CPP in Action
- 经验
- 环境要求
- 标准参考
- 核心概念
- 值语义和引用语义
- 异常处理
- 堆栈及布局
- RAII
- 移动语义
- 智能指针
- 普通容器
- 需要函数对象的容器
- 异常
- 迭代器
- C++易用性改进
- 到底应不应该返回对象?
- Unicode:进入多文字支持的世界
- 编译期多态:泛型编程和模板入门
- RTTI(运行期)
- 编译期计算(模板元编程)
- SFINAE:不是错误的替换失败是怎么回事?
- constexpr:一个常态的世界
- 函数对象和lambda:进入函数式编程
- 函数式编程:一种越来越流行的编程范式
- 应用可变模板和tuple的编译期技巧
- thread和future:领略异步中的未来
- 内存模型和atomic:理解并发的复杂性
- 处理数据类型变化和错误:optional、variant、expected和Herbception
- 数字计算
- Boost:你需要的“瑞士军刀”
- 单元测试
- 日志库
- 工具漫谈:编译、格式化、代码检查、排错各显身手
- STL
- 代码片段
- 内联汇编
- 编译器
- 网络
- 文档
- 开源
- 文章
- 汇编
- C++好书荐读
- 一万小时定律
- 程序员该有的三大美德
- 专栏
- Refer
经验
- 对于完成相同的功能,C++需要的代码行数一般是Python的三倍,而性能则可达到其十倍以上。
- 当目标服务属于运算密集型或者内存密集型,需要性能且愿意为性能付出额外代价的时候,应该考虑使用C++。
- C++是解决性能的利器,尤其在大公司和金融机构里。C++之父Bjarne Stroustrup目前就职的地方便是摩根斯坦利。
- 学习C++就像学习一门外语,你不要期望能够掌握所有的单词和语法,因此需要多看多写掌握合适的“语感”,而不是记住所有规则。
- Bjarne有一个洋葱理论,抽象层次就像一个洋葱,是层层嵌套的。如果想用较低的抽象层次表达较高的概念,就好比一次切过了很多层洋葱,会把自己的眼泪熏出来。因此主张学习应该自顶向下,先学习高层的抽象,再层层剥茧,丝丝入扣地一步步进入下层。
- C++强大背后
环境要求
- GCC 8.3
- Clang 9.0
- Visual Studio 2019 16.3 (MSVC 19.23)
标准参考
- 编译器对标准的支持情况 https://en.cppreference.com/w/cpp/compiler_support
- C++ Standards Support in GCC
- 实例化展示工具 https://cppinsights.io/
- 在线多语言编译服务 https://wandbox.org/
- Compiler Explorer
- Compare C++ Builds
- Quick C++ Benchmark
- GCC reference
- C++ language references
- Boost libraries references
核心概念
值语义和引用语义
- 在C++里所有变量缺省都是
值语义,如果不使用*和&的话,变量不会像Java或Python一样引用一个堆上的对象。 - 对于像
智能指针这样的类型,写ptr->call()和ptr.get(),语法上都是对的。而在大部分其他语言里,访问成员只用.。
异常处理
- 通过
异常能够将问题的检测和问题的解决分离,这样程序的问题检测部分可以不必了解如何处理问题。 - C++的异常处理中,需要由问题检测部分
抛出一个对象给处理代码,通过这个对象的类型和内容,两个部分能够就出现了什么错误进行通信。 - 异常是通过抛出(throw)对象而引发(raise)的,该对象的类型决定应该激活哪个处理代码,被选中的处理代码是调用链中与该对象类型匹配且离抛出异常位置最近的那个。
堆栈及布局
- 本地变量所需内存在栈上分配,和函数执行所需的其他数据在一起。当函数执行完这些内存也就自然释放掉。
- 本地变量,包括简单类型
POD(Plain Old Data)和非POD类型(有构造和析构的类型),栈上的内存分配是一样的,只不过C++编译器会在生成代码的合适位置插入对构造和析构函数的调用 - 编译器会自动调用析构函数,包括在函数执行发生异常时。在发生异常时对析构函数的调用,称为
栈展开(stack unwinding) - 栈上的分配简单,移动栈指针而已;栈上的释放也简单,函数执行结束时移动一下栈指针
- 由于后进先出的执行过程,栈的分配不可能出现内存碎片
- 本地变量,包括简单类型
例子:栈展开
#include <cstdio>
class obj {
public:
obj() { puts("obj()"); }
~obj() { puts("~obj()"); }
};
void foo(int n)
{
obj o;
if (n == 1) {
throw "exception";
}
}
int main()
{
try {
foo(0);
foo(1);
} catch (const char* err) {
puts(err);
}
}
/*
$ g++ -o stack_unwinding stack_unwinding.cpp
$ ./stack_unwinding
obj()
~obj()
obj()
~obj()
exception
*/
- 参考《程序员的自我修养》,栈的地址比堆高,栈是向下增长的,堆是向上增长的。但是在Windows上测试却不是。
测试代码:
#include <iostream>
#include <vector>
using namespace std;
int main()
{
double a0[4] = {1.2, 2.4, 3.6, 4.8};
double a1[4] = {1.2, 2.4, 3.6, 4.8};
vector<double> a2(4);
vector<double> a3(4);
a2[0] = 1.0/3.0;
a2[1] = 1.0/5.0;
a2[2] = 1.0/7.0;
a2[3] = 1.0/9.0;
a3[0] = 1.0/3.0;
a3[1] = 1.0/5.0;
a3[2] = 1.0/7.0;
a3[3] = 1.0/9.0;
cout << "a0[2]: " << a0[2] << " at " << &a0[2] << endl;
cout << "a1[2]: " << a1[2] << " at " << &a1[2] << endl;
cout << "a1[3]: " << a1[3] << " at " << &a1[3] << endl;
cout << "a2[2]: " << a2[2] << " at " << &a2[2] << endl;
cout << "a2[3]: " << a2[3] << " at " << &a2[3] << endl;
cout << "a3[2]: " << a3[2] << " at " << &a3[2] << endl;
cout << "a3[3]: " << a3[3] << " at " << &a3[3] << endl;
return 0;
}
Windows的输出:
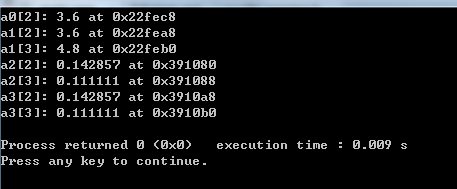
Linux的输出:
a0[2]: 3.6 at 0x7ffe0bbce190
a1[2]: 3.6 at 0x7ffe0bbce170
a1[3]: 4.8 at 0x7ffe0bbce178
a2[2]: 0.142857 at 0x1b64020
a2[3]: 0.111111 at 0x1b64028
a3[2]: 0.142857 at 0x1b64050
a3[3]: 0.111111 at 0x1b64058
-
