Questions about Dev
Question about Dev
基础问题
- 在多线程的程序中,存在一个全局的map结构,其成员是整数。下述哪些场景中必须采用锁机制来确保对map结构操作的安全性?
A: 该map结构在程序初始化过程中构建,程序运行过程只是读取map内容
B: 在程序运行过程中,仅1个线程修改map内容,其他线程只是读取map内容
C: 在程序运行过程中,每个线程负责不同元素的读写操作
D: 在程序运行过程中,存在多个线程修改map内容
正确答案:B,C,D
- 假设MySQL数据库中建立了对字段A、B、C的联合索引(A,B,C),请问下面哪些查询可以利用到这个联合索引?
A: select id from table where A = “x” and B = “y” and C = “z”
B: select id from table where A = “x” and B = “y”
C: select id from table where A = “x”
D: select id from table where A = “x” and C = “z”
正确答案:A,B,C,D
- C++多态
#include <stdio.h>
class Base
{
public:
virtual void foo() { printf("call Base::foo().\n"); }
void bar() { printf("call Base::Derive().\n"); foo();}
};
class Derive : public Base
{
public:
void foo() { printf("call Derive::foo().\n"); }
void bar() { printf("call Derive::Derive().\n"); foo();}
};
int main()
{
Base * ptr = new Derive();
if(ptr != NULL) ptr->bar();
return 0;
}
A: call Derive::bar(). call Derive::foo().
B: call Derive::bar(). call Base::foo().
C: call Base::bar(). call Derive::foo().
D: call Base::bar(). call Base::foo().
正确答案:C
- 关于线程安全,以下说法正确的是。
A: 可重入函数都是线程安全的函数
B: 线程安全函数都是可重入的函数
C: 线程不安全函数通过加锁可以改造成线程安全的函数
D: 线程不安全函数通过加锁可以改造成可重入函数
正确答案:A,C
函数可以是可重入的,也可以是线程安全的,或者两者皆是,或者两者皆非。不可重入函数不能由多个线程使用。
- 线程安全是在多线程情况下引发的,而可重入函数可以在只有一个线程的情况下发生。
- 线程安全不一定是可重入的,而可重入函数则一定是线程安全的。
- 如果一个函数有全局变量,则这个函数既不是线程安全也不是可重入的。
- 如果一个函数当中的数据全身自身栈空间的,则这个函数即使线程安全也是可重入的。
- 如果将对临界资源的访问加锁,则这个函数是线程安全的;但如果重入函数的话加锁还未释放,则会产生死锁,因此不能重入。
- 线程安全函数能够使不同的线程访问同一块地址空间,而可重入函数要求不同的执行流对数据的操作不影响结果,使结果是相同的。
- C++实现单例模式
class A
{
private:
static const A* m_instance;
A(){}
public:
static A* getInstance()
{
return m_instance;
}
};
//外部初始化
const A* A::m_instance = new A;
- 用宏定义MAX(a,b,c)求三个数最大值
#define MAX(a,b,c) (a>b?(a>c?a:c):(b>c?b:c))
- 用一个表达式,判断一个数X是否是2^N次方,不可用循环语句
!(X & (X-1))
- 下面代码的作用,求平均值
int f(int x, int y)
{
return (x&y) + ((x^y)>>1);
}
- 翻转一个字符串,例如把 “12345” 变成 “54321”
void reverse_by_swap(char* str, int n) {
char* begin = str;
char* end = str + n - 1;
while (begin < end) {
char tmp = *begin;
*begin = *end;
*end = tmp;
++begin;
--end;
}
}
// or
void reverse_by_std(char* str, int n){
std::reverse(str, str + n);
}
- 在32位或64位系统中,以下代码输出可能是哪些?
void test(int a[], int size)
{
int n = sizeof(a)/sizeof(int);
for (int i = 0; i < n && i < size; ++i) {
printf("%d ", a[i]);
}
}
int main()
{
int a[] = {1, 2, 3, 4};
test(a, sizeof(a)/sizeof(int));
return 0;
}
数组作为函数参数会退化为指针,指针在32位系统中大小是4字节,在64位系统大小是8字节。
32位:1
64位:1 2
- 以下代码可能输出有:
union U {
char* a;
char b;
};
struct S {
char* a;
char b;
};
union U2 {
S s;
U u;
};
int main()
{
printf("%zu ", sizeof(U));
printf("%zu ", sizeof(S));
printf("%zu ", sizeof(U2));
printf("%zu ", sizeof(std::array<char, 2>));
printf("%zu ", sizeof(char[2]));
printf("%zu ", sizeof(char *));
}
字节对齐,32位或64位系统。
4/8 4/8/16 4/8/16 2 2 4/8
- 当输入参数是2018时,函数返回值是:
int func(int n) {
if (n > 0) {
return n + func(n-1);
else
return 0;
}
}
计算累加和,(1 + 2018) / 2 * 2018 = 2037171
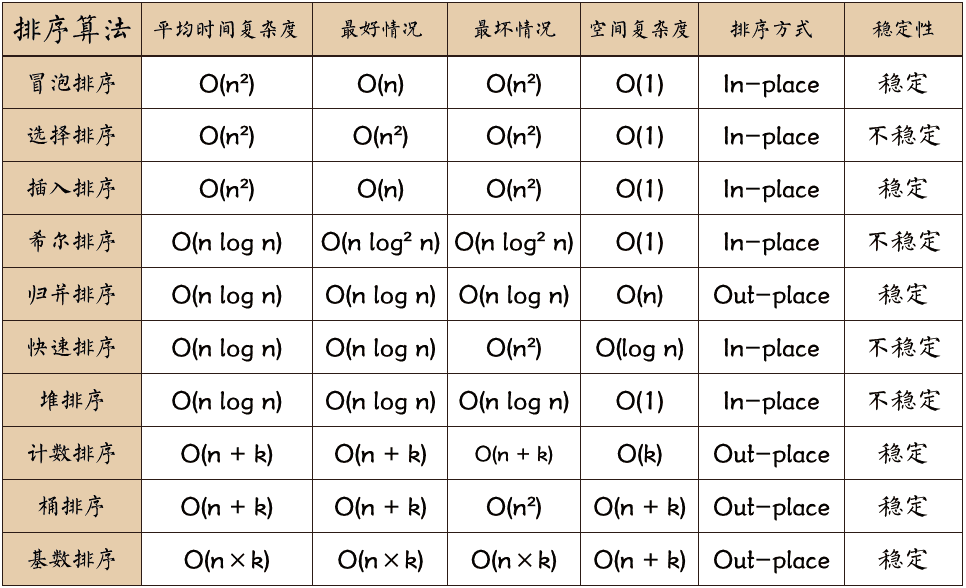
- 若数据元素序列 11, 12, 13, 7, 8, 9, 23, 4, 5 是采用下列排序方法之一得到的第二趟排序后的结果,则该排序算法只能是:
A 冒泡排序 B 插入排序 C 选择排序 D 归并排序
答案:B
| 算法 | 步骤 |
|---|---|
| 冒泡排序(Bubble Sort) | 比较相邻的元素。如果第一个比第二个大,就交换他们两个。对每一对相邻元素作同样的工作,从开始第一对到结尾的最后一对。这步做完后,最后的元素会是最大的数。针对所有的元素重复以上的步骤,除了最后一个。持续每次对越来越少的元素重复上面的步骤,直到没有任何一对数字需要比较 |
| 插入排序 | 将第一待排序序列第一个元素看做一个有序序列,把第二个元素到最后一个元素当成是未排序序列。从头到尾依次扫描未排序序列,将扫描到的每个元素插入有序序列的适当位置。(如果待插入的元素与有序序列中的某个元素相等,则将待插入元素插入到相等元素的后面) |
| 选择排序 | 首先在未排序序列中找到最小(大)元素,存放到排序序列的起始位置。再从剩余未排序元素中继续寻找最小(大)元素,然后放到已排序序列的末尾。重复第二步,直到所有元素均排序完毕 |
| 归并排序 | 该算法是采用分治法(Divide and Conquer)的一个非常典型的应用。1. 申请空间,使其大小为两个已经排序序列之和,该空间用来存放合并后的序列;2. 设定两个指针,最初位置分别为两个已经排序序列的起始位置;3. 比较两个指针所指向的元素,选择相对小的元素放入到合并空间,并移动指针到下一位置;4. 重复步骤 3 直到某一指针达到序列尾;5. 将另一序列剩下的所有元素直接复制到合并序列尾。 |
| 快速排序 | 快速排序是由东尼·霍尔所发展的一种排序算法。在平均状况下,排序 n 个项目要 Ο(nlogn) 次比较。在最坏状况下则需要 Ο(n2) 次比较,但这种状况并不常见。事实上,快速排序通常明显比其他 Ο(nlogn) 算法更快,因为它的内部循环(inner loop)可以在大部分的架构上很有效率地被实现出来。1. 从数列中挑出一个元素,称为 “基准”(pivot); 2. 重新排序数列,所有元素比基准值小的摆放在基准前面,所有元素比基准值大的摆在基准的后面(相同的数可以到任一边)。在这个分区退出之后,该基准就处于数列的中间位置。这个称为分区(partition)操作;3. 递归地(recursive)把小于基准值元素的子数列和大于基准值元素的子数列排序; |
refer:
-
主机甲和主机乙之间已建立一个TCP连接,TCP最大段长度为1000字节,若主机甲的当前拥塞窗口为4000字节,在主机甲向主机乙连接发送2个最大段后,成功收到主机乙发送的第一段的确认段,确认段中通告的接收窗口大小为3000字节,则此时主机甲还可以向主机乙发送的最大字节数是:2000字节
-
为数据动态分配内存时,有时要求对内存的起始地址做对齐操作以提高其访问效率。请问将某个指针地址Addr对齐到8字节可以使用下列哪条语句实现:
(Addr + 7) & (~7)
- 请选择对商业应用友好(可允许对代码进行修改后,再进行商用发布)的开源license:
A APL 2.0 B GPL C LGPL D MIT
答案:AD
Linux常用工具
http://linuxtools-rst.readthedocs.io/zh_CN/latest/base/index.html
iostat
- %util 接近100%,说明产生的I/O请求太多,I/O系统已经满负荷,该磁盘可能存在瓶颈。
- svctm 比较接近await,说明I/O 几乎没有等待时间。
- await 远大于svctm,说明I/O队列太长,应用得到的响应时间变慢。
- %util很大,而rkB/s和wkB/s很小,一般是因为磁盘存在较多的磁盘随机读写,最好把磁盘随机读写优化成顺序读写。
计算机基础
- 字符编码 ASCII,Unicode 和 UTF-8
http://www.ruanyifeng.com/blog/2007/10/ascii_unicode_and_utf-8.html
http://www.unicode.org/ https://www.joelonsoftware.com/2003/10/08/the-absolute-minimum-every-software-developer-absolutely-positively-must-know-about-unicode-and-character-sets-no-excuses/
编程语言部分
C++
- Function Object
如何实现下面的转换
// operator()
std::string operator()() const
{
return std::to_string(a);
}
myclass obj;
std::string str = obj();
-
函数是否占用对象的空间
-
什么情况下迭代器会失效
-
构造函数的初始值什么情况下必不可少?成员初始化顺序和什么有关?
