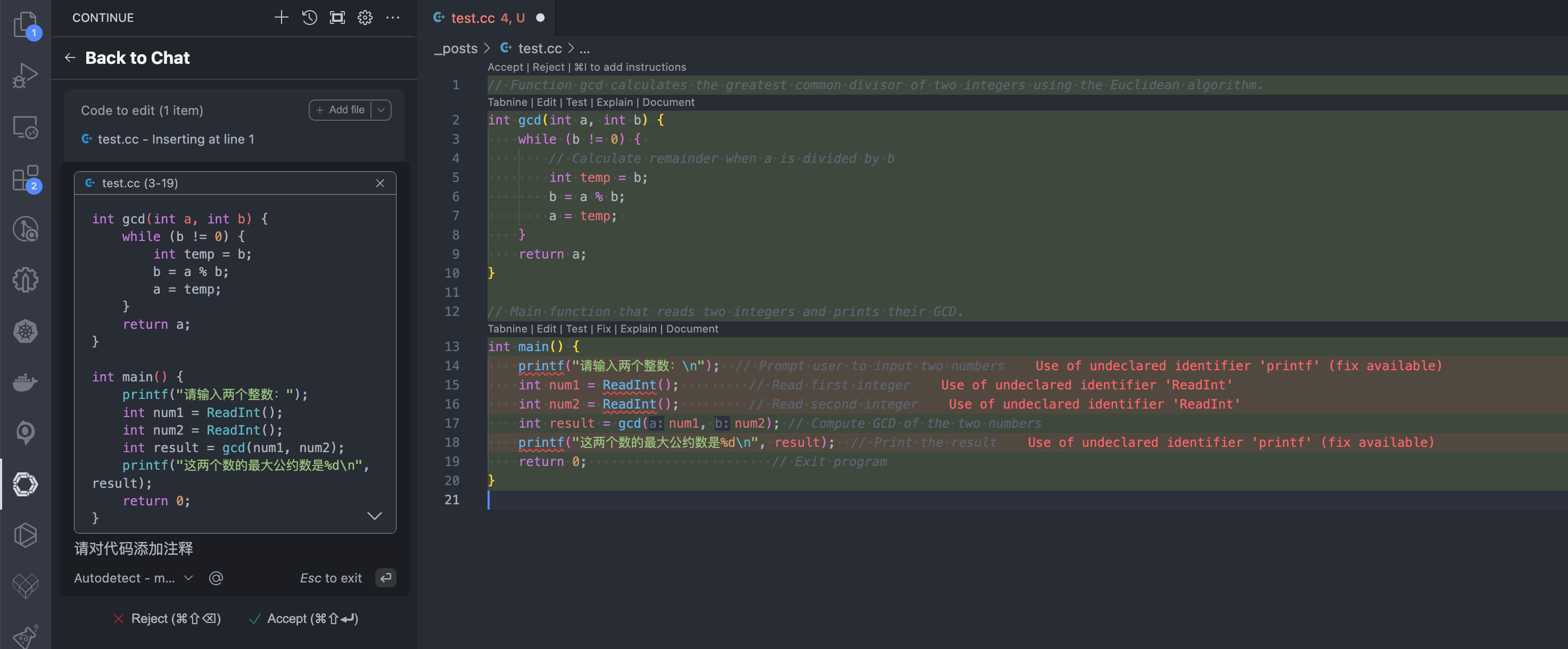
最后选择 accept 接受,完成代码编写。
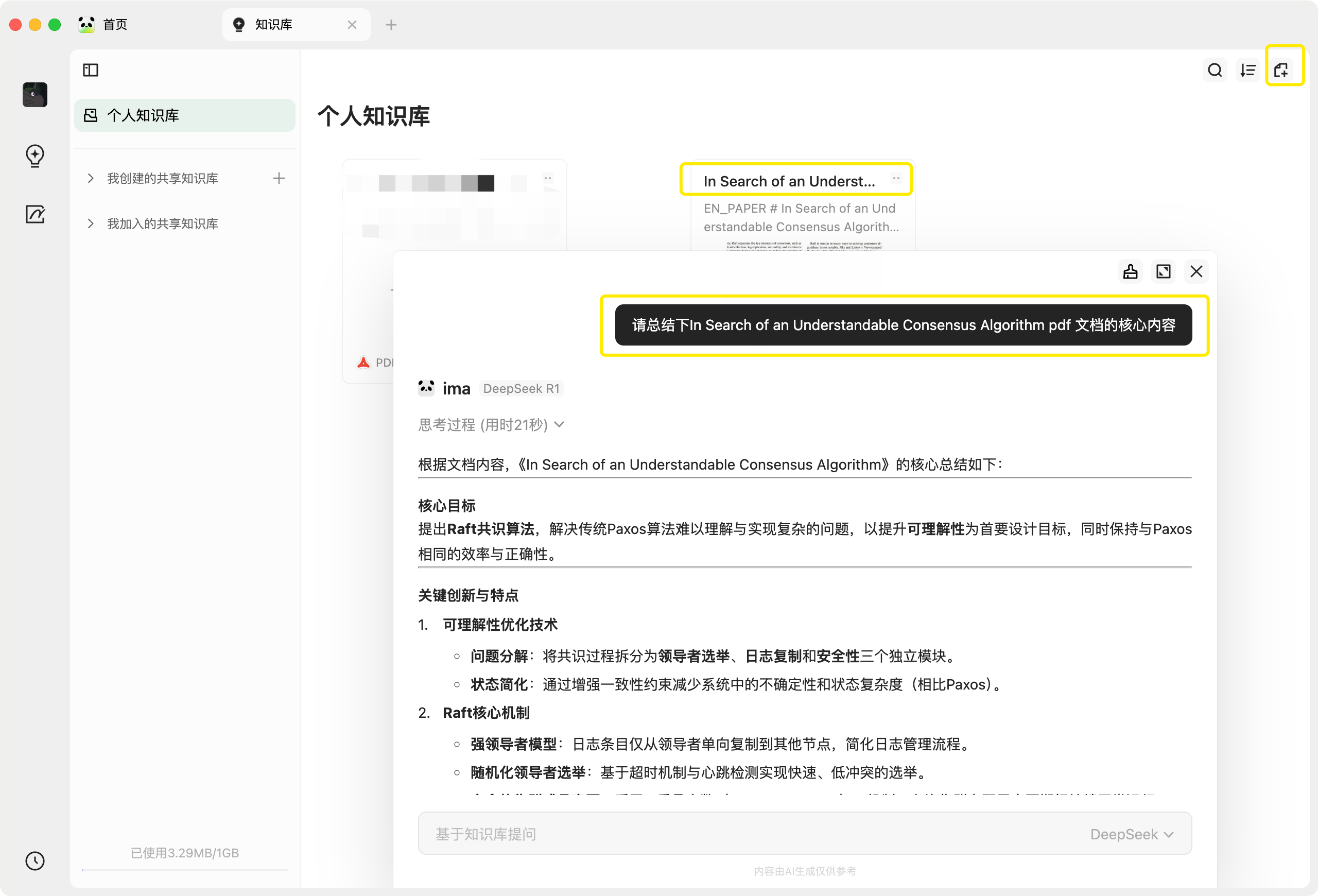
ima.copilot (会思考的知识库)
ima.copilot (简称 ima) 是一款由腾讯混元大模型提供技术支持的智能工作台产品。
Refer
- https://github.com/deepseek-ai
- https://www.deepseek.com/
- https://cloud.tencent.com/product/hai
- https://cherry-ai.com/
- https://github.com/CherryHQ/cherry-studio
- https://github.com/ollama/ollama
- https://cloud.tencent.com/document/product/1721/115966
- 快速部署和体验 DeepSeek 系列模型
- 大模型推理所需资源指南
- 带你一文读懂DeepSeek-R1新模型,为何震动了全球AI圈
- 小白也能看懂的DeepSeek-R1本地部署指南
- 基于 Cherry Studio+Ollama+DeepSeek 构建私有知识库