进程地址空间的分布取决于操作系统,栈向什么方向增长取决于操作系统与CPU的组合。不要把别的操作系统的实现方式套用到Windows上。x86硬件直接支持的栈确实是“向下增长”的:push指令导致sp自减一个slot,pop指令导致sp自增一个slot。其它硬件有其它硬件的情况。 -
栈的增长方向与栈帧布局。这个上下文里说的“栈”是函数调用栈,是以“栈帧”(stack frame)为单位的。每一次函数调用会在栈上分配一个新的栈帧,在这次函数调用结束时释放其空间。被调用函数(callee)的栈帧相对调用函数(caller)的栈帧的位置反映了栈的增长方向:如果被调用函数的栈帧比调用函数的在更低的地址,那么栈就是向下增长;反之则是向上增长。
-
而在一个栈帧内,局部变量是如何分布到栈帧里的(所谓栈帧布局,stack frame layout),这完全是编译器的自由。至于数组元素与栈的增长方向:C与C++语言规范都规定了数组元素是分布在连续递增的地址上的。
An array type describes a contiguously allocated nonempty set of objects with a particular member object type, called the element type. A postfix expression followed by an expression in square brackets [] is a subscripted designation of an element of an array object. The definition of the subscript operator [] is that E1[E2] is identical to
(*((E1)+(E2))). Because of the conversion rules that apply to the binary + operator, if E1 is an array object (equivalently, a pointer to the initial element of an array object) and E2 is an integer, E1[E2] designates the E2-th element of E1 (counting from zero).
- 以简化的Linux/x86模型为例。在简化的32位Linux/x86进程地址空间模型里,(主线程的)栈空间确实比堆空间的地址要高——它已经占据了用户态地址空间的最高可分配的区域,并且向下(向低地址)增长。借用Gustavo Duarte的Anatomy of a Program in Memory里的图。
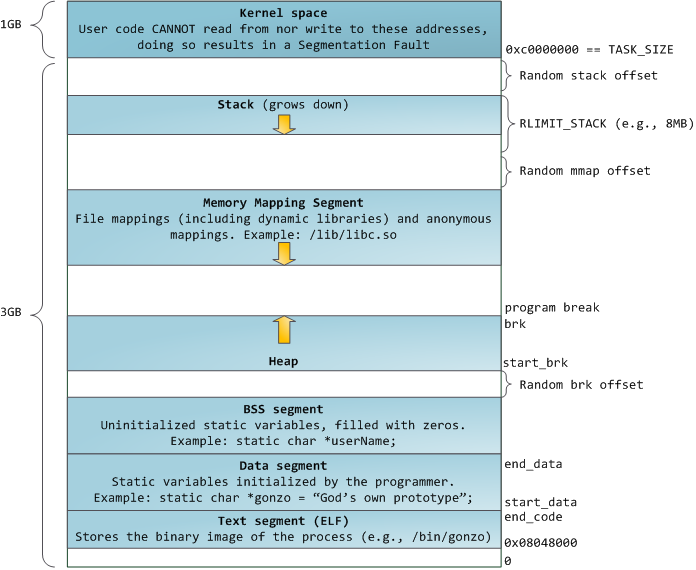
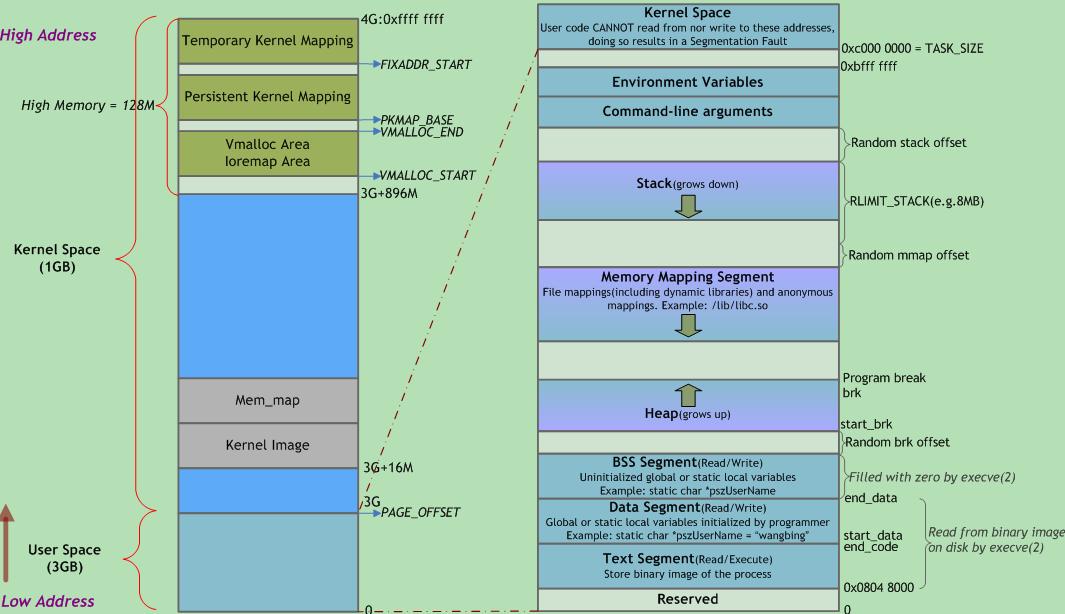
-
虽然传统上Linux上的malloc实现会使用brk()/sbrk()来实现malloc()(这俩构成了上图中“Heap”所示的部分,这也是Linux自身所认为是heap的地方——用pmap看可以看到这里被标记为[heap]),但这并不是必须的——一个malloc()实现完全可以只用或基本上只用mmap()来实现malloc(),此时一般说的“Heap”(malloc-heap)就不一定在上图“Heap”(Linux heap)所示部分,而会在“Memory Mapping Segment”部分散布开来。不同版本的Linux在分配未指定起始地址的mmap()时用的顺序不一样,并不保证某种顺序。而且mmap()分配到的空间是有可能出现在低于主可执行程序映射进来的text Segment所在的位置。
-
Linux上多线程进程中,“线程”其实是一组共享虚拟地址空间的进程。只有主线程的栈是按照上面图示分布,其它线程的栈的位置其实是“随机”的——它们可以由pthread_create()调用mmap()来分配,也可以由程序自己调用mmap()之后把地址传给pthread_create()。既然是mmap()来的,其它线程的栈出现在Memory Mapping Segment的任意位置都不出奇,与用于实现malloc()用的mmap()空间很可能是交错出现的。
-
Windows的进程地址空间。Windows的进程地址空间分布跟上面说的简化的Linux/x86模型颇不一样。就算在没有ASLR的老Windows上也已经很不一样,有了ASLR之后就更加不一样了。在Windows上不应该对栈和堆的相对位置做任何假设。 要想看个清楚Windows的进程地址空间长啥样,可以用Sysinternals出品的VMMap看看。该工具简介请见:VMMap - A Peek Inside Virtual Memory。
refer:
RAII
RAII(Resource Acquisition Is Initialization, pronounced as “R, A, double I”),是C++用于管理资源的方式。
Resource acquisition is initialization (RAII) is a programming idiom used in several object-oriented languages to describe a particular language behavior. In RAII, holding a resource is a class invariant, and is tied to object lifetime: resource allocation (or acquisition) is done during object creation (specifically initialization), by the constructor, while resource deallocation (release) is done during object destruction (specifically finalization), by the destructor. In other words, resource acquisition must succeed for initialization to succeed. Thus the resource is guaranteed to be held between when initialization finishes and finalization starts (holding the resources is a class invariant), and to be held only when the object is alive. Thus if there are no object leaks, there are no resource leaks.
void foo()
{
bar* ptr = new bar();
// some operations and throw an exception
delete ptr;
}
上述示例,在不使用RAII的方法时存在的问题:
- 若delete之前的代码出现异常时,导致delete无法执行从而产生内存泄露。
- 不符合C++的惯用法,通常应该使用栈内存分配(意思是,借助本地变量,确保其析构函数删除该对象)。资源管理不限于内存,也可以是,关闭文件,释放同步锁,释放其他系统资源。
例如:
方法1(不推荐):
#include <iostream> // std::cout
#include <thread> // std::thread
#include <mutex> // std::mutex
std::mutex mtx; // mutex for critical section
void print_block (int n, char c) {
