Learning in Action
- 奥卡姆剃刀原则
- 心理
- 电脑自举
- 编程语言
- Site Reliability Engineering (SRE 站点可靠性工程)
- Large Language Model (LLM)
- 迈尔斯-布里格斯类型指标 (Myers-Briggs Type Indicator,MBTI)
- 第一性原理
- 加权轮询 (Weighted Round Robin,WRR)
- 腾讯云网络(基础网络,私有网络)
- Lighthouse (轻量应用服务器)
- 微信的 access_token 和 refresh_token
- MTBF、MTTR、MTTA 和 MTTF
- 手游安全测试 SR (Security Radar)
- STAR 原则
- SCQA 原则
- 职级答辩模版
- 莱斯定理
- ACGI
- 分布式系统唯一ID生成方案
- 圈复杂度
- OAuth 2.0 (授权)
- 软件设计原则
- KISS 原则
- Domain-Driven Design (DDD 领域驱动设计)
- Metric (指标)
- 暗网
- 什么是 UPF
- Refer
奥卡姆剃刀原则
奥卡姆剃刀原理,由威廉·奥卡姆提出,是科学和逻辑学中的一个基本原则,其核心思想是:“如无必要,勿增实体”或“在所有条件相同的情况下,最简单的解释是最好的”。它在面对相互竞争的多个解释时,倡导选择假设最少、最简洁的那个方案,从而帮助排除不必要的复杂性。
奥卡姆剃刀原理也即最简单的方案往往可能就是最正确最好的方案,切勿浪费较多资源去做那些用较少资源也可以做好的事情。
简而言之,就是保持事情的简单性,要驭繁于简,而不要人为地把事情复杂化,自寻烦恼。
奥卡姆剃刀在科研、管理、投资等领域作为一种指导原则而广泛应用,在没有经验证据的状况下,它可以作为一种快速决策和建立真理的手段。在人工智能领域,机器学习的过程中,选择复杂性低一点的数学模型,算法的表现往往会更好。虽然奥卡姆剃刀不是在所有的场合都适用,但它是一个具有启发性的指导原则,其核心意义在于不要将已经很复杂的问题人为地更加复杂化,而在模型上化繁为简是相对正确的途径。
https://zhuanlan.zhihu.com/p/594518492

心理
创伤后应激障碍 (Post-traumatic stress disorder,PTSD)
创伤后应激障碍是指人在经历过情感、战争、交通事故或任何严重事故等创伤事件后产生的精神障碍。其症状包括会出现不愉快的想法、感受或梦,接触相关事物时会有精神或身体上的不适和紧张,会试图避免接触、甚至是摧毁相关的事物,认知与感受的突然改变、以及应激频发等。这些症状往往会在创伤事件发生后出现,且持续一个月以上。
PTSD 的主要症状包括做恶梦、性格大变、情感解离、麻木感(情感上的禁欲或疏离感)、失眠、逃避会引发创伤回忆的事物、暴躁易怒、过度警觉、肌肉痉挛、失忆、易受惊吓,或其再次碰见相似情境时会有呼吸困难、恐惧、害怕、发抖等现象。
电脑自举
电脑启动的那个单词 “boot”,以前的译法就是电脑自举。它是半个词组,来自鞋带 boot strap 的第一个词,boot 就是鞋子。它用典指向十九世纪的一个美国谚语,“抓着鞋带把自己提起来”,类似于咱们说的左脚踩右脚上天的意思。主打一个荒谬,不可能完成的任务。计算机里不乏这种左脚踩右脚上天看似悖论的东西(比如说,如果刚通上电的时候,内存里存储的指令空空如也,那又是“谁的指令”来控制 CPU 把硬盘里的系统启动代码指令加载复制到内存里?)。这种逐级加载,或者逐层提升能力,最后达到完备的自给自足的状态的动作,都可被称为自举。
编程语言
Kotlin
Kotlin 是一种在 Java 虚拟机上执行的静态类型编程语言,它也可以被编译成为 JavaScript 源代码。它主要是由 JetBrains 在俄罗斯圣彼得堡的开发团队所发展出来的编程语言,其名称来自于圣彼得堡附近的科特林岛。2012年1月,著名期刊《Dr. Dobb’s Journal》中 Kotlin 被认定为该月的最佳语言。虽然与 Java 语法并不兼容,但在 JVM 环境中 Kotlin 被设计成可以和 Java 代码相互运作,并可以重复使用如 Java 集合框架等的现有 Java 引用的函数库。Hathibelagal 写道,“如果你正在为 Android 开发寻找一种替代编程语言,那么应该试下 Kotlin。它很容易在 Android 项目中替代 Java 或者同 Java 一起使用。”
Site Reliability Engineering (SRE 站点可靠性工程)
Site reliability engineering (SRE) is a set of principles and practices that applies aspects of software engineering to IT infrastructure and operations. SRE claims to create highly reliable and scalable software systems. Although they are closely related, SRE is slightly different from DevOps.
History:
The field of site reliability engineering originated at Google with Ben Treynor Sloss, who founded a site reliability team after joining the company in 2003. In 2016, Google employed more than 1,000 site reliability engineers. After originating at Google in 2003, the concept spread into the broader software development industry, and other companies subsequently began to employ site reliability engineers. The position is more common at larger web companies, as small companies often do not operate at a scale that would require dedicated SREs.