(1) 如果成员是const,引用,或者属于某种未提供默认构造函数的类类型,我们必须通过构造函数初始值列表为这些成员提供初值。 (2) 构造函数初始值列表只说明用于初始化成员的值,而不限定初始化的具体执行顺序。成员的初始化顺序与它们在类定义中的出现顺序一致:第一个成员先被初始化,然后第二个,以此类推。构造函数初始值列表中初始值的前后位置关系不会影响实际的初始化顺序。 解决方法:最好构造函数初始值的顺序与成员声明的顺序保持一致,而且如果可能的话,尽量避免使用某些成员初始化其他成员。
- 隐士的类类型转换,如何抑制构造函数定义的隐士转换?为什么可以将
const char *赋值给string对象?
因为接受一个单参数的const char *的string构造函数不是explicit的。
通过将构造函数声明为explicit来阻止隐士转换。其中,
(1) 关键字explicit只对一个实参的构造函数有效;
(2) 需要多个实参的构造函数不能用于执行隐士转换,所以无须将这些构造函数指定为explicit的;
(3) 只能在类内声明构造函数时使用explicit关键字,在类外部定义时不应重复;
- 在C++程序中调用被C编译器编译后的函数,为什么要加
extern "C"
C++支持函数重载,C不支持函数重载。http://blog.csdn.net/delphiwcdj/article/details/7173387
- 使用表达式new失败如何处理?
默认情况下,如果new不能分配所要求的内存空间,它会抛出一个类型为bad_alloc的异常。我们可以改变使用new的方式来阻止它抛出异常:
int *p1 = new int; // 如果分配失败,new抛出std::bad_alloc
int *p2 = new (nothrow) int; // 如果分配失败,new返回一个空指针
bad_alloc和nothrow都定义在头文件new中。
http://www.cplusplus.com/reference/new/operator%20new[]/
New (std::nothrow) vs. New within a try/catch block C++ new operator and error checking [duplicate]
- 拷贝构造函数是什么?什么时候使用它?
如果构造函数的第一个参数是自身类类型的引用,且所有其他参数(如果有的话)都有默认值,则此构造函数是拷贝构造函数。拷贝构造函数在以下几种情况下会被使用: (1) 拷贝初始化(用=定义变量); (2) 将一个对象作为实参传递给非引用类型的行参; (3) 一个返回类型为非引用类型的函数返回一个对象; (4) 用花括号列表初始化一个数组中的元素或一个聚合类中的成员; (5) 初始化标准库容器或调用其insert/push操作时,容器会对其元素进行拷贝初始化;
- 拷贝赋值运算符是什么?什么时候使用它?合成拷贝赋值运算符完成什么工作?什么时候会生成合成拷贝赋值运算符?
(1) 拷贝赋值运算符本身是一个重载的赋值运算符,定义为类的成员函数,左侧运算对象绑定到隐含的this参数,而右侧运算对象是所属类类型的,作为函数的参数,函数返回指向其左侧运算对象的引用。 (2) 当对类对象进行赋值时,会使用拷贝赋值运算符。 (3) 通常情况下,合成拷贝赋值运算符会将右侧对象的非static成员逐个赋予左侧对象的对应成员,这些赋值操作时由成员类型的拷贝赋值运算符来完成的。 (4) 若一个类未定义自己的拷贝赋值运算符,编译器就会为其合成拷贝赋值运算符,完成赋值操作,但对于某些类,还会起到禁止该类型对象赋值的效果。
- 重载运算符
重载运算符是具有特殊名字的函数,由关键字operator和其后要定义的运算符号共同组成。和其他函数一样,重载的运算符也包含返回类型,参数列表以及函数体。 对于一个运算符函数来说,它或者是类的成员,或者至少含有一个类类型的参数。例如,不能为int重新定义内置的运算符。 我们只能重载已有的运算符,而无权发明新的运算符号。 不能被重载的运算符: :: .* . ?:
-
虚函数的优缺点
-
深拷贝和浅拷贝的区别
-
PImpl(Pointer to IMPLementation)
此技巧用于构造拥有稳定 ABI 的 C++ 库接口,及减少编译时依赖。
解释:
因为类的私有数据成员参与其对象表示,影响大小和布局,而且因为类的私有成员函数参与重载决议(这在成员访问检查前发生),故任何对实现细节的更改要求该类的所有用户重编译。pImpl 打破此编译依赖;更改实现不导致重编译。后续结果是,若库于其 ABI 使用 pImpl ,则库的新版本可以更改实现,并且与旧版本保持 ABI 兼容。
http://zh.cppreference.com/w/cpp/language/pimpl
http://oliora.github.io/2015/12/29/pimpl-and-rule-of-zero.html
https://cpppatterns.com/patterns/pimpl.html
- 一个空类占多少空间?多重继承的空类呢?虚拟继承呢?
一个空类所占空间为1,多重继承的空类还是1,虚拟继承涉及虚表(虚指针)大小是4
- C++中的空类默认会产生哪些类成员函数
编译器默认会产生4个成员函数,默认构造函数,析构函数,复制构造函数,赋值函数。
-
指针和引用的区别
- 非空区别。一个引用必须总是指向某些对象。
- 合法性区别。在使用引用之前不需要测试它的合法性。相反,指针则应该总是被测试,防止其为空。
- 可修改区别。引用总是指向在初始化时被指定的对象,以后不能改变,但是指定的对象其内容可以改变。
-
指针定义
int a; // an integer
int *a; // a pointer to an integer
int **a; // a pointer to a pointer to an integer
int a[10]; // an array of 10 integer
int *a[10]; // an array of 10 pointers to integers
int (*a)[10]; // a pointer to an array of 10 integers
int (*a)(int); // a pointer to a function that takes an integer argument and returns an integer
int (*a[10])(int); // an array of 10 pointers to functions that take an integer argument and return an integer
- 双指针
int a[] = {1, 2, 3, 4, 5};
int *ptr = (int *)(&a + 1);
printf("%d %d", *(a + 1), *(ptr - 1));// 2 5
char *a[] = {"hello", "the", "world"};
char **pa = a;
pa++;
std::cout << *pa << endl; // the
- C++中有了malloc/free,为什么还需要new/delete ?
malloc和free是C++/C语言的标准库函数,new/delete是C++运算符。它们都可以用于申请动态内存和释放内存。对于非内部数据类型的对象而言,只用malloc/free无法满足动态对象的要求。对象在创建的同时要自动执行构造函数,对象在消亡之前要自动执行析构函数。由于malloc/free是库函数而不是运算符,不在编译器控制权限之内,不能够把执行构造函数和析构函数的任务强加于malloc和free。
- 异常
In C++, you should NOT throw exceptions from:
* Constructor 可以抛异常
* Destructor 不建议抛异常,如果要抛异常需要在析构函数里自己捕获,否则多次抛异常程序无法处理
* Virtual function 可以抛异常
-
重载(overload)和覆盖(override)有什么不同
-
关键字static的作用是什么
- C语言中
- 函数体内static变量的作用范围为该函数体,不同于auto变量,该变量的内存只被分配一次,因此其值在下次调用时仍维持上次的值。
- 模块内的static全局变量,可以被模块内所有函数访问,但不能被模块外其他函数访问。
- 模块内的static函数,只能可以被这一模块内的其他函数调用,这个函数的使用范围被限制在声明它的模块内。
- C++语言中
- 类中的static成员变量,属于整个类所拥有,对类的所有对象只有一份复制。
- 类中的static成员函数,属于整个类所拥有,这个函数不接收this指针,因而只能访问类的static成员变量。
- C语言中
C
- 无符号和有符号是否可以比较
不可以,如果有符号的是负数,将类型提升为一个很大的无符号数
- 可以定义一个引用的指针吗
不可以,引用不是对象。
-
堆和栈的区别,在进程虚拟地址空间的位置
-
指向常量的指针,和常量指针分别如何定义
const int * p1 = 1;
int i;
int * const p2 = &i;
-
一个连续递增的整数序列,如何计算中位数 比如,3,4,5,6,7 则中位数为: 方法1:(3 + 7) / 2 = 5 溢出问题 方法2:3 + (7 - 3) / 2 = 5 如果是迭代器只能这样用,因为迭代器没有定义加法,只定义了减法
-
宏
测试方法:
gcc –E macro.test.c
https://gcc.gnu.org/onlinedocs/cpp/Macros.html
- 在16位机器上,使用预处理指令 #define 声明一个常数,用以表明1年中有多少秒(忽略闰年问题)
#define SECONDS_PER_YEAR (60 * 60 * 24 * 365)UL
-
sizeof和strlen的区别
-
memcpy和memmove的区别
-
内联函数,普通函数,宏的区别?