// critical section (exclusive access to std::cout signaled by locking mtx):
mtx.lock();
for (int i = 0; i < n; ++i) { std::cout << c; }
std::cout << '\n';
mtx.unlock();
}
int main ()
{
std::thread th1 (print_block,50,'*');
std::thread th2 (print_block,50,'$');
th1.join();
th2.join();
return 0;
}
/*
$ g++ -o mutex2 mutex2.cpp -lpthread
$ ./mutex2
$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$
**************************************************
*/
方法2(推荐):
#include <iostream>
#include <map>
#include <string>
#include <chrono>
#include <thread>
#include <mutex>
std::map<std::string, std::string> g_pages;
std::mutex g_pages_mutex;
void save_page(const std::string &url)
{
// 模拟长页面读取
std::this_thread::sleep_for(std::chrono::seconds(2));
std::string result = "fake content";
std::lock_guard<std::mutex> guard(g_pages_mutex);
g_pages[url] = result;
}
int main()
{
std::thread t1(save_page, "http://foo");
std::thread t2(save_page, "http://bar");
t1.join();
t2.join();
// 现在访问g_pages是安全的,因为线程t1/t2生命周期已结束
for (const auto &pair : g_pages) {
std::cout << pair.first << " => " << pair.second << '\n';
}
}
/*
$ g++ -o mutex mutex.cpp -lpthread
$ ./mutex
http://bar => fake content
http://foo => fake content
*/
方法3(推荐):
#include <thread>
#include <mutex>
#include <iostream>
int g_i = 0;
std::mutex g_i_mutex; // 保护 g_i
void safe_increment()
{
std::lock_guard<std::mutex> lock(g_i_mutex);
++g_i;
std::cout << std::this_thread::get_id() << ": " << g_i << '\n';
// g_i_mutex 在锁离开作用域时自动释放
}
int main()
{
std::cout << "main: " << g_i << '\n';
std::thread t1(safe_increment);
std::thread t2(safe_increment);
t1.join();
t2.join();
std::cout << "main: " << g_i << '\n';
}
/*
$ g++ -o mutex3 mutex3.cpp -lpthread
$ ./mutex3
main: 0
139691703760640: 1
139691712153344: 2
main: 2
*/
refer:
- Resource acquisition is initialization (RAII)
- lock_guard
- https://zh.cppreference.com/w/cpp/thread/mutex
- http://www.cplusplus.com/reference/mutex/mutex/
移动语义
移动语义是C++11里引入的一个重要概念,理解这个概念是理解很多现代C++里的优化的基础。
值分左右
C++标准里定义了表达式的值类别(注意,区别术语值类型,是与引用类型相对而言,在C++里,所有的原生类型,枚举,结构,联合,类都代表值类型,只有引用&和指针*才是引用类型):
expression分为glvalue和rvalueglvalue分为lvalue和xvalue,rvalue分为xvalue和prvalue
含义:
- 一个
lvalue通常可以放在等号左边的表达式,称为左值 - 一个
rvalue通常只能放在等号右边的表达式,称为右值 - 一个
glvalue是generalized lvalue,称为广义左值 - 一个
xvalue是expiring lvalue,称为将亡值 - 一个
prvalue是pure rvalue,称为纯右值
左值
左值(lvalue)是有标识符,可以取地址的表达式,常见的有:
- 变量,函数,或数据成员的名字
- 返回左值引用的表达式,如,
++x,x = 1,cout << "" - 字符串字面量,如”hello world”
在函数调用时,左值可以绑定到左值引用的参数,如T&,一个常量只能绑定到常左值引用,如const T&
右值
纯右值prvalue是没有标识符,不可以取地址的表达式,一般称之为临时对象,常见有:
- 返回非引用类型的表达式,如,
x++,x + 1,make_shared<int>(42) - 除字符串字面量之外的字面量,如,
42,true
总结
- 在C++11之前,右值可以绑定到常左值引用(const lvalue reference)的参数,如,
const T&,但不可以绑定到非常左值引用(non-const lvalue reference),如,T&。 - 从C++11开始,新增了一种右值引用(T&&),通过不同的引用类型进行重载,从而可以实现不同的行为,比如,性能优化。
smart_ptr<shape> ptr1{new circle()};
smart_ptr<shape> ptr2 = std::move(ptr1);
第一个表达式,new circle()是一个纯右值prvalue,对于指针通常使用值传递,并不关心它是左值还是右值。
第二个表达式,std::move(ptr1)的作用是,把一个左值引用强制转换成一个右值引用,而并不改变其内容。可以把std::move(ptr1)看作是一个有名字的右值,为了和无名的纯右值prvalue相区别,C++里目前把这种表达式称为xvalue。与左值lvalue不同,xvalue仍然是不能取地址的(xvalue与prvalue相同),因此xvalue和prvalue都被归为右值rvalue。
| 表达式值类别 | 不可移动 | 可移动 |
|---|---|---|
| glvalue | lvalue(有标识符) | xvalue(有标识符) |
| rvalue | prvalue(无标识符)xvalue(有标识符) |
More: Value categories
临时对象特殊的生命周期延长规则
GotW #88: A Candidate For the “Most Important const”提出了一个问题:
// Is the following code legal C++?
string f() { return "abc"; }
void g() {
const string& s = f();