Definition:
Site reliability engineering, as a job role, may be performed by individual contributors or organized in teams, responsible for a combination of the following within a broader engineering organization: System availability, latency, performance, efficiency, change management, monitoring, emergency response, and capacity planning. Site reliability engineers often have backgrounds in software engineering, system engineering, or system administration. Focuses of SRE include automation, system design, and improvements to system resilience.
Site reliability engineering, as a set of principles and practices, can be performed by anyone. Though everyone should contribute to good practices, as occurs in security engineering, a company may eventually hire specialists and engineers for the job.
Site reliability engineering has also been described as a specific implementation of DevOps, although they differ slightly. SRE focuses specifically on building reliable systems, whereas DevOps focuses more broadly. Although they have different focuses, some companies have rebranded their operations teams to SRE teams with little meaningful change.
DevOps vs. SRE
DevOps is an approach to culture, automation, and platform design intended to deliver increased business value and responsiveness through rapid, high-quality service delivery. SRE can be considered an implementation of DevOps.
Like DevOps, SRE is about team culture and relationships. Both SRE and DevOps work to bridge the gap between development and operations teams to deliver services faster.
Faster application development life cycles, improved service quality and reliability, and reduced IT time per application developed are benefits that can be achieved by both DevOps and SRE practices.
refer:
- https://en.wikipedia.org/wiki/Site_reliability_engineering
- https://www.redhat.com/en/topics/devops/what-is-sre
Large Language Model (LLM)
A large language model (LLM) is a computational model notable for its ability to achieve general-purpose language generation and other natural language processing tasks such as classification. Based on language models, LLMs acquire these abilities by learning statistical relationships from text documents during a computationally intensive self-supervised and semi-supervised training process. LLMs can be used for text generation, a form of generative AI, by taking an input text and repeatedly predicting the next token or word.
LLMs are artificial neural networks. The largest and most capable, as of March 2024, are built with a decoder-only transformer-based architecture.
Up to 2020, fine tuning was the only way a model could be adapted to be able to accomplish specific tasks. Larger sized models, such as GPT-3, however, can be prompt-engineered to achieve similar results. They are thought to acquire knowledge about syntax, semantics and “ontology” inherent in human language corpora, but also inaccuracies and biases present in the corpora.