Java
https://stackoverflow.com/questions/40480/is-java-pass-by-reference-or-pass-by-value http://www.javadude.com/articles/passbyvalue.htm
GCC
- attribute ((packed))的作用
告诉编译器取消结构在编译过程中的优化对齐按照实际占用字节数进行对齐,是GCC特有的语法。这个功能是跟操作系统没关系,跟编译器有关,gcc编译器不是紧凑模式的。
struct stCoRoutineAttr_t
{
int stack_size;
stShareStack_t* share_stack;
stCoRoutineAttr_t()
{
stack_size = 128 * 1024;
share_stack = NULL;
}
}__attribute__ ((packed));
__thread
线程局部存储(Thread Local Storage)是一种机制,通过这一机制分配的变量,每个当前线程有一个该变量的实例。在多线程编程中,如果使用__thread关键字修饰global变量,可以使得这个变量在每个线程都私有一份。
__thread是GCC内置的线程局部存储设施,存取效率可以和全局变量相比。__thread变量每一个线程有一份独立实体,各个线程的值互不干扰。可以用来修饰那些带有全局性且值可能变,但是又不值得用全局变量保护的变量。
__thread使用规则:只能修饰POD类型,不能修饰class类型,因为无法自动调用构造函数和析构函数。可以用于修饰全局变量,函数内的静态变量,不能修饰函数的局部变量或者class的普通成员变量。
http://www.jianshu.com/p/13ebab5cd5b2
__sync_fetch_and_add
volatile unsigned int g_var = 0;
int atom_op()
{
unsigned int old_var = __sync_fetch_and_add(&g_var, 1);
printf("%d\n", old_var);
//unsigned int new_var = __sync_add_and_fetch(&g_var, 1);
//printf("%d\n", new_var);
return 0;
}
- 条件编译
static pid_t GetPid()
{
static __thread pid_t pid = 0;
static __thread pid_t tid = 0;
if( !pid || !tid || pid != getpid() )
{
pid = getpid();
#if defined( __APPLE__ )
tid = syscall( SYS_gettid );
if( -1 == (long)tid )
{
tid = pid;
}
#elif defined( __FreeBSD__ )
syscall(SYS_thr_self, &tid);
if( tid < 0 )
{
tid = pid;
}
#else
tid = syscall( __NR_gettid );
#endif
}
return tid;
}
// or
static unsigned long long GetTickMS()
{
#if defined( __LIBCO_RDTSCP__)
static uint32_t khz = getCpuKhz();
return counter() / khz;
#else
struct timeval now = { 0 };
gettimeofday( &now,NULL );
unsigned long long u = now.tv_sec;
u *= 1000;
u += now.tv_usec / 1000;
return u;
#endif
}
网络部分
- 基础知识
IP首部和TCP首部分别是多少个字节
20字节,8字节
短连接和长连接区别
HTTP/1.0 短连接 HTTP/1.1 Keep-Alive默认打开
TCP慢启动
- tcp为什么要四次挥手
全双工的协议
-
非阻塞网络编程有哪些方法,select和epoll的区别
-
大小端的定义和判别方法
-
什么情况下socket可读,可写
-
UDP协议和TCP协议的区别
TCP: bind
UDP: 需要bind吗,可以connect吗(可以然后可以调用send,否则要调用sendto指定目的地址和目的端口)
SO_REUSEADDR和SO_REUSEPORT区别
A TCP/UDP connection is identified by a tuple of five values:
{
, , , , }
Any unique combination of these values identifies a connection. As a result, no two connections can have the same five values, otherwise the system would not be able to distinguish these connections any longer.
SO_REUSEADDR和SO_REUSEPORT主要是影响socket绑定ip和port的成功与否。先简单说几点绑定规则 规则1:socket可以指定绑定到一个特定的ip和port,例如绑定到192.168.0.11:9000上; 规则2:同时也支持通配绑定方式,即绑定到本地”any address”(例如一个socket绑定为 0.0.0.0:21,那么它同时绑定了所有的本地地址); 规则3:默认情况下,任意两个socket都无法绑定到相同的源IP地址和源端口。
SO_REUSEADDR的作用主要包括两点
a. 改变了通配绑定时处理源地址冲突的处理方式
b. 改变了系统对处于TIME_WAIT状态的socket的看待方式
SO_REUSEPORT
a. 打破了上面的规则3,允许将多个socket绑定到相同的地址和端口,前提每个socket绑定前都需设置SO_REUSEPORT
b. Linux 内核3.9加入了SO_REUSEPORT
https://stackoverflow.com/questions/14388706/socket-options-so-reuseaddr-and-so-reuseport-how-do-they-differ-do-they-mean-t http://www.jianshu.com/p/141aa1c41f15
-
TCP协议的粘包问题如何解决
-
UDP相关
UDP数据包的接收 client发送两次UDP数据,第一次 500字节,第二次300字节,server端阻塞模式下接包,第一次recvfrom( 1000 ),收到是 1000,还是500,还是300,还是其他? 由于UDP通信的有界性,接收到只能是500或300,又由于UDP的无序性和非可靠性,接收到可能是300,也可能是500,也可能一直阻塞在recvfrom调用上,直到超时返回(也就是什么也收不到)。 在假定数据包是不丢失并且是按照发送顺序按序到达的情况下,server端阻塞模式下接包,先后三次调用:recvfrom( 200),recvfrom( 1000),recvfrom( 1000),接收情况如何呢? 由于UDP通信的有界性,第一次recvfrom( 200)将接收第一个500字节的数据包,但是因为用户空间buf只有200字节,于是只会返回前面200字节,剩下300字节将丢弃。第二次recvfrom( 1000)将返回300字节,第三次recvfrom( 1000)将会阻塞。
UDP包分片问题
如果MTU是1500,Client发送一个8000字节大小的UDP包,那么Server端阻塞模式下接包,在不丢包的情况下,recvfrom(9000)是收到1500,还是8000。如果某个IP分片丢失了,recvfrom(9000),又返回什么呢? 根据UDP通信的有界性,在buf足够大的情况下,接收到的一定是一个完整的数据包,UDP数据在下层的分片和组片问题由IP层来处理,提交到UDP传输层一定是一个完整的UDP包,那么recvfrom(9000)将返回8000。如果某个IP分片丢失,udp里有个CRC检验,如果包不完整就会丢弃,也不会通知是否接收成功,所以UDP是不可靠的传输协议,那么recvfrom(9000)将阻塞。
UDP丢包问题
在不考虑UDP下层IP层的分片丢失,CRC检验包不完整的情况下,造成UDP丢包的因素有哪些呢?
[1] UDP socket缓冲区满造成的UDP丢包
通过 cat /proc/sys/net/core/rmem_default 和cat /proc/sys/net/core/rmem_max可以查看socket缓冲区的缺省值和最大值。如果socket缓冲区满了,应用程序没来得及处理在缓冲区中的UDP包,那么后续来的UDP包会被内核丢弃,造成丢包。在socket缓冲区满造成丢包的情况下,可以通过增大缓冲区的方法来缓解UDP丢包问题。但是,如果服务已经过载了,简单的增大缓冲区并不能解决问题,反而会造成滚雪球效应,造成请求全部超时,服务不可用。
[2] UDP socket缓冲区过小造成的UDP丢包
如果Client发送的UDP报文很大,而socket缓冲区过小无法容下该UDP报文,那么该报文就会丢失。
[3] ARP缓存过期导致UDP丢包
ARP的缓存时间约10分钟,APR缓存列表没有对方的MAC地址或缓存过期的时候,会发送ARP请求获取MAC地址,在没有获取到MAC地址之前,用户发送出去的UDP数据包会被内核缓存到arp_queue这个队列中,默认最多缓存3个包,多余的UDP包会被丢弃。被丢弃的UDP包可以从/proc/net/stat/arp_cache的最后一列的unresolved_discards看到。当然我们可以通过echo 30 > /proc/sys/net/ipv4/neigh/eth1/unres_qlen来增大可以缓存的UDP包。
| UDP的丢包信息可以从cat /proc/net/udp 的最后一列drops中得到,而倒数第四列inode是丢失UDP数据包的socket的全局唯一的虚拟i节点号,可以通过这个inode号结合lsof(lsof -P -n | grep 25445445)来查到具体的进程。 |
- What does “connection reset by peer” mean?