cout << s << endl; // can we still use the "temporary" object? Yes
}
如果把const去掉呢?
// What if we take out the const… is Example 2 still legal C++?
string f() { return "abc"; }
void g() {
string& s = f(); // still legal? No
cout << s << endl;
}
另一个例子,当引用生命周期结束时,对象是如何析构的?
Derived factory(); // construct a Derived object
void g() {
const Base& b = factory(); // calls Derived::Derived here
// … use b …
} // calls Derived::~Derived directly here — not Base::~Base + virtual dispatch!
// When the reference goes out of scope, which destructor gets called?
#include <iostream>
using namespace std;
class Base
{
public:
Base() { cout << "Base()\n"; }
~Base() { cout << "~Base()\n"; }
};
class Derived : public Base
{
public:
Derived() { cout << "Derived()\n"; }
~Derived() { cout << "~Derived()\n"; }
};
Derived Factory()
{
return Derived();
}
int main()
{
//Base* obj = new Derived();
//const Base* obj = new Derived();
//delete obj;
// error: cannot bind non-const lvalue reference of type ‘Base&’ to an rvalue of type ‘Base’
//Base& obj = Factory();
const Base& obj = Factory(); // ok
//Base&& obj = Factory(); // ok
cout << "end\n";
}
/*
Base()
Derived()
end
~Derived()
~Base()
*/
即,你可以把一个没有虚析构函数的子类对象绑定到基类的引用变量上,这个子类对象的析构仍然是完全正常的。这是因为这条规则只是延后了临时对象的析构而已,不是利用引用计数等复杂的方法,因而只要引用绑定成功,其类型并没有什么影响。
为了方便对临时对象的使用,C++对临时对象有特殊的生命周期延长规则: 如果一个prvalue被绑定到一个引用上,它的生命周期会延长到和这个引用变量一样长。且注意,这条生命周期延长规则只对prvalue有效,而对xvalue无效。
测试:
#include <cstdio>
class shape {
public:
virtual ~shape() {}
};
class circle : public shape {
public:
circle() { puts("circle()"); }
~circle() { puts("~circle()"); }
};
class triangle : public shape {
public:
triangle() { puts("triangle()"); }
~triangle() { puts("~triangle()"); }
};
class result {
public:
result() { puts("result()"); }
~result() { puts("~result()"); }
};
result process_shape(const shape& shape1,
const shape& shape2)
{
puts("process_shape()");
return result();
}
int main()
{
puts("main()");
process_shape(circle(), triangle());
puts("something else");
}
/*
main()
triangle()
circle()
process_shape()
result()
~result()
~circle()
~triangle()
something else
*/
修改代码,将prvalue绑定到引用(const T& 或者 T&&)后,临时对象的生命周期则会和引用对象的生命周期一致:
int main()
{
puts("main()");
//const result &r = process_shape(circle(), triangle()); // ok
result&& r = process_shape(circle(), triangle()); // ok
puts("something else");
}
/*
main()
triangle()
circle()
process_shape()
result()
~circle()
~triangle()
something else
~result()
*/
如果改为xvalue,则此规则无效。注意,有效变量r指向的对象已经不存在了,对r解引用是一个未定义行为。
#include <utility>
int main()
{
puts("main()");
//const result &r = process_shape(circle(), triangle());
//result&& r = process_shape(circle(), triangle());
result&& r = std::move(process_shape(circle(), triangle())); // xvalue, no
puts("something else");
}
/*
main()
triangle()
circle()
process_shape()
result()
~result()
~circle()
~triangle()
something else
*/
C++ 中 const 引用可以延缓临时变量的生命周期,而 const 指针不能延长临时对象的生命周期
当一个临时对象的地址被赋给一个 const 指针时,临时对象的生命周期并不会被延长。当临时对象的生命周期结束时,const 指针将成为悬空指针。
const std::string *p = &std::string("hello"); // 指针 p 指向一个临时对象
std::cout << *p; // 未定义行为,因为 p 是一个悬空指针
在这个例子中,临时字符串对象 “hello” 在第一行结束时就被销毁了,所以在第二行中,指针 p 已经成为了悬空指针,解引用它将导致未定义行为。
移动的意义
使用右值引用的目的是实现移动,而实现移动的意义是减少运行的开销。
在使用容器类的情况下,移动更有意义。例如:
string result = string("Hello, ") + name + ".";
执行流程大致如下:
- 调用构造函数 string(const char*),生成临时对象1:”Hello, “
- 调用 operator+(const string&, const string&),生成临时对象2:”Hello, “
- 调用 operator+(const string&, const char*),生成临时对象3:”Hello, .”