Some notable LLMs are OpenAI’s GPT series of models (e.g., GPT-3.5 and GPT-4, used in ChatGPT and Microsoft Copilot), Google’s Gemini (the latter of which is currently used in the chatbot of the same name), Meta’s LLaMA family of models, Anthropic’s Claude models, and Mistral AI’s models.
大型语言模型(Large Language Model,LLM)是一种计算模型,以其在一般性语言生成和其他自然语言处理任务(如分类)上的能力而著名。基于语言模型,LLM通过在计算密集型的自监督和半监督训练过程中从文本文档中学习统计关系,从而获得这些能力。LLM可以用于文本生成,这是一种生成型AI,通过接收输入文本并反复预测下一个标记或词。
LLM是人工神经网络。截至2024年3月,最大且最有能力的模型是使用仅解码器的基于Transformer的架构构建的。
到2020年,微调是模型适应特定任务的唯一方式。然而,像GPT-3这样的大型模型可以通过提示工程来实现类似的结果。它们被认为能获取人类语言语料中固有的语法、语义和”本体论”知识,但也会获取语料中存在的不准确性和偏见。
一些著名的LLM包括OpenAI的GPT系列模型(例如,用于ChatGPT和Microsoft Copilot的GPT-3.5和GPT-4)、Google的Gemini(后者目前用于同名聊天机器人)、Meta的LLaMA系列模型、Anthropic的Claude模型,以及Mistral AI的模型。
迈尔斯-布里格斯类型指标 (Myers-Briggs Type Indicator,MBTI)
是人格类型学中一种内省的自我报告问卷,它表明人们天生在感知和决策的方式上存在不同心理偏好。其理论最浅显的部分是四组相反的先天偏好:内向与外向(Introversion-Extraversion)、实感与直觉(Sensing-iNtuition)、思考与情感(Thinking-Feeling)、判断与感知(Judging-Perceiving),四项偏好可组成 16 种稳定的人格类型。该指标旨在让健康个体理解自己和彼此的认知与决策倾向,并不反映能力或品格。
MBTI 是由两名美国人 —— 凯瑟琳·库克·布里格斯和她的女儿伊莎贝尔·布里格斯·迈尔斯所建构,最早于1944年发表。这项指标的理论基础来自瑞士精神科医师兼精神分析师卡尔·荣格(Carl Jung)的著作《心理类型》。
基于荣格的原始概念,布里格斯和迈尔斯开发了她们自己的心理类型理论,组成四个类别——外向/内向(E/I)、实感/直觉(S/N)、思考/情感(T/F)、判断/感知(J/P);根据 MBTI 的论述,每个人在每个类别中各有一个偏好的特质,形成 16 种独特的类型。

第一性原理
第一性原理是一种思考方法,就是要我们从最基本的原理或事实出发,去分析和解决问题。这就像搭积木一样,我们先找到最基本的积木块,然后用这些基本块去搭建更复杂的结构。
拿马斯克造火箭来举例:他一开始想从俄罗斯搞来便宜的火箭,结果俄罗斯人涨价,把马斯克给气的,就开始想:到底制作一枚火箭需要多少钱?回到最原始的部分,火箭是由原材料构成的,比如碳纤维、金属、燃料等,按照目前的制作方式,成品的成本比材料的成本要多出50倍。所以马斯克创造了一个”白痴指数”,即:白痴指数 = 零部件的总成本 / 原材料成本,如果你负责的元器件白痴指数很高,意味着这个员工就是个白痴。白痴指数成了马斯克要求员工降低成本的好办法。
可以看到,第一性原理是一种基于最基本事实和原理的思考方法,用于分析和解决问题。这种方法强调从根本出发,深入理解问题的本质,以实现更有效的问题解决。大白话说就是:不要被现有的假设和模式束缚,要从零开始思考问题的最基本要素。
压缩带来智能
在《对话杨植麟:Moonshot AI即将完成超10亿元融资,公司最终目标并非超越OpenAI》的文章中,杨植麟反复强调了”第一性原理”的重要性,共提及了13次。杨植麟对AI的第一性原理的解释是:”压缩产生智能”。
他以等差数列为例,如果有1万个数字需要压缩,最理想的情况是只需存储等差数列的规律和两个数字,其他9998个数字就能被还原。这意味着,对于所有信息,只要找到合适的方法,进行最大限度的无损压缩,就能实现高度的智能。
加权轮询 (Weighted Round Robin,WRR)
加权轮询(Weighted Round Robin,WRR)是一种负载均衡方法,用于在多个后端服务器之间分配请求。它是轮询(Round Robin)负载均衡方法的扩展,可以根据每个后端服务器的权重分配不同的请求量。权重通常是根据服务器的能力、负载或其他相关指标分配的。
在 WRR 负载均衡中,每个后端服务器都有一个权重值。权重值越高,分配给该服务器的请求就越多。负载均衡器按照权重值循环遍历服务器列表,将请求分配给相应的服务器。
以下是 WRR 负载均衡的基本工作原理:
- 初始化:将每个服务器的权重值存储在一个列表中。
- 请求分配:当收到新的请求时,按照服务器列表中的权重值顺序选择一个服务器。将请求分配给选定的服务器,并减少该服务器的权重值。
- 权重更新:如果权重值减少到 0,将其重置为初始权重值。
- 重复步骤 2 和 3,直到所有请求都被分配。
WRR 负载均衡的优点是它可以根据每个服务器的能力和负载更公平地分配请求。相比于简单的轮询方法,WRR 能更好地处理服务器性能不均匀的情况,避免将过多的请求分配给性能较差的服务器。
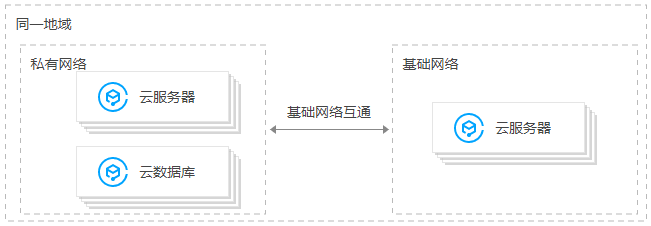
腾讯云网络(基础网络,私有网络)
基础网络互通实现私有网络与基础网络云服务器的通信。通过基础网络互通可实现如下通信场景:
- 基础网络中的云服务器可以访问私有网络中的云服务器、云数据库、内网负载均衡、云缓存等云资源。
- 私有网络内的云服务器,只能访问互通的基础网络云服务器,无法访问基础网络中云数据库、负载均衡等其他云资源。
https://cloud.tencent.com/document/product/215/20083
Lighthouse (轻量应用服务器)