This means that a TCP RST was received and the connection is now closed. This occurs when a packet is sent from your end of the connection but the other end does not recognize the connection; it will send back a packet with the RST bit set in order to forcibly close the connection.
This can happen if the other side crashes and then comes back up or if it calls close() on the socket while there is data from you in transit, and is an indication to you that some of the data that you previously sent may not have been received.
It is up to you whether that is an error; if the information you were sending was only for the benefit of the remote client then it may not matter that any final data may have been lost. However you should close the socket and free up any other resources associated with the connection.
https://stackoverflow.com/questions/1434451/what-does-connection-reset-by-peer-mean https://everything2.com/title/Connection+reset+by+peer http://blog.csdn.net/factor2000/article/details/3929816
- 如何避免惊群问题
惊群简单来说就是多个进程或者线程在等待同一个事件,当事件发生时,所有线程和进程都会被内核唤醒。唤醒后通常只有一个进程获得了该事件并进行处理,其他进程发现获取事件失败后又继续进入了等待状态,在一定程度上降低了系统性能。
accept锁,nginx的做法
REUSEPORT,允许将任意数目的socket绑定到完全相同的源地址端口对上
set_sock_opt(socket, SO_REUSERPORT);
Linux系统编程部分
-
进程和线程的差别
- 进程是程序的一次执行,线程可以理解为进程中执行的一段程序片段。
- CPU的最小调度单位是线程。
- 进程间是独立的,这表现在内存空间,上下文环境上。一般情况,进程无法突破进程边界存取其他进程内的存储空间;而线程由于处在进程空间内,所以同一个进程所产生的线程共享同一内存空间。
- 同一进程中的两段代码不能够同时执行,除非引入线程。
- 线程是属于进程的,当进程退出时,该进程所产生的线程都会被强制退出并清除。线程占用的资源要小于进程所占用的资源。
- 进程和线程都可以有优先级。
- 进程间可以通过IPC通信。
-
如何创建一个守护进程
-
一个动态库可以多次dlopen吗
-
如何查看ipc的一些资源 ipcs -a
-
如何查看进程执行的系统调用 strace -pxxx -s1024
-
如何查看进程打开的fd
ls -l /proc/pid/fd
- 一个进程core了如何定位
gdb program core.xxx bt f 0
-
多进程和多线程的区别
-
Linux虚拟地址空间如何分布?32位和64位有何不同?32/64位操作系统一个进程的虚拟地址空间分别是多少 4G/128T
- malloc是如何分配内存的?malloc分配多大的内存,就占用多大的物理内存空间吗?free 的内存真的释放了吗(还给 OS )? 既然堆内内存不能直接释放,为什么不全部使用 mmap 来分配?
malloc,calloc,realloc函数之间的区别?
void * malloc(int n); void * calloc(int n, int size); void * realloc(void * p, int n); -
如何查看进程虚拟地址空间的使用情况?
-
如何查看进程的缺页中断信息? 可通过以下命令查看缺页中断信息 ps -o majflt,minflt -C
ps -o majflt,minflt -p 其中, majflt 代表 major fault ,指大错误, minflt 代表 minor fault ,指小错误。这两个数值表示一个进程自启动以来所发生的缺页中断的次数。其中 majflt 与 minflt 的不同是, majflt 表示需要读写磁盘,可能是内存对应页面在磁盘中需要 load 到物理内存中,也可能是此时物理内存不足,需要淘汰部分物理页面至磁盘中。 如果进程的内核态 CPU 使用过多,其中一个原因就可能是单位时间的缺页中断次数多个,可通过以上命令来查看。 如果 MAJFLT 过大,很可能是内存不足。 如果 MINFLT 过大,很可能是频繁分配 / 释放大块内存 (128k) , malloc 使用 mmap 来分配。对于这种情况,可通过 mallopt(M_MMAP_THRESHOLD, ) 增大临界值,或程序实现内存池。 -
如何查看堆内内存的碎片情况?
-
除了glibc的malloc/free ,还有其他第三方实现吗?
- The difference among VIRT, RES, and SHR in
topoutput
VIRT stands for the virtual size of a process, which is the sum of memory it is actually using, memory it has mapped into itself (for instance the video card’s RAM for the X server), files on disk that have been mapped into it (most notably shared libraries), and memory shared with other processes. VIRT represents how much memory the program is able to access at the present moment.
RES stands for the resident size, which is an accurate representation of how much actual physical memory a process is consuming. (This also corresponds directly to the %MEM column.) This will virtually always be less than the VIRT size, since most programs depend on the C library.
SHR indicates how much of the VIRT size is actually sharable (memory or libraries). In the case of libraries, it does not necessarily mean that the entire library is resident. For example, if a program only uses a few functions in a library, the whole library is mapped and will be counted in VIRT and SHR, but only the parts of the library file containing the functions being used will actually be loaded in and be counted under RES.
More:
http://mugurel.sumanariu.ro/linux/the-difference-among-virt-res-and-shr-in-top-output/
https://serverfault.com/questions/138427/top-what-does-virtual-memory-size-mean-linux-ubuntu
https://events.linuxfoundation.org/sites/events/files/slides/elc_2016_mem.pdf
- IPC
sysv共享内存 shmget, shmat, shmdt 注意:每次shmat使用共享内存之后要shmdt,否则会导致打开句柄泄露(Too many open files in system(23)),通过ipcs -m可以看到nattch列有多少次attach。
// 如果已存在就使用之前的共享内存,如果不存在则创建共享内存并初始化
int shmid = shmget(MY_SHM_ID, sizeof(int), IPC_CREAT | 0666);
if (shmid == -1) {
printf("shmget failed, %s(%d,id=%x)", strerror(errno), errno, MY_SHM_ID);
return FAIL;
}
unsigned int * p_sn = (unsigned int *)shmat(shmid, NULL, 0);
if (p_sn == (unsigned int *) - 1) {
printf("shmat failed, %s(%d,id=%x)", strerror(errno), errno, MY_SHM_ID);
return FAIL;
}
unsigned old_sn = __sync_fetch_and_add(p_sn, 1);
if (shmdt(p_sn) == -1) {
printf("shmdt failed, %s(%d,id=%x)", strerror(errno), errno, MY_SHM_ID);
return FAIL;
}
http://www.csl.mtu.edu/cs4411.ck/www/NOTES/process/shm/shmget.html
- wait命令
wait命令一个很重要用途就是在Bash shell的并行编程中,可以在Bash shell脚本中启动多个后台进程(使用&),然后调用wait命令,等待所有后台进程都运行完毕,Bash shell脚本再继续向下执行。
command1 &
command2 &
wait
- Linux上的内存如计算?