- 假设返回值优化能够生效(最佳情况),对象 3 可以直接在 result 里构造完成
- 临时对象 2 析构,释放指向 string(“Hello, “) + name 的内存
- 临时对象 1 析构,释放指向 string(“Hello, “) 的内存
因此,建议的写法是:
// 只会调用构造函数一次和 string::operator+= 两次,没有任何临时对象需要生成和析构
string result = "Hello, ";
result += name;
result += ".";
但是,从 C++11 开始,以上+=的写法不再是必须的。同样上面那个单行的语句,执行流程大致如下:
- 调用构造函数 string(const char*),生成临时对象 1:”Hello, “
- 调用 operator+(string&&, const string&),直接在临时对象 1 上面执行追加操作,并把结果移动到临时对象 2
- 调用 operator+(string&&, const char*),直接在临时对象 2 上面执行追加操作,并把结果移动到 result
- 临时对象 2 析构,内容已经为空,不需要释放任何内存
- 临时对象 1 析构,内容已经为空,不需要释放任何内存
性能上,所有的字符串只复制了一次;虽然比啰嗦的写法仍然要增加临时对象的构造和析构,但由于这些操作不牵涉到额外的内存分配和释放,是相当廉价的。程序员只需要牺牲一点点性能,就可以大大增加代码的可读性。
所有的现代 C++ 的标准容器都针对移动进行了优化。
实现移动
让设计的对象支持移动,通常需要:
- 对象有,分开的拷贝构造和移动构造函数(例如,unique_ptr只支持移动,所以只有移动构造,不支持拷贝)
- 对象有,swap成员函数,支持和另一个对象快速交换
- 在对象的命名空间下,应当有一个全局的swap函数,调用成员函数swap来实现交换。(支持这种用法可以方便在其他对象里包含你的对象,并快速实现它们的swap函数)
- 实现通用的 operator=
- 上面各个函数如果不抛异常的话,应当标为
noexcept,这对移动构造函数尤为重要
移动和NRVO(Named Return Value Optimization)
在 C++11 之前,返回一个本地对象意味着这个对象会被拷贝,除非编译器发现可以做返回值优化(named return value optimization,或 NRVO),能把对象直接构造到调用者的栈上。从 C++11 开始,返回值优化仍可以发生,但在没有返回值优化的情况下,编译器将试图把本地对象移动出去,而不是拷贝出去。这一行为不需要程序员手工用 std::move 进行干预——使用 std::move 对于移动行为没有帮助,反而会影响返回值优化。
例子:
#include <iostream> // std::cout/endl
#include <utility> // std::move
using namespace std;
class Obj {
public:
Obj()
{
cout << "Obj()" << endl;
}
Obj(const Obj&)
{
cout << "Obj(const Obj&)" << endl;
}
Obj(Obj&&)
{
cout << "Obj(Obj&&)" << endl;
}
};
Obj simple()
{
Obj obj;
// 简单返回对象;一般有 NRVO
return obj;
}
Obj simple_with_move()
{
Obj obj;
// move会禁止 NRVO
// 需要生成一个 Obj,给了一个 Obj&&,因此会调用构造函数,所以就是多产生了一次Obj(Obj&&) 的调用
return std::move(obj);
}
Obj complicated(int n)
{
Obj obj1;
Obj obj2;
// 有分支,一般无 NRVO
if (n % 2 == 0) {
return obj1;
} else {
return obj2;
}
}
int main()
{
cout << "*** 1 ***" << endl;
auto obj1 = simple();
cout << "*** 2 ***" << endl;
auto obj2 = simple_with_move();
cout << "*** 3 ***" << endl;
auto obj3 = complicated(42);
}
/*
*** 1 ***
Obj()
*** 2 ***
Obj()
Obj(Obj&&)
*** 3 ***
Obj()
Obj()
Obj(Obj&&)
*/
引用坍缩(引用折叠)和完美转发
对于一个实际的类型T,它的左值引用是T&,右值引用是T&&。那么:
- 是不是看到
T&,就一定是个左值引用? – 是 - 是不是看到
T&&,就一定是个右值引用? – 否
关键在于,在有模板的代码里,对于类型参数的推导结果可能是引用。
- 对于 template foo(T&&) 这样的代码,如果传递过去的参数是左值,T 的推导结果是左值引用;如果传递过去的参数是右值,T 的推导结果是参数的类型本身。
- 如果 T 是左值引用,那 T&& 的结果仍然是左值引用,即 type& && 坍缩成了 type&。
- 如果 T 是一个实际类型,那 T&& 的结果自然就是一个右值引用。
事实上,很多标准库里的函数,连目标的参数类型都不知道,但我们仍然需要能够保持参数的值类别:左值的仍然是左值,右值的仍然是右值。这个功能在 C++ 标准库中已经提供了,叫 std::forward。它和 std::move 一样都是利用引用坍缩机制来实现。
因为在 T 是模板参数时,T&& 的作用主要是保持值类别进行转发,它有个名字就叫“转发引用”(forwarding reference)。因为既可以是左值引用,也可以是右值引用,它也曾经被叫做“万能引用”(universal reference)。
template <typename T>
void bar(T&& s)
{
foo(std::forward<T>(s));
}
测试代码:https://gcc.godbolt.org/z/sYfcnoj7M
#include <type_traits>
#include <iostream>
#include <string>
template <typename T>
void test(T&& x)
{
using XType = decltype(x);
std::cout << "XType is "
<< (std::is_reference<XType>::value ? "reference " : "non-reference ")
<< (std::is_lvalue_reference<XType>::value ? "&" : "")
<< (std::is_rvalue_reference<XType>::value ? "&&" : "")
<< std::endl;
}
int main()
{
int i = 0;
const int ci = 0;
// 1. 左值 int
test(i); // T 推断为 int&,T&& 折叠为 int&
// 2. 右值 int
test(10); // T 推断为 int,T&& 折叠为 int&&
// 3. 左值 const int
test(ci); // T 推断为 const int&,T&& 折叠为 const int&
// 4. 右值 const int
test(std::move(ci)); // T 推断为 const int,T&& 折叠为 const int&&
}
/*
XType is reference &
XType is reference &&
XType is reference &
XType is reference &&
*/
智能指针
智能指针本质上就是RAII资源管理功能的自然展现。
class shape_wrapper {
public:
explicit shape_wrapper(shape* ptr = nullptr) : m_ptr(ptr) {}
~shape_wrapper() { delete m_ptr; }
shape* get() const { return m_ptr; }
private:
shape* m_ptr;
};
上面的shape类完成了智能指针的最基本功能,对超出作用域的对象进行释放。但是仍缺少以下功能:
- 只适用于某个类
- 该类对象的行为不够像指针
- 拷贝该类对象会引发程序行为异常
模板化和易用性
要让这个类能够包装任意类型的指针,需要把它变成一个模板类。在使用的时候将shape_wrapper改成smart_ptr<shape>。
template <typename T>
class smart_ptr {
public:
explicit smart_ptr(T* ptr = nullptr) : m_ptr(ptr) {}
~smart_ptr() { delete m_ptr; }
T* get() const { return m_ptr; }
private:
T* m_ptr;
};
然后添加一些成员函数(解引用操作符*, 箭头操作符->, 布尔表达式),从而可以用类似内置的指针方式使用其对象。
template <typename T>
class smart_ptr {
public:
explicit smart_ptr(T* ptr = nullptr) : m_ptr(ptr) {}
~smart_ptr() { delete m_ptr; }
T* get() const { return m_ptr; }
// make it like pointer
T& operator*() const { return *m_ptr; }
T* operator->() const { return m_ptr; }
operator bool() const { return m_ptr; }
private:
T* m_ptr;
};
拷贝构造和赋值
需要关心如何定义其行为。考虑如果允许拷贝,则会存在多次内存释放的问题,因此需要禁止拷贝。
#define DISALLOW_COPY_AND_ASSIGN(Type) \
Type(const Type&) = delete; \
Type& operator=(const Type&) = delete
template <typename T>
class smart_ptr {
public:
explicit smart_ptr(T* ptr = nullptr) : m_ptr(ptr) {}
~smart_ptr() { delete m_ptr; }
// forbidden copy
//smart_ptr(const smart_ptr&) = delete;
//smart_ptr& operator=(const smart_ptr&) = delete;
DISALLOW_COPY_AND_ASSIGN(smart_ptr);
T* get() const { return m_ptr; }
// make it like pointer
T& operator*() const { return *m_ptr; }
T* operator->() const { return m_ptr; }
operator bool() const { return m_ptr; }
private:
T* m_ptr;
};
通过禁止拷贝构造和赋值构造,就可以在编译时发现存在拷贝的错误,例如,smart_ptr<shape> ptr2(ptr1);的写法,而不是在运行时出现两次释放内存的错误导致程序崩溃。
另一种解决思路是,使用智能指针的目的是,减少对象的拷贝。因此,可以将拷贝实现为转移指针的所有权。在拷贝构造函数中,通过release方法释放指针所有权。在赋值构造函数中,通过拷贝构造产生一个临时对象并调用swap来交换对指针的所有权。
注意:
- 用临时对象是为了把要转移的赋值对象控制权去除,同时在转移后把被赋值对象的资源释放掉
- 此处赋值构造函数的用法,是一种惯用法(参考: What is the copy-and-swap idiom?),保证了强异常安全性。赋值分为拷贝构造和交换两步,异常只可能在第一步发生,而第一步如果发生异常的话,this对象完全不受任何影响。无论拷贝构造成功与否,结果都是明确的两种状态,而不会发生因为赋值破坏了当前对象的场景。
template <typename T>
class smart_ptr {
public:
explicit smart_ptr(T* ptr = nullptr) : m_ptr(ptr) {}
~smart_ptr() { delete m_ptr; }
// forbidden copy
//smart_ptr(const smart_ptr&) = delete;
//smart_ptr& operator=(const smart_ptr&) = delete;
// move resource to new object, and release old
smart_ptr(const smart_ptr& other) {
m_ptr = other.release();
}
smart_ptr& operator=(const smart_ptr& rhs) {
// release old and create tmp object, then to swap
smart_ptr(rhs).swap(*this);
return *this;
}
T* release() {
T* ptr = m_ptr;
m_ptr = nullptr;
return ptr;
}
void swap(smart_ptr& rhs) {
using std::swap;
swap(m_ptr, rhs.m_ptr);
}
T* get() const { return m_ptr; }
// make it like pointer
T& operator*() const { return *m_ptr; }
T* operator->() const { return m_ptr; }
operator bool() const { return m_ptr; }
private:
T* m_ptr;
};
以上用法和标准库的auto_ptr类(为动态分配的对象提供异常安全)的行为类似(行为解释如下表所示)。注意,auto_ptr是在C++98提出的,因为此语义容易让程序犯错,在C++17时已经被正式从C++标准里删除。
| 方法 | 含义 |
|---|---|
| auto_ptr |
创建名为ap的未绑定的auto_ptr对象 |
| auto_ptr |
创建名为ap的auto_ptr对象,ap拥有指针p指向的对象,该构造函数为explicit |
| auto_ptr |
创建名为ap1的auto_ptr对象,ap1保存原来存储在ap2中的指针,将所有权转给ap1,使ap2成为未绑定的auto_ptr对象 |
| ap1 = ap2 | 将所有权从ap2转给ap1,删除ap1指向的对象并且使ap1指向ap2指向的对象,使ap2成为未绑定的 |
| ~ap | 析构函数,删除ap指向的对象 |
| *ap | 返回对ap所绑定的对象的引用 |
| ap-> | 返回ap保存的指针 |
| ap.reset(p) | 如果p与ap的值不同,则删除ap指向的对象,并且将ap绑定到p |
| ap.release() | 返回ap所保存的指针,并且使ap成为未绑定的 |
| ap.get() | 返回ap保存的指针 |
注意:
- auto_ptr只能用于管理从new返回的一个对象,不能管理动态分配的数组(否则未定义行为)。由于auto_ptr被复制或赋值的时候有不寻常的行为,因此,不能将auto_ptr存储在标准容器类型中,标准库的容器类要求在复制或赋值之后两个对象相等,auto_ptr不满足这一要求。