轻量应用服务器(TencentCloud Lighthouse)是新一代开箱即用、面向轻量应用场景的云服务器产品,助力中小企业和开发者便捷高效的在云端构建网站、Web应用、小程序/小游戏、游戏服、电商应用、云盘/图床和开发测试环境,相比普通云服务器更加简单易用且更贴近应用,以套餐形式整体售卖云资源并提供高带宽流量包,将热门开源软件打包实现一键构建应用,提供极简上云体验。
Lighthouse = 云服务器 + 独立IP及流量包 + 开箱即用的应用镜像 - CVM中对于中小客户的过多细节
- https://cloud.tencent.com/product/lighthouse
- 【3秒极速开服】幻兽帕鲁服务器全自动部署保姆教程(含进阶指南)
- 降低云的使用门槛
- VPC / 云硬盘 / 弹性网卡 / 对象存储 / 安全组 / 镜像 / DNS / …
- 贴近应用,贴近开发者
应用场景:
- 网站搭建(预置常用建站软件,快速创建博客,论坛,企业官网等)
- Web 应用(提供常用 Web 开发平台,如 LAMP, Node.js 等的镜像)
- 云端开发测试(帮助开发者随时随地在云端构建即开即用的开发测试环境)
- 云端学习环境(提供 Ubuntu, CentOS, Debian 等环境)
- 小程序后端服务
- 云盘
- 电商
- 中小型游戏后台(云端搭建我的世界,CSGO等游戏服务)
微信的 access_token 和 refresh_token
在微信开发中,access_token 和 refresh_token 是两种不同类型的票据,它们在微信认证和授权过程中起到不同的作用。
access_token 是一个短期有效的票据,用于访问微信 API 以获取用户数据或执行其他操作。它通常在用户授权后立即生成,并具有较短的有效期(通常为 2 小时)。当 access_token 过期时,需要使用 refresh_token 获取一个新的 access_token。
access_token 的主要作用是充当 API 请求的凭证。在调用微信 API 时,需要在请求中携带有效的 access_token,以证明你有权限访问相应的资源或执行操作。
refresh_token 是一个长期有效的票据,用于在 access_token 过期后获取一个新的 access_token。refresh_token 的有效期通常比 access_token 长得多(通常为 30 天或更长)。
当 access_token 过期时,可以使用 refresh_token 向微信服务器请求一个新的 access_token,而无需再次让用户进行授权。这样可以避免频繁地请求用户授权,提高用户体验。
总结一下,access_token 和 refresh_token 的区别如下:
- access_token 是短期有效的票据,用于访问微信 API;而 refresh_token 是长期有效的票据,用于在 access_token 过期后获取新的 access_token。
- access_token 的有效期较短,通常为 2 小时;而 refresh_token 的有效期较长,通常为 30 天或更长。
- 使用 refresh_token 可以在 access_token 过期后获取新的 access_token,而无需再次让用户进行授权。
MTBF、MTTR、MTTA 和 MTTF
了解一些最常见的事件指标
在当今永不停机的世界中,中断和技术事件比以往任何时候都更加重要。故障和停机期间会带来现实后果,错过截止时间、付款逾期、项目延迟。
这就是为什么公司必须量化和跟踪有关正常运行时间、停机期间以及团队解决问题的速度和有效性的指标。
业界最常跟踪的一些指标包括 MTBF(平均故障间隔时间)、MTTR(平均恢复、修复、响应或解决时间)、MTTF(平均故障时间)和 MTTA(平均确认时间),这一系列指标旨在帮助技术团队了解事件发生的频率以及团队从这些事件中恢复的速度。
许多专家认为,这些指标本身其实没有那么有用,因为它们不会问一些更难的问题,比如如何解决事件、哪些有效、哪些无效,以及问题升级或降级的方式、时间和原因。
另一方面,MTTR、MTBF 和 MTTF 可以作为良好的基线或基准,启动对话,引发更深层次的重要问题。
MTBF(故障间隔时间) 尽量长,MTTR(修复问题时间) 尽量短,MTTA(定位问题时间)尽量短,MTTF(平均故障时间)尽量长。
https://www.atlassian.com/zh/incident-management/kpis/common-metrics
MTBF (平均故障间隔时间)
平均故障间隔时间是多少?
MTBF(平均故障间隔时间)是技术产品两次可修复故障之间的平均时间。该指标用于跟踪产品的可用性和可靠性。两次故障之间的时间越长,系统就越可靠。
大多数公司的目标是尽可能保持较高的 MTBF,两次问题之间间隔数十万小时(甚至数百万小时)。
如何计算平均故障间隔时间
MTBF 是使用算术平均值计算的。基本上,这意味着从您要计算的时间段(可能是六个月、一年、也许五年)中提取数据,然后将该时段的总运行时间除以故障次数。
因此,假设我们评估的是 24 小时的时间段,在两次不同的事件中有两个小时的停机期间。我们的总正常运行时间为 22 小时。除以二,等于 11 个小时。所以我们的 MTBF 是 11 个小时。
由于该指标用于跟踪可靠性,因此 MTBF 不考虑定期维护期间的预期停机时间。相反,它侧重于意外的中断和问题。
平均故障间隔时间的起源
MTBF 来自航空业,在该行业,系统故障不仅会导致高昂的成本,甚至还会危及人的生命。从那以后,这种首字母缩略语已遍及各种技术和机械行业,尤其是经常用于制造业。
如何以及何时使用平均故障间隔时间
MTBF 对于想要确保获得最可靠的产品、驾驶最可靠的飞机或为工厂选择最安全的制造设备的买家很有帮助。
对于内部团队而言,它是一种有助于确定问题和跟踪成功与失败的指标。它还可以帮助公司就客户何时应该更换部件、升级系统或维护产品提出明智的建议。
MTBF 是衡量可修复系统故障的指标。对于需要更换系统的故障,人们通常使用术语 MTTF(平均故障时间)。
例如,汽车发动机。计算发动机计划外维护之间的时间时,应使用 MTBF(平均故障间隔时间)。计算更换整台发动机之间的时间时,应使用 MTTF(平均故障时间)。
MTTR (平均修复时间)
注意:我们在谈论 MTTR 时,很容易假设它是一个含义单一的指标。但事实是,它可能代表了四种不同的衡量标准。R 可以代表修复、恢复、响应或解决,虽然这四个指标确实重叠,但它们都有自己的含义和细微差别。
因此,MTTR 可能表示:平均修复时间,平均恢复时间,平均解决时间,平均响应时间。以下以平均修复时间为例进行解释。
平均修复时间是多少?