top:
Mem: 131997524k total, 130328500k used, 1669024k free, 793232k buffers
Swap: 2105272k total, 428816k used, 1676456k free, 122989268k cached
free -m
total used free shared buffers cached
Mem: 128903 128567 336 0 776 121401
-/+ buffers/cache: 6389 122514
Swap: 2055 418 1637
可用内存: 122514 (-/+ buffers/cache free) = 336 (free)+ 776 (buffers)+ 121401 (cached) 总内存: 128902 (Mem: total) = 6389 (-/+ buffers/cache used)+ 122514 (-/+ buffers/cache free)
在很多Linux服务器上运行free 命令,会发现剩余内存(Mem:行的free列)很少,但实际服务器上的进程并没有占用很大的内存。这是因为Linux特殊的内存管理机制。Linux内核会把空闲的内存用作buffer/cached,用于提高文件读取性能。当应用程序需要用到内存时,buffer/cached内存是可以马上回收的。所以,对应用程序来说,buffer/cached是可用的,可用内存应该是free+buffers+cached。因为这个原因,free命令也才有第三行的-/+ buffers/cache。
Linux内存占用分析,是一个比较复杂的主题。更多资料可以参考下面的系列文章:
https://techtalk.intersec.com/2013/07/memory-part-1-memory-types/
https://techtalk.intersec.com/2013/07/memory-part-2-understanding-process-memory/
https://techtalk.intersec.com/2013/08/memory-part-3-managing-memory/
https://techtalk.intersec.com/2013/10/memory-part-4-intersecs-custom-allocators/
https://techtalk.intersec.com/2013/12/memory-part-5-debugging-tools/
- 避免死锁的算法有:
银行家算法。
编译器部分
- Makefile
一个工程中的源文件不计其数,其按类型、功能、模块分别放在若干个目录中,makefile定义了一系列的规则来指定,哪些文件需要先编译,哪些文件需要后编译,哪些文件需要重新编译,甚至于进行更复杂的功能操作。
比如有一个test.c文件,gcc针对上面几个过程,对应的命令如下:
预处理:gcc -E test.c -o test.i
编译:gcc -S test.c -o test.s
汇编:gcc -c test.s -o test.o
连接:gcc test.o -o test
并行编译。工程比较大时,并行编译非常会充分利用多CPU的优势,缩短编译的时间。
make -f makefile -j 8
两个函数patsubst,wildcard
makefile函数定义格式为:$(
$(wildcard *.cpp):表示展开工作目录下所有的.cpp文件;
$(patsubst %.cpp,%.o,$(wildcard *.cpp)):表示对.cpp文件列表字符串进行替换,替换为.o文件后缀的列表字符串;
Makefile.comm
CXX = g++
OBJS = $(patsubst %.cpp,%.o,$(wildcard *.cpp))
OBJS_I = $(patsubst %.cpp,%.i,$(wildcard *.cpp))
DEPENDS = $(patsubst %.o,%.d,$(OBJS))
MYFLAGS = -MMD -Wno-unused -pipe -g -O2 -D_GNU_SOURCE
PLATFORM := $(strip $(shell echo `uname -m`))
ifeq ($(PLATFORM,x86_64))
PLAT_FLAGS := 64
else
PLAT_FLAGS := 32
endif
MYFLAGS += -m${PLAT_FLAGS}
常用编译选项
-MMD:生成文件关联信息,并将结果保存在.d文件中;我们可以很方便的分析,引用的.h文件目录是否正确;
-Wno_unused:对于定义了没有使用的变量是否需要告警出来;
-pipe:使用管道代替编译中的临时文件;这是gcc的优化参数,默认情况下,gcc编译过程中的中间临时文件会放到/tmp目录下,并在编译完成后删除掉;读写文件会影响到编译的效率,管道取代临时文件,提升了编译效率;
-g:产生调试信息;调试信息分级别,默认是g2,也可以提升为g3,这样包含定义的宏;
-O2:编译器的优化选项的4个级别,-O0表示没有优化,-O1为缺省值,-O3优化级别最高;
-D_GNU_SOURCE:表示程序在GNU标准下进行编译,如果用到了GNU标准的信号量,锁等API函数,需要加上该选项;
-m32:生成32位操作系统的汇编代码;
$(strip $(shell echo uname -m)):打印操作系统版本出来;
Makefile
include ./Makefile.comm
TARGET = your_bin
PROJ_DIR = $(shell pwd)
SRC_DIR = ./
OBJ_DIR = ./
.PHONY: all clean init
all: $(OBJS_I) $(TARGET)
@echo -e "make proj dir $(PROJ_DIR) success"
$(TARGET): $(OBJS)
$(CXX) $(MYFLAGS) $^ -o $@ $(LIB)
$(OBJ_DIR)%.o: $(SRC_DIR)%.cpp
$(CXX) $(MYFLAGS) -c -o $@ $(INC) $<
$(OBJ_DIR)%.i: $(SRC_DIR)%.cpp
$(CXX) $(MYFLAGS) -o $@ $(INC) -E $<
clean:
rm -f $(OBJS) $(TARGET) $(DEPENDS)
-include $(DEPENDS)
PHONY:定义了显示执行makefile的命令名称,告诉编译系统,all,clean,init假定这些目标需要更新。有两个作用:a)如果clean为一个文件时,make clean将失效;b)如果all后面加上clean,但clean未声明为PHONY,编译系统会认为clean没有依赖,clean文件已经是最新的,不需要执行;
可以看见makefile的第一个目标为all,因此只执行make不加目标名的时候,将执行该伪目标; 用到了makefile常用的几个通配符,$^ $@, $< $@:目标文件 $^:所有的依赖文件 $<:第一个依赖文件 include表示包含一个外部的makefile文件进来,-include和include功能一样,-include忽略文件不存在的报错;
通常我们在Makefile中可使用“-include”来代替“include”,来忽略由于包含文件不存在或者无法创建时的错误提示(“-”的意思是告诉make,忽略此操作的错误。make继续执行)。像下边那样: -include FILENAMES… 使用这种方式时,当所要包含的文件不存在时不会有错误提示、make也不会退出;除此之外,和第一种方式效果相同。以下是这两种方式的比较: 使用“include FILENAMES…”,make程序处理时,如果“FILENAMES”列表中的任何一个文件不能正常读取而且不存在一个创建此文件的规则时make程序将会提示错误并退出。 使用“-include FILENAMES…”的情况是,当所包含的文件不存在或者不存在一个规则去创建它,make程序会继续执行,只有真正由于不能正确完成终极目标的重建时(某些必需的目标无法在当前已读取的makefile文件内容中找到正确的重建规则),才会提示致命错误并退出。 为了和其它的make程序进行兼容。也可以使用“sinclude”来代替“-include”(GNU所支持的方式)。
#ifndef GRANDPARENT_H
#define GRANDPARENT_H
struct foo {
int member;
};
#endif /* GRANDPARENT_H */
// or
#pragma once // most C and C++ implementations provide a non-standard #pragma once directive. This directive, inserted at the top of a header file, will ensure that the file is included only once.
数据库部分
- Locking Reads
select … for update
Locking of rows for update using SELECT FOR UPDATE only applies when autocommit is disabled (either by beginning transaction with START TRANSACTION or by setting autocommit to 0. If autocommit is enabled, the rows matching the specification are not locked.
https://stackoverflow.com/questions/10935850/when-to-use-select-for-update https://dev.mysql.com/doc/refman/5.7/en/innodb-locking-reads.html
-
mysql_use_result和mysql_store_result的区别
-
B+Tree和LSM Tree区别 nosql基本没有用B+树的,很多采用了LSM Tree,比如hbase/cassandra,rocksdb/leveldb B+树跟LSM Tree的时间复杂度对比(N是tree的node数) 随机点写入,LSM Tree O(1),B+树O(logN) 随机点读出,LSM Tree O(N),B+树O(logN) 对B+树或者LSM Tree做一些变形增加一些数据结构,也可以优化一些时间复杂度,当然这些优化可能带来额外的开销,更多的时候是在读/写、随机/顺序之间的tradeoff,有些专门的论文研究这方面的数据结构和算法。有兴趣的可以看看tokudb。 传统OLTP数据库在机械磁盘这种慢设备(随机IO性能差很多)上设计的,OLTP场景本来也是读多写少,数据量不大,因此,选择B+数据的数据结构主要是这些历史原因吧。传统数据库的存储引擎非常复杂(存储引擎和查询优化是单机RDBMS的两个核心难点)。此外,即使在SSD上,随机IO跟顺序IO的性能差异也是有的。因此,SSD出现后,传统RDBMS,也没有动力去重构存储引擎。当然,mysql是出现了myrocks这样的项目作为LSM tree的存储引擎。 随着数据量的爆炸和SSD的出现,越来越多的新兴数据库选择LSM Tree,这样数据写入性能有较大提升,用LSM tree做列存储,数据压缩效果比行存的B+树也要好很多。同时由于SSD的存在,随机读性能也比B+树也不会差太多。
一般来说LSMtree更适合分析,比如经常做批量数据倒入,范围顺序扫描等场景;B+树更适合OLTP的点查询。LSMTree是列存储友好的(value非定长,容易压缩),B+树是行存储友好的(字段定长)。行存储更多用在事务库,列存储更多是分析库吧。有人提出列存储和行存的混合模式做HTAP的数据库,论文记不清了。对于未来趋势,最近开源出来的OLTP的newsql(cockroach tidb),都是用LSMTree。
https://www.zhihu.com/question/65628840
-
找出a表里面num最小的数的记录。
- select * from a where num = (select min(num) from a);
- select * from a where num <= all(select num from a);
- select top 1 num from a order by num;
-
MySQL的隔离级别哪有四种
MySQL默认事务隔离级别是REPEATABLE READ(可重复读)。
算法和数据结构
- 10亿数据中取最大的100个数据
http://www.jianshu.com/p/4427db9337d7
- HashMap的实现原理
数组 + 链表(桶)。简单地说,HashMap 在底层将 key-value 当成一个整体进行处理,这个整体就是一个 Entry 对象。HashMap 底层采用一个 Entry[] 数组来保存所有的 key-value 对,当需要存储一个 Entry 对象时,会根据 hash 算法来决定其在数组中的存储位置,在根据 equals 方法决定其在该数组位置上的链表中的存储位置;当需要取出一个Entry 时,也会根据 hash 算法找到其在数组中的存储位置,再根据 equals 方法从该位置上的链表中取出该Entry。
public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
// Find a power of 2 >= initialCapacity
int capacity = 1;
while (capacity < initialCapacity)
capacity <<= 1;
this.loadFactor = loadFactor;
threshold = (int)Math.min(capacity * loadFactor, MAXIMUM_CAPACITY + 1);
table = new Entry[capacity]; // 数组
useAltHashing = sun.misc.VM.isBooted() &&
(capacity >= Holder.ALTERNATIVE_HASHING_THRESHOLD);