- 与其他复制或赋值操作不同,auto_ptr的复制和赋值改变右操作数,因此,赋值的左右操作数必须都是可修改的左值。
引用计数
一个对象只能被单个unique_ptr所拥有;shared_ptr允许多个智能指针同时拥有一个对象,当它们全部都失效时(共享计数),这个对象也同时会被删除。以下实现一个类似标准shared_ptr的智能指针,但是还缺少部分功能。
#include <cstdio>
#include <iostream>
#include <utility> // std::swap
// 共享计数类
class shared_count {
public:
shared_count() noexcept : count_(1) {}
void add_count() noexcept // 增加计数
{
++count_;
}
long reduce_count() noexcept // 减少计数,并返回当前计数以用于调用者判断是否是最后一个共享计数
{
return --count_;
}
long get_count() const noexcept // 获取计数
{
return count_;
}
private:
long count_;
};
// 引用计数智能指针
template <typename T>
class smart_ptr {
public:
//template <typename U>
//friend class smart_ptr;
explicit smart_ptr(T* ptr = nullptr) : ptr_(ptr)
{
if (ptr) {
shared_count_ = new shared_count();
}
}
~smart_ptr()
{
// 当ptr_非空时,此时shared_count_也必然非空
if (ptr_ && !shared_count_->reduce_count()) {
delete ptr_;
delete shared_count_;
}
}
smart_ptr(const smart_ptr& other)
{
std::cout << "smart_ptr(const smart_ptr& other)\n";
ptr_ = other.ptr_;
if (ptr_) {
other.shared_count_->add_count();
shared_count_ = other.shared_count_;
}
}
template <typename U>
smart_ptr(const smart_ptr<U>& other) noexcept
{
std::cout << "smart_ptr(const smart_ptr<U>& other)\n";
ptr_ = other.ptr_;
if (ptr_) {
other.shard_count_->add_count();
shared_count_ = other.shared_count_;
}
}
template <typename U>
smart_ptr(smart_ptr<U>&& other)
{
std::cout << "smart_ptr(smart_ptr<U>&& other)\n";
ptr_ = other.ptr_;
if (ptr_) {
shared_count_ = other.shared_count_;
other.ptr_ = nullptr;
}
}
// 指针类型转换
template <typename U>
smart_ptr(const smart_ptr<U>& other, T* ptr) noexcept {
ptr_ = ptr;
if (ptr_) {
other.shared_count_->add_count();
shared_count_ = other.shared_count_;
}
}
smart_ptr& operator=(smart_ptr rhs) noexcept {
rhs.swap(*this);
return *this;
}
T* get() const noexcept {
return ptr_;
}
long use_count() const
{
if (ptr_) {
return shared_count_->get_count();
} else {
return 0;
}
}
void swap(smart_ptr& rhs) noexcept {
using std::swap;
swap(ptr_, rhs.ptr_);
swap(shared_count_, rhs.shared_count_);
}
T& operator*() const noexcept { return *ptr_; }
T* operator->() const noexcept { return ptr_; }
operator bool() const noexcept { return ptr_; }
private:
T* ptr_;
shared_count* shared_count_;
};
template <typename T>
void swap(smart_ptr<T>& lhs, smart_ptr<T>& rhs) noexcept {
lhs.swap(rhs);
}
template <typename T, typename U>
smart_ptr<T> static_pointer_cast(const smart_ptr<U>& other) noexcept {
T* ptr = static_cast<T*>(other.get());
return smart_ptr<T>(other, ptr);
}
template <typename T, typename U>
smart_ptr<T> reinterpret_pointer_cast(const smart_ptr<U>& other) noexcept {
T* ptr = reinterpret_cast<T*>(other.get());
return smart_ptr<T>(other, ptr);
}
template <typename T, typename U>
smart_ptr<T> const_pointer_cast(const smart_ptr<U>& other) noexcept {
T* ptr = const_cast<T*>(other.get());
return smart_ptr<T>(other, ptr);
}
template <typename T, typename U>
smart_ptr<T> dynamic_pointer_cast(const smart_ptr<U>& other) noexcept {
T* ptr = dynamic_cast<T*>(other.get());
return smart_ptr<T>(other, ptr);
}
int main()
{
int *ptr = new int(1);
std::cout << "ptr: " << *ptr << std::endl;
smart_ptr<int> sptr1(ptr);
std::cout << "sptr1 use conut: " << sptr1.use_count() << std::endl;
smart_ptr<int> sptr2;
std::cout << "sptr2 use conut: " << sptr2.use_count() << std::endl;
sptr2 = sptr1;
std::cout << "sptr2 use conut: " << sptr2.use_count() << std::endl;
smart_ptr<int> sptr3(sptr1);
std::cout << "sptr3 use conut: " << sptr3.use_count() << std::endl;