MTTR(平均修复时间)是修复系统(通常是技术或机械)所需的平均时间。这包括修复时间和任何测试时间。直到系统恢复完全正常运行,此指标才会停止计时。
如何计算平均修复时间
您可以通过将任何给定时间段内的总修复时间相加,然后将该时间除以修复次数来计算 MTTR。
因此,假设我们正在考虑一周内的修复。在这段时间里,发生了十次中断,系统修复花了四个小时。四小时等于 240 分钟。240 除以 10 等于 24。这意味着在这种情况下,平均修复时间为 24 分钟。
平均修复时间的限制
平均修复时间并不总是与系统中断本身的时间相同。某些情况下,修复会在产品故障或系统中断后的几分钟内开始。在其他情况下,在问题出现、检测到问题和开始修复之间会有一段时间间隔。
此指标在跟踪维护人员修复问题的速度时最有用。它并不是要识别系统警报问题或修复前延迟,这两者也是评估事件管理计划成败的重要因素。
如何以及何时使用平均修复时间
MTTR(平均恢复时间)是支持和维护团队用来保持维修按计划进行的一项指标。目标是通过提高维修流程和团队的效率来尽可能降低这个数字。
MTTA (平均确认时间)
平均确认间隔时间是多少?
MTTA(平均确认时间)是从触发警报到开始处理问题所花费的平均时间。此指标可用于跟踪团队的响应能力和警报系统的有效性。
如何计算平均确认时间
要计算您的 MTTA,请将警报和确认之间的时间相加,然后除以事件数。
例如:如果您有 10 个事件,而所有 10 个事件的警报和确认之间总共有 40 分钟,则将 40 除以 10 得出平均值 4 分钟。
如何以及何时使用平均确认时间
MTTA 在跟踪响应速度方面很有用。您的团队是否受警报疲劳困扰并且响应时间过长?此指标将帮助您标记问题。
MTTF (平均故障时间)
平均故障时间是多少?
MTTF(平均故障时间)是技术产品两次不可修复得故障之间的平均时间。例如,如果 X 品牌的汽车发动机在完全失效且必须更换之前平均为 500,000 小时,则发动机的 MTTF 将达为 500,000。
该计算用于了解系统通常会持续多长时间,确定新版本的系统性能是否优于旧版本,并向客户提供有关预期使用寿命以及何时安排系统检查的信息。
如何计算平均故障时间
平均故障时间是算术平均值,因此您可以通过将正在评估的产品的总运行时间相加,然后将该总运行时间除以设备数量来计算。
例如:假设您在计算灯泡的 MTTF。Y 品牌的灯泡在烧坏之前平均能持续多长时间?假设您有四个灯泡的样本需要测试(如果您想要具有统计学意义的数据,那您需要的远不止于此,但为了简单的数学目的,我们保持这个小值)。
灯泡 A 持续 20 个小时。灯泡 B 持续 18 个小时。灯泡 C 持续 21 个小时。灯泡 D 持续 21 个小时。总共 80 个小时。除以四,MTTF 为 20 个小时。

平均故障时间问题
通过灯泡这种例子可以看出,MTTF 是一个很有意义的指标。我们可以运行灯泡直到最后一个灯泡出现故障,然后利用这些信息得出关于灯泡弹性的结论。
但是,当我们测量那些不会很快出现故障的东西时会发生什么?那些本来可以使用很多年的东西。对于这些情况,尽管经常使用 MTTF,但它并不是一个很好的指标。因为在大多数情况下,我们不是在产品出现故障之前一直运行产品,而是要在规定的时间长度内运行产品,并测量有多少产品出现故障。
例如:假设我们正在尝试获取 Z 品牌平板电脑上的 MTTF 统计数据。希望平板电脑能用很多年。但是 Z 品牌可能只有六个月时间来收集数据。因此,他们对 100 台平板电脑进行了六个月的测试。假设一台平板电脑恰好在六个月期限出现故障。
因此,我们计算总使用时间(六个月乘以 100台平板电脑),得出 600 个月。只有一台平板电脑出现故障,所以我们将其除以一,那么我们的 MTTR 将为 600 个月,也就是 50 年。
Z 品牌的平板电脑每台能平均使用 50 年吗?不太可能。因此,在这样的情况下,指标会被分解。
如何以及何时使用平均故障时间
当您尝试评估寿命较短的产品和系统(例如灯泡)的平均寿命时,MTTF 很好用。它也仅适用于评估全部产品故障的情况。如果您要计算需要修复的事件之间的间隔时间,可以使用 MTBF(平均故障间隔时间)。
MTBF vs. MTTR vs. MTTF vs. MTTA (总结)
那么,在跟踪和改善事件管理方面,哪种衡量标准更好呢?