init();
}
static class Entry<K,V> implements Map.Entry<K,V> {
final K key; // 一个键值对
V value;
Entry<K,V> next; // next 的 Entry 指针(桶)
final int hash;
……
}
// 核心算法
static int hash(int h) {
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
static int indexFor(int h, int length) {
return h & (length-1);
}
HashMap requires a better hashCode() - JDK 1.4 Part II
hashtable使用质数是考虑到分布更均匀,但模运算比较慢。hashmap使用2的指数可以利用掩码运算速度更快,但是设计了新的rehash方法,总体性能比之前好。
如何保证元素均匀,特殊的取模方法,但是模运算的计算代价高,h%length改为h&(length-1),要求length是2^n。当数组长度为 2 的 n 次幂的时候,不同的 key 算得得 index 相同的几率较小,那么数据在数组上分布就比较均匀,也就是说碰撞的几率小,相对的,查询的时候就不用遍历某个位置上的链表,这样查询效率也就较高了。
HashMap 的 resize(rehash)?当 HashMap 中的元素越来越多的时候,hash 冲突的几率也就越来越高,因为数组的长度是固定的。所以为了提高查询的效率,就要对 HashMap 的数组进行扩容。而在 HashMap 数组扩容之后,最消耗性能的点就出现了:原数组中的数据必须重新计算其在新数组中的位置,并放进去,这就是 resize。所以如果我们已经预知 HashMap 中元素的个数,那么预设元素的个数能够有效的提高 HashMap 的性能。
线程安全?在Java里的解决方法是:使用java.util.HashTable,效率最低;或者使用java.util.concurrent.ConcurrentHashMap,相对安全,效率较高。
http://wiki.jikexueyuan.com/project/java-collection/hashmap.html
http://wiki.jikexueyuan.com/project/java-collection/hashtable.html
http://zhaox.github.io/2016/07/05/hashmap-vs-hashtable
- KMP算法
KMP算法的时间复杂度为O(m+n),这个算法最为巧妙的地方在于:每次匹配时,利用了之前匹配的结果,从而避免需要将指针回退。
子串的next数组实际是这个算法的cache数据,牺牲了空间,换取了时间上的高效,在我们实际项目中,有很多类似的应用场景;
另外一个经典的字符串匹配算法AC自动机匹配算法,用于对一段Query进行字典词匹配。在实际应用场景中,如基于字典表的分词,脏词库识别等,都有广泛应用,后面也将展开该算法的实现。
- 无锁队列的实现
数组 链表
- 怎样写出一个更快的 memset/memcpy
https://www.zhihu.com/question/35172305
- 红黑树
// 红黑树结点定义
typedef struct RBTNode
{
int key;
struct RBTNode *parent, *left, *right;
int color;
int size; //扩张红黑树
} RBTNode, *RBTree;
内核相关
-
Linux的RCU机制
-
RBP 和 RSP X86-64 64位的寄存器一般都是叫RXX,其低32位向下兼容一般称为EXX
不过x86-64时代,现代编译器下已经不是这样的布局了,传递参数不再压栈,而是通过固定的几个寄存器。
现代编译器做了这些改变,除了通过寄存器传递参数比之前参数压栈要快之外。对于我们debug好处,就是当出现堆栈溢出,向上冲破到FunA的栈帧的时候,不会覆盖到这些参数,那么core的时候我们依然可以看到FunA传递给FunB的参数,这样我们就能够定位到底是不是由于FunA传递进来的参数引起的。
# 查看RBP指向的区域
p $rbp
x/64ag $rbp
局部变量都在栈底rbp的下方,即$rbp-Offset的区域。如果知道了对应的Offset值,不就能够p去查看了
CPU常用寄存器
在X86-64中,所有寄存器都是64位,相对32位的x86来说,标识符发生了变化,比如:从原来的%ebp变成了%rbp。为了向后兼容性,%ebp依然可以使用,不过指向了%rbp的低32位。
X86-64寄存器的变化,不仅体现在位数上,更加体现在寄存器数量上。新增加寄存器%r8到%r15。加上x86的原有8个,一共16个寄存器。
| 寄存器 | 作用 |
|---|---|
| RIP | 指向哪,程序就运行到哪里。调用FunB,就把RIP指向FunB的入口地址。 |
| RAX | 函数的返回值一般通过RAX寄存器传递 |
| RBP | 一般用于指向当前函数调用栈的栈底,以方便对栈的操作,如获取函数参数、局部变量等。低32位称为EBP |
| RSP | 一直指向当前函数调用栈的栈顶,RSP在函数返回时要和调用前的指向要一致,即使所谓的栈平衡。低32位叫ESP |
传递参数用到的寄存器,看反汇编时会遇到
| 寄存器 | 作用 |
|---|---|
| RDI | 第1个参数 |
| RSI | 第2个参数 |
| RDX | 第3个参数 |
| RCX | 第4个参数 |
| R8 | 第5个参数 |
| R9 | 第6个参数 |
使用gdb 指令info reg 可以查看CPU常用的几个寄存器。对其他寄存器感兴趣的同学可以查看《参考文献》当中《Intel® 64 and IA-32 Architectures Software Developer Manuals》和《X86-64寄存器和栈帧》
反汇编
gdb 指令 disassemble /m 函数名(或者地址), /m是映射到代码
gdb 默认使用的AT&T的语法,另外一种常见的是Intel 汇编语法(个人更喜欢这种风格)
可以使用set disassembly-flavor intel or att来切换风格
参考文献
函数调用 压栈的工作原理 http://blog.csdn.net/u011555996/article/details/70211315
X86-64寄存器和栈帧 http://blog.csdn.net/dayancn/article/details/51328959
对于ESP、EBP寄存器的理解 http://blog.csdn.net/yeruby/article/details/39780943
esp和ebp详解 http://www.cnblogs.com/dormant/p/5079894.html
GDB相关反汇编指令 http://blog.csdn.net/linuxheik/article/details/17529919
LINUX下GDB反汇编和调试 http://www.cnblogs.com/brucemengbm/p/7223724.html
AT&T汇编语法 http://ted.is-programmer.com/posts/5251.html
AT&T汇编简介 http://ilovers.sinaapp.com/article/att%E6%B1%87%E7%BC%96gasgnu-assembly
AT&T 与 Intel 汇编语言的比较 http://blog.csdn.net/21aspnet/article/details/7176915
GCC 中的编译器堆栈保护技术 https://www.ibm.com/developerworks/cn/linux/l-cn-gccstack/index.html
Linux下缓冲区溢出攻击的原理及对策 https://www.ibm.com/developerworks/cn/linux/l-overflow/
缓冲区溢出攻击 http://netsecurity.51cto.com/art/201407/446830.htm
GCC “Options That Control Optimization” https://gcc.gnu.org/onlinedocs/gcc-4.4.2/gcc/Optimize-Options.html
Stack overflow “gcc -fomit-frame-pointer” https://stackoverflow.com/questions/14666665/trying-to-understand-gcc-option-fomit-frame-pointer
Intel® 64 and IA-32 Architectures Software Developer Manuals https://software.intel.com/en-us/articles/intel-sdm
一种处理栈越界的方法 https://zhuanlan.zhihu.com/p/20642841
硬件相关
- 如何理解SSD的写放大
https://www.zhihu.com/question/31024021
- SATA、SAS、SSD三种硬盘存储性能数据
https://wenku.baidu.com/view/1f61305c83d049649a66584f.html
* SATA和SAS机械硬盘随机读写能力较弱,而顺序读写能力基本与SSD保持在同样的数量级,尤其是顺序读写大文件性能更佳
* SSD的强项在于随机IO读写,基本可以媲美内存的访问速度,当然其顺序读写能力也处于比较高的水平
* 小块文件随机读,是固态存储相对传统磁盘优势最大的场景。相对磁盘,固态存储设备不存在寻道时间。因此,其性能要比单块性能最优的传统磁盘高出150倍到250倍
* 受寻道时间这个机械因素影响,传统磁盘在随机读写场景,基本没有优势,由于磁盘读和写两个操作时间大概相同,所以随机读和随机写,单块磁盘的性能基本差不多
* 对持续的大块写入请求,固态存储耗费擦除操作(耗时长)的时间大幅增加,而传统的磁盘却好相反,耗时长的寻道操作大幅减小,一次寻道,多次写入
* 传统磁盘,受寻道机械操作影响,在随机操作场景性能不佳,而在大块,持续写入的场景由于寻道操作相对减少,其表现较好,比较适合性能要求不高,对容量较高的场景。
- 一些硬件技术
专用集成电路(英语:Application-specific integrated circuit,缩写:ASIC)
FPGA(Field-Programmable Gate Array),即现场可编程门阵列。它是在PAL、GAL、CPLD等可编程器件的基础上进一步发展的产物。它是作为专用集成电路(ASIC)领域中的一种半定制电路而出现的,既解决了定制电路的不足,又克服了原有可编程器件门电路数有限的缺点。
数学
- 已知某酒鬼有90%的日子都会出去喝酒,喝酒只去固定三家酒吧。今天警察找了其中两家酒吧都没有找到酒鬼。问:酒鬼在第三家酒吧的几率? https://www.guokr.com/post/61605/
性能调优
- the zero-cost exception model It offers zero runtime overhead for an error-free execution, which surpasses even that of C return-value error handling. As a trade-off, the propagation of an exception has a large overhead.
Exception Frames
Exceptions are handled in frames. The simplest of these frames is a ‘try/catch’ block in the source code. The ‘try’ opens an exception frame and the ‘catch’ defines the handler for that frame. Exceptions within that frame flow to the handler: either they match and the exception is handled, or they do not match and the exception is propagated further.
In addition to ‘catch’ handlers, are cleanup handlers. This is code that must be called during exception propagation but doesn’t stop the exception. This includes any ‘finally’ blocks and C++ destructors. Explicit ‘finally’ blocks are matched with a ‘try’, so it is easy to see where their frame is defined. Destructors create implicit frames, starting at the point of instantiation (variable declaration), ending with the enclosing scope. Note that every object with a destructor creates its own exception frame.
Languages with ‘defer’ statements, like Leaf, also introduce exception frames. These are very similar to destructors: the ‘defer’ statement opens a frame which ends with the enclosing scope. Any language feature which requires code to execute during an exception will require an exception frame.