答案是全部。
虽然它们有时可以互换使用,但每个指标都提供了不同的见解。组合使用时,它们可以更完整地讲述您的团队在事件管理方面的成功程度以及团队可以改进的地方。
![]()
平均响应时间,您就可以知道有多少恢复时间属于团队,多少属于您的警报系统。
再加上平均修复时间,您就能开始了解团队在修复和诊断上花了多少时间。
再加入平均故障间隔时间,信息就会更详尽,显示您的团队在预防或减少未来问题方面的成功程度。
然后再加上平均故障时间,了解产品或系统的整个生命周期。
手游安全测试 SR (Security Radar)
手游安全测试(Security Radar)为企业提供私密安全测试服务,通过主动挖掘游戏业务安全漏洞(诸如钻石盗刷、服务器宕机、无敌秒杀等40多种漏洞),提前暴露游戏潜在安全风险,提供解决方案及时修复,最大程度降低事后外挂危害与外挂打击成本。该服务为腾讯游戏开放的独家手游安全漏洞挖掘技术,杜绝游戏外挂损失。
http://www.baiemai.com/product/sr-idx=1.htm
STAR 原则
- Situation,你为什么做这件事
- Task,你负责哪部分
- Action,你主要做了什么
- Result,最终有什么成果
Situation 项目背景目标(项目产生的原因及存在的冲突)-> Task 项目角色任务(基于项目目标确定任务及个人角色定位)-> Action 项目重要行动(围绕项目任务所产生的主要行动)-> Result 项目成果(项目最终产出的成果以及影响力)
SCQA 原则
- Situation,现状是什么样的(目前处于什么状态,遇到什么情况)
- Complication,现状和目标有差距(实际情况往往和我们的要求有冲突)
- Question,要解决什么问题(这些冲突导致了什么问题,怎么办)
- Answer,怎么解决问题(我们的解决方案是什么)
职级答辩模版
- 个人经历概述。简要介绍个人信息和工作简历。
- 主要工作成果。讲述最成功最能体现个人专业能力要求的项目或成果(包括项目背景价值,过程中的调整,数据分析,逻辑推演,重要决策)。
- 专业影响和贡献。包括方法论积累和传承,专业课程开发或讲授,人才培养,其他贡献等。
- 专业领域特长与不足。根据能力标准,总结个人能力的优势与不足。
莱斯定理
In computability theory, Rice’s theorem states that all non-trivial semantic properties of programs are undecidable. A semantic property is one about the program’s behavior (for instance, does the program terminate for all inputs), unlike a syntactic property (for instance, does the program contain an if-then-else statement). A property is non-trivial if it is neither true for every program, nor false for every program.
In other terms, it tells us that it’s impossible to create a computer program that can reliably decide certain interesting things about other programs. Specifically, when it comes to aspects like how a program behaves during its execution, there’s no universal method to determine if a program has a particular, more intricate trait. If you have a property that applies to formal languages, and there’s at least one example of a language with that property and one without, determining if a given Turing machine has that property becomes an undecidable problem.
Rice 定理是计算理论中的一个重要定理,它阐述了程序的所有非平凡语义属性都是不可判定的。这里的语义属性是指程序的行为特性,比如程序是否对所有输入都会终止,而非语法属性,比如程序是否包含 if-then-else 语句。非平凡属性是指既不对所有程序都为真,也不对所有程序都为假的属性。
换句话说,Rice 定理告诉我们,我们无法创建一个计算机程序,可以可靠地判断其他程序的某些有趣的事情。具体来说,当涉及到程序在执行过程中的行为时,没有通用的方法可以确定一个程序是否具有特定的,更复杂的特性。如果你有一个适用于形式语言的属性,并且至少有一个语言具有该属性和一个没有,那么确定一个给定的图灵机是否具有该属性就成为一个不可判定的问题。
这个定理大致的意思就是:对于有意义的程序属性,我们都无法判定。
refer:
https://en.wikipedia.org/wiki/Rice%27s_theorem
ACGI
AIGC(AI-Generated Content)可以自动生成各种文本内容,如文章、新闻、产品描述、广告语等,它使用人工智能技术,通过对大量文本数据的学习和分析来生成通顺、连贯、语法正确的文本内容。对于需要大量重复性内容的场景(如电商平台的商品描述、新闻媒体的稿件生成等),它能大幅提高内容创作效率。AIGC 工具的实现方式有很多种,如基于语言模型的自动生成文本、基于模板的文本生成、基于知识图谱的自动生成文本等。随着技术的不断进步,AIGC 工具在自动生成文本方面的能力也在不断提升,能够生成更加贴近人类写作风格的文本内容。
分布式系统唯一ID生成方案
常见方案:
- 数据库自增长序列或字段
- UUID。UUID (Universally Unique Identifier) 的标准型式包含 32 个 16 进制数字,以连字号分为五段,形式为8-4-4-4-12的 36 个字符(32 + 4)
- 不易于存储。UUID太长,16 字节 128 位,通常以 36 长度的字符串表示,很多场景不适用。示例:
550e8400-e29b-41d4-a716-446655440000 - 信息不安全。基于 MAC 地址生成 UUID 的算法可能会造成 MAC 地址泄露,这个漏洞曾被用于寻找梅丽莎病毒的制作者位置
- ID 作为主键时在特定的环境会存在一些问题
- 做 DB 主键的场景下,UUID 就非常不适用。MySQL 官方有明确的建议主键要尽量越短越好,36 个字符长度的 UUID 不符合要求
- 对 MySQL 索引不利,如果作为数据库主键,在 InnoDB 引擎下,UUID 的无序性可能会引起数据位置频繁变动,严重影响性能
- 到目前为止业界一共有 5 种方式生成 UUID,详情见 IETF 发布的 UUID 规范 A Universally Unique IDentifier (UUID) URN Namespace
- 不易于存储。UUID太长,16 字节 128 位,通常以 36 长度的字符串表示,很多场景不适用。示例:
- Twitter 的 snowflake 算法
- Redis生成ID。可以用 Redis 的原子操作 INCR 和 INCRBY 来实现
- 利用 Zookeeper 生成唯一ID。主要通过其 znode 数据版本来生成序列号,可以生成32位和64位的数据版本号,客户端可以使用这个版本号来作为唯一的序列号
- MongoDB 的 ObjectId,和 snowflake 算法类似
参考方案:
- https://www.cnblogs.com/haoxinyue/p/5208136.html
- https://tech.meituan.com/2017/04/21/mt-leaf.html (美团方案)
- https://github.com/baidu/uid-generator (百度方案)
圈复杂度
圈复杂度(Cyclomatic complexity,CC)也称为条件复杂度,是一种衡量代码复杂度的标准,其符号为V(G)。
麦凯布最早提出一种称为“基础路径测试”(Basis Path Testing)的软件测试方式,测试程序中的每一线性独立路径,所需的测试用例个数即为程序的圈复杂度。
圈复杂度可以用来衡量一个模块判定结构的复杂程度,其数量上表现为独立路径的条数,也可理解为覆盖所有的可能情况最少使用的测试用例个数。
圈复杂度与出错风险
程序的可能错误和高的圈复杂度有着很大关系,圈复杂度最高的模块和方法,其缺陷个数也可能最多。圈复杂度大说明程序代码的判断逻辑复杂,可能质量低,且难于测试和维护。一般来说,圈复杂度大于10的方法存在很大的出错风险。
| 圈复杂度 | 代码状况 | 可测性 | 维护成本 |
|---|---|---|---|
| 1 - 10 | 清晰 | 高 | 低 |
| 10 - 20 | 复杂 | 中 | 中 |
| 20 - 30 | 非常复杂 | 低 | 高 |
| > 30 | 不可读 | 不可测 | 非常高 |
圈复杂度与测试
测试驱动的开发与较低圈复杂度值之间存在着紧密联系。因为在编写测试用例时,开发人员会首先考虑代码的可测试性,从而倾向编写简单的代码(因为复杂的代码难以测试)。一个好的测试用例设计经验是:创建数量与被测代码圈复杂度值相等的测试用例,以此提升测试用例对代码的分支覆盖率。
圈复杂度的计算方法
圈复杂度有两种计算方法:
- 点边计算法:圈复杂度由程序的控制流图来计算:有向图的节点对应程序中个别的代码,而若一个程序运行后会立刻运行另一代码,则会有边连接另一代码对应的节点。E 表示控制流图中边的数量,N 表示控制流图中节点的数量。圈复杂度的计算公式为:V(G) = E - N + 2
- 节点判定法:圈复杂度的计算还有另外一种更直观的方法,因为圈复杂度所反映的是“判定条件”的数量,所以圈复杂度实际上就是等于判定节点的数量再加上1。对应的计算公式为:V(G) = P + 1。
- 其中 P 为判定节点数,常见的判定节点有:
- if 语句
- while 语句
- for 语句
- case 语句
- catch 语句
- and 和 or 布尔操作
- ? : 三元运算符
- 对于多分支的 case 结构或 if - else if - else 结构,统计判定节点的个数时需要特别注意:必须统计全部实际的判定节点数,也即每个 else if 语句,以及每个 case 语句,都应该算为一个判定节点。
- 其中 P 为判定节点数,常见的判定节点有:
降低圈复杂度的方法
常用的方法有:
- 简化、合并条件表达式
- 将条件判定提炼出独立函数
- 将大函数拆成小函数
- 以明确函数取代参数
- 替换算法
refer:
- https://zhuanlan.zhihu.com/p/139386961
OAuth 2.0 (授权)
OAuth 是一个关于授权(authorization)的开放网络标准,在全世界得到广泛应用,目前的版本是 2.0 版。OAuth 2.0 是目前最流行的授权机制,用来授权第三方应用,获取用户数据。
简单说,OAuth 就是一种授权机制。数据的所有者告诉系统,同意授权第三方应用进入系统,获取这些数据。系统从而产生一个短期的进入令牌(token),用来代替密码,供第三方应用使用。
令牌(token)与密码(password)的作用是一样的,都可以进入系统,但是有三点差异。
- 令牌是短期的,到期会自动失效,用户自己无法修改。密码一般长期有效,用户不修改,就不会发生变化。
- 令牌可以被数据所有者撤销,会立即失效。以上例而言,屋主可以随时取消快递员的令牌。密码一般不允许被他人撤销。
- 令牌有权限范围(scope),比如只能进小区的二号门。对于网络服务来说,只读令牌就比读写令牌更安全。密码一般是完整权限。
上面这些设计,保证了令牌既可以让第三方应用获得权限,同时又随时可控,不会危及系统安全。这就是 OAuth 2.0 的优点。
注意,只要知道了令牌,就能进入系统。系统一般不会再次确认身份,所以令牌必须保密,泄漏令牌与泄漏密码的后果是一样的。 这也是为什么令牌的有效期,一般都设置得很短的原因。
软件设计原则
软件设计原则,说到底不外乎,模块内高内聚,模块间去耦合。下面是学院派总结的一些原则。