**It’s important to see all of these frames; compilers used to generate code at each ‘try’ statement to handle exceptions. One technique was ‘setjmp/longjmp’: each ‘try’ adds a jump address to an exception handler stack and the ‘finally’ clauses remove it. Even if no exception was thrown the work of adding/removing from the handler stack would still be done. One of the key goals of zero-cost exceptions was to get rid of this needless setup/teardown work.**
https://mortoray.com/2013/09/12/the-true-cost-of-zero-cost-exceptions/ http://ithare.com/infographics-operation-costs-in-cpu-clock-cycles/
-
gettimeofday优化 https://access.redhat.com/solutions/18627 cat /sys/devices/system/clocksource/clocksource0/available_clocksource echo “acpi_pm” > /sys/devices/system/clocksource/clocksource0/current_clocksource
-
锁 互斥锁和自旋锁。
-
超线程 cat /proc/cpuinfo | grep “core id” 具有相同core id的cpu是同一个core的超线程,通过flags显示有ht选项。 超线程加快了 Linux 的速度
-
GCC中-O1 -O2 -O3 优化的原理是什么?
-finline-small-functions https://www.zhihu.com/question/27090458
- DPDK
https://zh.wikipedia.org/wiki/DPDK
在X86结构中,处理数据包的传统方式是CPU中断方式,即网卡驱动接收到数据包后通过中断通知CPU处理,然后由CPU拷贝数据并交给协议栈。在数据量大时,这种方式会产生大量CPU中断,导致CPU无法运行其他程序。而DPDK则采用轮询方式实现数据包处理过程:DPDK重载了网卡驱动,该驱动在收到数据包后不中断通知CPU,而是将数据包通过零拷贝技术存入内存,这时应用层程序就可以通过DPDK提供的接口,直接从内存读取数据包。这种处理方式节省了CPU中断时间、内存拷贝时间,并向应用层提供了简单易行且高效的数据包处理方式,使得网络应用的开发更加方便。但同时,由于需要重载网卡驱动,因此该开发包目前只能用在部分采用Intel网络处理芯片的网卡中。
- 运算系统的延迟
https://gist.github.com/hellerbarde/2843375
L1 cache reference ……………………. 0.5 ns
Branch mispredict ………………………. 5 ns
L2 cache reference ……………………… 7 ns
Mutex lock/unlock ……………………… 25 ns
Main memory reference …………………. 100 ns
Compress 1K bytes with Zippy …………. 3,000 ns = 3 µs
Send 2K bytes over 1 Gbps network ……. 20,000 ns = 20 µs
SSD random read …………………… 150,000 ns = 150 µs
Read 1 MB sequentially from memory ….. 250,000 ns = 250 µs
Round trip within same datacenter …… 500,000 ns = 0.5 ms
Read 1 MB sequentially from SSD* ….. 1,000,000 ns = 1 ms
上海之间两个机房的网络延时…………….. 1,000,000 ns = 1 ms
Disk seek ……………………… 10,000,000 ns = 10 ms
Read 1 MB sequentially from disk …. 20,000,000 ns = 20 ms
北京到上海的网络延时……………….. 30,000,000 ns = 30 ms
Send packet CA->Netherlands->CA …. 150,000,000 ns = 150 ms
- 低延迟的设计方法
* 限制动态分配内存
* 使用轮询,尽量避免阻塞
* 使用共享内存作为唯一的IPC机制
* 传递消息时使用无锁队列
* 考虑缓存对速度的影响
How long does it take to make a context switch? 这篇博客里面,系统调用只需要<100ns,线程/进程切换需要>1us(不包括缓存miss的时间)
缓存相关
- 缓存算法
注意:各种缓存算法没有优劣之分,需要结合场景使用。
* Least-Recently-Used (LRU): 替换掉**最近被请求最少**的对象。在CPU缓存淘汰和虚拟内存系统中效果很好。新的对象会被放在缓存的顶部,当缓存达到了容量极限,底部的对象被去除。
* Least-Frequently-Used (LFU): 替换掉**访问次数最少**的缓存。即替换掉很少使用的那些数据。
* Least-Recently-Used 2 (LRU2): LRU的变种,把被两次访问过的对象放入缓存,当缓存满了之后,会把有两次最少使用的缓存对象去除。
* Two Queues (2Q): LRU另一个变种,把被访问的对象放到LRU缓存中,如果这个对象再一次被访问,就把它转移到第二个更大的LRU缓存。使用多级缓存的方式。
* LRU-Threshold: 不缓存超过某一size的对象,其他与LRU相同。
分布式系统
分布式系统理论
| 理论方法 | 解决的问题 |
|---|---|
| CAP | 提出一致性,可用性,分区容忍性的取舍问题 |
| Paxos | 一致性的解决方案。是一个解决分布式系统中,多个节点之间就某个值(提案)达成一致(决议)的通信协议。它能够处理在少数节点离线的情况下,剩余的多数节点仍能够达成一致。 |
| Raft | 一致性的解决方案 |
| 2PC/3PC | 一致性的解决方案 |
| Lease机制 | 主要针对网络拥塞或瞬断的情况下,出现双主的情况 |
| Quorum NWR | 解决分布式存储的一致性问题。N: 同一份数据的拷贝份数 W: 更新一个数据对象的时候需要确保成功更新的份数 R: 读取一个数据需要读取的拷贝份数。一般:N=3, R=2, W=2 |
| MVCC | 解决分布式存储的一致性问题。Multiversion concurrency control 基于多版本的并发控制。一般把基于锁(比如行级锁)的并发控制机制称为悲观机制;而把MVCC机制称为乐观机制。由于MVCC是一种宽松的设计,读写互相不阻塞,可以获得好的并发性能 |
| Gossip | 一种去中心化,容错,最终一致的算法。对于集群中出现的部分网络分割,消息也能通过别的路径传播到这个集群 |
| ACID | |
| BASE | Basically Available, Soft state, Eventually consistent (基本可用,软状态,最终一致性) |
| 脑裂问题 | 主备是实现高可用的有效方式,但存在一个脑裂问题。脑裂(split-brain),指在一个HA系统中,当联系着的两个节点断开联系时,本来为一个整体的系统,分裂为两个独立节点,这时两个节点开始争抢共享资源,结果会导致系统混乱,数据损坏 |
分布式系统设计策略
- 如何检查服务可用性 -> 心跳检测(心跳检测是有效资源利用和成本之间的一种权衡),包括
- 周期检测
- 累积失效检测
- 如何保证服务高可用 -> 常用的设计模式,包括
- 主备MS(比如,MySQL)
- 互备MM
- 集群Cluster模式(比如,通过zookeeper主控节点分担服务请求)
- 如何容错处理 -> 对故障的处理,例如,缓存失效导致雪崩的问题
- 一种解决方法,前端在查询某个key时如果一直不存在,可以采取轮询,防止请求透穿到数据库。
- 负载均衡有哪些方案
- 硬件方案,比如,F5
- 软件方案,比如,LVS,HAProxy,Nginx。以Nginx为例,有以下几种策略。
- 轮询(Round Robin)。根据配置文件的顺序,依次访问不同的后端服务器
- 最少连接。当前谁连接最少,就分发给谁
- IP地址哈希。相同IP请求可以转发给同一个后端节点处理,方便session保持
- 基于权重。把请求更多地分发到高权重的服务器上
分布式系统设计实践
- 全局ID生成
- UUID。当前时间 + 时钟序列 + 全局唯一的IEEE机器识别号(比如,网卡)。优点:API简单易用;缺点:占用空间大,字符串本身无法加工,可读性不强。
- ID生成表。使用MySQL自增长ID的机制。启用两台数据库服务器来生成ID,通过区分auto_increment的起始值和步长来生成奇偶数的ID。
CREATE TABLE `Tickets64` (
`id` bigint(20) unsigned NOT NULL auto_increment,
`stub` char(1) NOT NULL default '',
PRIMARY KEY (`id`),
UNIQUE KEY `stub` (`stub`)
)ENGINE=MyISAM
# 应用使用时,保证在一个事务会话里提交
REPLACE INTO Tickets(stub) VALUES('a');
SELECT LAST_INSERT_ID();
* [Snowflake(Twitter)](https://github.com/twitter/snowflake),生成64位的ID = 41位的时间序列 + 10位机器标识(最多支持1024个节点) + 12位的计数顺序号(支持每个节点每毫秒产生4096个ID序号) Snowflake is a network service for generating unique ID numbers at high scale with some simple guarantees.