KISS 原则
KISS (Keep It Simple, Stupid) 是一种归纳过的经验原则。KISS 原则是指在设计当中应当注重简约的原则。总结工程专业人员在设计过程中的经验,大多数系统的设计应保持简洁和单纯,而不掺入非必要的复杂性,这样的系统运作成效会取得最优;因此简单性应该是设计中的关键目标,尽量回避免不必要的复杂性。
Domain-Driven Design (DDD 领域驱动设计)
在《领域驱动设计·软件核心复杂性应对之道》这本书里,对什么是“领域”,只有简单的一句话:“每个软件程序是为了执行用户的某项活动,或是满足用户的某种需求。这些用户应用软件的问题区域就是软件的领域。” 除此之外,讲的更多的是“模型” 或者“领域模型”,纵观全书,“Model-Driven Design” 是其核心概念之一。某种程度上,把“领域驱动设计”改为“模型驱动设计”,一点问题都没有,甚至“模型驱动设计”更能体现整本书的精髓。
总的来说,“领域”这个词可能承载了太多含义。领域既可以表示整个业务系统,也可以表示其中的某个核心域或者支撑子域。
Metric (指标)
counter是个计数器,用于统计累计量。counter 主要用于统计某类指标的数量,它将保存从系统启动开始持续的累加值。支持对 counter 进行 +1, -1, +n, -n 的操作。gauge是一个瞬时值,用于统计时刻量。timer是根据一个操作的开始时间,结束时间,统计某个操作的耗时情况。histogram是根据预先划分好的 buckets,将收集到的样本点放入到对应的 bucket 中,这样可以方便查看不同区间(bucket 的上下界)的样本数量,平均值,最大值,最小值等,各个区间的具体值由统计策略决定。 histogram(直方图)用于统一某类指标的分布情况,如最大,最小,平均值,标准差,以及各种分位数,例如 90%,95% 的数据分布在某个范围内。
直方图输出示例说明:
msg_step1_ms:histogram #0:ZERO
msg_step1_ms:histogram #1: 230/0.871 0/0.000 0/0.000 0/0.000 0/0.000 34/0.129
msg_step1_ms:num=2 vals(avg,max,min)=(0,0,0) (8440,65535,0)
msg_step1_ms:histogram border: (-INF,10,100,500,1000,5000,+INF)
msg_step1_ms:histogram total(para_num=2): 230/0.871 0/0.000 0/0.000 0/0.000 0/0.000 34/0.129
这是一个监控信息的输出,使用了直方图(histogram)来表示数据的分布。直方图是一种统计工具,用于可视化数据的频率分布。
msg_step1_ms:histogram #0:ZERO:这表示在第一个区间(负无穷到10毫秒)内,没有任何数据点。
msg_step1_ms:histogram #1: 230/0.871 0/0.000 0/0.000 0/0.000 0/0.000 34/0.129:这表示在第二个区间(10毫秒到100毫秒)内,有230个数据点,占总数据点的87.1%。在后续的区间(100毫秒到500毫秒,500毫秒到1000毫秒,1000毫秒到5000毫秒)内,没有任何数据点。在最后一个区间(5000毫秒到正无穷)内,有34个数据点,占总数据点的12.9%。
msg_step1_ms:num=2 vals(avg,max,min)=(0,0,0) (8440,65535,0):这表示在两个区间内,平均数(avg)、最大值(max)和最小值(min)分别为0、0、0和8440、65535、0。
msg_step1_ms:histogram border: (-INF,10,100,500,1000,5000,+INF):这表示直方图的边界值。数据被分成了几个区间,边界值为负无穷、10毫秒、100毫秒、500毫秒、1000毫秒、5000毫秒和正无穷。
msg_step1_ms:histogram total(para_num=2): 230/0.871 0/0.000 0/0.000 0/0.000 0/0.000 34/0.129:这是对所有区间的总结。总共有2个参数,第一个区间有230个数据点,占总数据点的87.1%;后续的几个区间没有数据点;最后一个区间有34个数据点,占总数据点的12.9%。
这个监控信息提供了 msg_step1_ms 这个指标的详细统计信息,包括数据的分布、平均值、最大值和最小值等。
主调监控:指的是当前服务调用下游服务请求的 client 端的监控,从发起请求到收到下游回包的监控
被调监控:指的是当前服务接收上游服务请求的 server 端的监控,从收到请求到业务逻辑结束的监控
暗网
暗网(Dark Web)是指互联网上的一部分内容,这些内容无法通过常规的搜索引擎或浏览器访问,需要使用特定的软件或配置才能访问。暗网中的内容通常是非常难以追踪和监管的,因此被用于非法活动和犯罪行为。
暗网的访问方式通常是通过使用特定的软件,如 Tor(The Onion Router)等匿名网络工具,来隐藏用户的真实 IP 地址和位置信息,从而保护用户的隐私和匿名性。暗网中的内容包括非常多样化的信息,如非法商品交易、毒品交易、黑客工具、恶意软件、色情内容、极端主义宣传等等。
需要注意的是,暗网并不等同于黑客或犯罪行为,但由于其匿名性和难以追踪性,暗网中的内容往往容易被用于非法活动和犯罪行为。因此,访问暗网需要谨慎,并遵守当地法律法规。
什么是 UPF
UPF 是防紫外线伞重要指标,目前国内外的标准对纺织品的防紫外线性能一般都使用 UPF 值表示,即紫外线防护系数值进行评定。UPF 值是紫外线对未防护的皮肤的平均辐射量的比值,UPF 值越大,表明防紫外线性能越好。国家质检总局颁布的《纺织品防紫外线性能的评定》规定,只有 UPF (紫外线防护系数值) 大于 40,并且 UVA (长波紫外线) 透过率小于 5% 时,才能称为防紫外线产品,防护等级标准为 UPF40+。当 UPF 大于 50 时,表明产品紫外线防护性能极佳,防护等级标识为 UPF50+。
Refer
- https://github.com/chen3feng/article