-
哈希取模
- 好处:只需要通过计算就可以映射出数据和处理节点的关系,不需要存储映射
- 难点:如果id分布不均匀可能出现计算,存储倾斜的问题。同时,迁移数据比较麻烦,会出现大部分数据不能命中的情况
-
一致性哈希
主要解决: * 单调性(哈希的结果应能够保证原有已分配的内容可以被映射到原有缓冲区中去,避免在节点增减过程中导致不能命中)。在一致性哈希算法中,如果一台服务器不可用,则受影响的数据仅仅是此服务器到其环空间中前一台服务器之间数据,其他数据不会受到影响 * 分散性。为了尽可能均匀地分布节点和数据,一种常见的改进算法是引入虚拟节点的概念,系统会创建许多虚拟节点,个数远大于当前节点的个数,均匀分布到一致性哈希值域换上,这样可以使得所有的缓冲空间都得到利用
- 路由表
数据是集中式管理,存在单点风险。如果数据规模小,且数据库本身具备failover能力,此方案可行
- 数据拆分 sharding
由proxy中间件或者数据库内部做数据分片。客户端在使用时认为操作的是一个数据库。
分布式事务相关理论
单机事务
事务,就是一组原子性的SQL查询。如果数据库引擎能够成功地对数据库应用该组查询的全部语句,那么就执行该组查询;如果其中有任何一条语句因为崩溃或其他原因无法执行,那么所有的语句都不会执行。即,事务内的语句,要么全部执行成功,要么全部执行失败。
可以用START TRANSACTION语句开始一个事务,然后要么使用COMMIT提交事务将修改的数据持久保留,要么使用ROLLBACK撤销所有的修改。 事务SQL的样本如下:
START TRANSACTION;
SELECT balance FROM checking WHERE customer_id = 'gerry';
UPDATE checking SET balance = balance - 200.00 WHERE customer_id = 'gerry';
UPDATE savings SET balance = balance + 200.00 WHERE customer_id = 'gerry';
COMMIT;
ACID表示原子性,一致性,隔离性和持久性。一个运行良好的事务处理系统,必须具备这些标准特征。事务的ACID特性可以确保银行不会弄丢你的钱
原子性(atomicity) 对于一个事务来说,不可能只执行其中一部分操作,这就是事务的原子性。
一致性(consistency) 数据库总是从一个一致性的状态转换到另外一个一致性的状态。
隔离性(isolation) 通常来说(根据不同的隔离级别),一个事务所做的修改在最终提交以前,对其他事务是不可见的。
持久性(durability) 一旦事务提交,则其所做的修改就会永久保存在数据库中。
隔离级别
在SQL标准中定义了四种隔离级别。每一种级别都规定了一个事务中所做的修改,哪些在事务内和事务间是可见的,哪些是不可见的。
较低级别的隔离通常可以执行更高的并发,系统的开销也更低。每种存储引擎实现的隔离级别不尽相同,请查阅具体相关手册。
READ UNCOMMITTED(未提交读) 在此级别,事务中的修改即使没有提交,对其他事务也都是可见的,即,“赃读”。(实际应用中,很少使用)
READ COMMITTED(提交读,不可重复读) 大多数数据的默认隔离级别都是此级别(但MySQL不是)。此级别满足隔离性的简单定义:一个事务开始时,只能看见已经提交的事务所做的修改(或者,一个事务从开始直到提交之前,所做的任何修改对其他事务都是不可见的)。此级别,也称为“不可重复读”,因为两次执行同样的查询,可能会得到不一样的结果。
REPEATABLE READ(可重复读) 此级别保证了在同一个事务中,多次读取同样纪录的结果是一致的。此级别,是MySQL的默认事务隔离级别。
SERIALIZABLE(可串行化) 此级别是最高的隔离级别。它通过强制事务串行执行,避免了“幻读”的问题。此级别,会在读取的每一行数据上都加锁,所以可能导致大量的超时和锁争用的问题。(实际应用中也很少使用这个隔离级别,只有在非常需要确保数据的一致性而且可以接受没有并发的情况下,才考虑使用此级别)
分布式事务
https://zhuanlan.zhihu.com/p/34232350
http://www.bytesoft.org/tcc-intro/
XA(作用于数据分片)
数据库MySQL的一种分布式事务能力,使用在资源层。最大的作用在于数据库资源横向扩展时,能保证多资源访问的事务属性。XA 协议通过每个 RM(Resource Manager,资源管理器)的本地事务隔离性来保证全局隔离,并且需要通过串行化隔离级别来保证分布式事务一致性。但是,串行化隔离级别存在一定的性能问题。
Q: 分布式事务场景, 设置成串行化隔离级别, 是否有必要?MySQL默认是RR隔离级别。
set session transaction isolation level SERIALIZABLE;
A: 如果数据库不支持分布式MVCC,就有必要。否则可能RM1的本地事务提交了,RM2还没提交,这样就会读取到RM1已经提交的结果和RM2上未提交的结果,数据就不一致了。
补充说明:数据库为什么要横向扩展(既可以按数据分片扩展,也可以按功能扩展)?当单台 RM 机器达到资源性能瓶颈,无法满足业务增长需求时,就需要横向扩展 RM 资源,形成 RM 集群。通过横向扩展资源,提升非热点数据的并发性能,这对于大体量的互联网产品来说,是至关重要的。基于 XA 协议实现的分布式事务并不能提升热点并发性能,其意义在于横向扩展资源提升非热点数据并发性能时,能严格保证对多资源访问的事务 ACID 特性。至于热点数据并发性能问题,对于一般的应用来说,经过 SQL 层面一定的性能优化之后,其并发性能基本就能够满足业务的需求。如果经过优化,达到性能极限之后,还不能满足,就需要上升到业务层面,根据业务特点,通过专门的业务逻辑或业务架构优化来实现。
xa start xid; // request for db1
update db1.t_user_balance set balance = balance - 1 where user = 'Bob' and balance > 1;
xa start xid; // request for db2
update db2.t_user_balance set balance = balance + 1 where user = 'John';
xa prepare xid; // for db1
xa prepare xid; // for db2
do_other_something(); // db连接可以断开,此时可以做一些其他事情(比如rpc操作),然后再提交db事务
// 如果do_other_something成功,可以提交之前的db事务
xa commit xid; // for db1
xa commit xid; // for db2
// 如果do_other_something失败,需要回滚之前的db事务
xa rollback xid; // for db1
xa rollback xid; // for db2
说明:
* MySQL默认事务隔离级别是REPEATABLE READ(可重复读),在分布式事务场景下,如果数据库不支持分布式mvcc,那就要开启串行化隔离级别(SERIALIZABLE隔离级别),否则会导致读数据不一致。例如,在没有开启s隔离场景下,从`xa start`开始到`xa commit/rollback`期间,涉及修改的记录会加锁,后来的`写事务`会阻塞(即,不可访问),如果不开启s隔离,`读事务`就会读到旧值(通过单机MVCC)。
* 分布式事务的热点数据并发性能最高就是趋近于单机本地事务。所以,无论是基于 XA 协议实现的分布式事务,还是单机本地事务,都是存在热点数据并发性能极限的。
如何解决热点数据问题,例如,ToB的场景?
* 思路1:排队。把操作热点数据的请求排队,比如用单线程处理,避免版本号冲突或加锁问题。
* 思路2:异步。就是引入多个中间账户,扣费的时候操作中间账户,然后再异步把中间账户的数据同步到热点账户。
TCC(作用于功能扩展)
TCC 分布式事务模型直接作用于服务层。不与具体的服务框架耦合,与底层 RPC 协议无关,与底层存储介质无关,可以灵活选择业务资源的锁定粒度,减少资源锁持有时间,可扩展性好,可以说是为独立部署的 SOA 服务而设计的。
优点:
* 跨服务的分布式事务。这一部分的作用与 XA 类似,服务的拆分。
* 两阶段拆分。就是把两阶段拆分成了两个独立的阶段,通过资源业务锁定的方式进行关联。资源业务锁定方式的好处在于,既不会阻塞其他事务在第一阶段对于相同资源的继续使用,也不会影响本事务第二阶段的正确执行。
安全相关
- HTTPS
- Public keys and Private Keys
设计模式
- 单例模式
CoolShell-深入浅出单实例SINGLETON设计模式
容灾方案
- 同城多活 -> 异地多活
https://zhuanlan.zhihu.com/p/32009822 http://www.infoq.com/cn/articles/interview-alibaba-bixuan
other
https://github.com/huihut/interview
C/C++问题:
头文件里可以不可以定义变量。 .c文件可不可以被包含。 宏有什么用,宏可以展开成宏吗? 为什么要有数据对齐? volatile关键字有什么用,能不能直接用来数据同步? restrict关键字? 存储类型说明符?
C++模板参数可以是什么类型? SFINAE规则有什么用? C++中多态怎么实现的?内存布局清楚吗? mutable有什么用?
abi与api的区别 C++类,什么情况下会影响api,什么情况影响abi? C++类声明在头文件中,有个static的成员变量,生成了.a,用这个.a的
静态链接和动态链接?
poll/select/epoll epoll ET和LT模式
tcp分手可不可能是3次。 send, recv能不能用在udp上, bind和listen呢? recv返回0说明什么(tcp,udp)? tcp no delay有什么用? DDOS SYNC攻击原理 自连接问题 udp什么情况下可能丢包? udp需要补齐一些什么功能才能像UDP一样通信?
阻塞/非阻塞,同步/异步
无锁编程,aba,cache line
写磁盘,io优化
linux: 文件描述符和句柄的关系? 系统调用,getpid缓存? 进程间通信方法? 信号处理发生在什么时候,处理信号的时候能不能再收到信号会怎样?什么信号不能捕获? 进程生命周期状态 vfork有什么用?失败了怎么退出? 并发模型,多线程多进程协程
算法: C++的map怎么实现的?avl的区别?其他查找结构 从一个数组中删除指定多个下标的元素,算法,复杂度? 小球称重? 如何快速计算一个数,二进制表示中有多少个1?
订单号服务器的设计
Refer
- https://github.com/0voice/interview_internal_reference