smart_ptr<int> sptr4(std::move(sptr1));
std::cout << "sptr4 use conut: " << sptr4.use_count() << std::endl;
if (sptr1) {
std::cout << "sptr1 is not empty\n";
} else {
std::cout << "sptr1 is empty\n";
}
}
/*
$ g++ -std=c++11 -o shared_count shared_count.cpp
$./shared_count
ptr: 1
sptr1 use conut: 1
sptr2 use conut: 0
sptr2 use conut: 1
smart_ptr(const smart_ptr& other)
sptr3 use conut: 2
smart_ptr(smart_ptr<U>&& other)
sptr4 use conut: 2
sptr1 is empty
*/
关于shared_ptr的一个使用例子:
#include <iostream>
#include <memory>
#include <thread>
#include <chrono>
#include <mutex>
struct Base
{
Base() { std::cout << " Base::Base()\n"; }
// Note: non-virtual destructor is OK here
~Base() { std::cout << " Base::~Base()\n"; }
};
struct Derived: public Base
{
Derived() { std::cout << " Derived::Derived()\n"; }
~Derived() { std::cout << " Derived::~Derived()\n"; }
};
void thr(std::shared_ptr<Base> p)
{
std::this_thread::sleep_for(std::chrono::seconds(1));
std::shared_ptr<Base> lp = p; // thread-safe, even though the
// shared use_count is incremented
{
static std::mutex io_mutex;
std::lock_guard<std::mutex> lk(io_mutex);
std::cout << "local pointer in a thread:\n"
<< " lp.get() = " << lp.get()
<< ", lp.use_count() = " << lp.use_count() << '\n';
}
}
int main()
{
std::shared_ptr<Base> p = std::make_shared<Derived>();
std::cout << "Created a shared Derived (as a pointer to Base)\n"
<< " p.get() = " << p.get()
<< ", p.use_count() = " << p.use_count() << '\n';
std::thread t1(thr, p), t2(thr, p), t3(thr, p);
p.reset(); // release ownership from main
std::cout << "Shared ownership between 3 threads and released\n"
<< "ownership from main:\n"
<< " p.get() = " << p.get()
<< ", p.use_count() = " << p.use_count() << '\n';
t1.join(); t2.join(); t3.join();
std::cout << "All threads completed, the last one deleted Derived\n";
}
/*
$ g++ -std=c++11 -o shared_ptr_demo shared_ptr_demo.cpp
$ ./shared_ptr_demo
Base::Base()
Derived::Derived()
Created a shared Derived (as a pointer to Base)
p.get() = 0x7f9978c04da8, p.use_count() = 1
Shared ownership between 3 threads and released
ownership from main:
p.get() = 0x0, p.use_count() = 0
local pointer in a thread:
lp.get() = 0x7f9978c04da8, lp.use_count() = 6 // TODO ?
local pointer in a thread:
lp.get() = 0x7f9978c04da8, lp.use_count() = 4
local pointer in a thread:
lp.get() = 0x7f9978c04da8, lp.use_count() = 2
Derived::~Derived()
Base::~Base()
All threads completed, the last one deleted Derived
*/
普通容器
string
string是模板basic_string对于char类型的特化,可以认为是一个只存放字符char类型数据的容器。“真正”的容器类与string的最大不同点是里面可以存放任意类型的对象。
string的内存布局如下图所示:
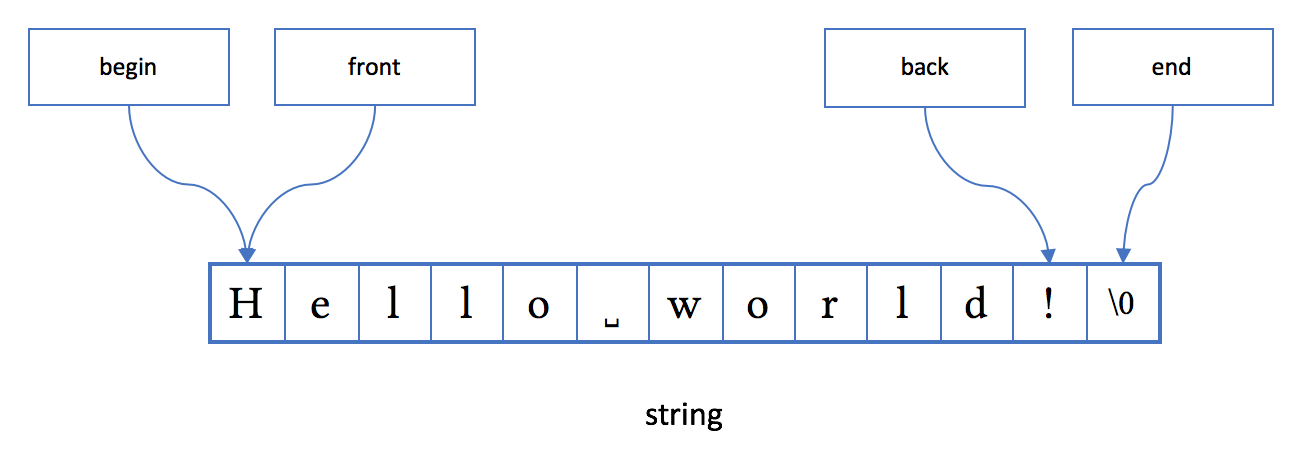
string 当然是为了存放字符串,和简单的 C 字符串不同:
- string 负责自动维护字符串的生命周期
- string 支持字符串的拼接操作(如 + 和 +=)
- string 支持字符串的查找操作(如 find 和 rfind)
- string 支持从 istream 安全地读入字符串(使用 getline)
- string 支持给期待 const char* 的接口传递字符串内容(使用 c_str)
- string 支持到数字的互转(stoi 系列函数和 to_string)
- etc.
使用经验:
- 推荐在代码中尽量使用
string来管理字符串。不过,对于对外暴露的接口,情况有一点复杂。一般不建议在接口中使用const string&,除非确知调用者已经持有string:如果函数里不对字符串做复杂处理的话,使用const char*可以避免在调用者只有 C 字符串时编译器自动构造string,这种额外的构造和析构代价并不低。反过来,如果实现较为复杂、希望使用string的成员函数的话,那就应该考虑下面的策略 - 如果不修改字符串的内容,使用
const string&或 C++17 的string_view作为参数类型。后者是最理想的情况,因为即使在只有 C 字符串的情况,也不会引发不必要的内存复制 - 如果需要在函数内修改字符串内容、但不影响调用者的该字符串,使用 string 作为参数类型(自动拷贝)
- 如果需要改变调用者的字符串内容,使用 string& 作为参数类型(通常不推荐)
string name;
cout << "What's your name? ";
getline(cin, name);
cout << "Nice to meet you, " << name << "!\n";
vector
在实际应用中,把它当成动态数组更为合适。它基本相当于 Java 的 ArrayList 和 Python 的 list。
vector的内存布局如下图所示:
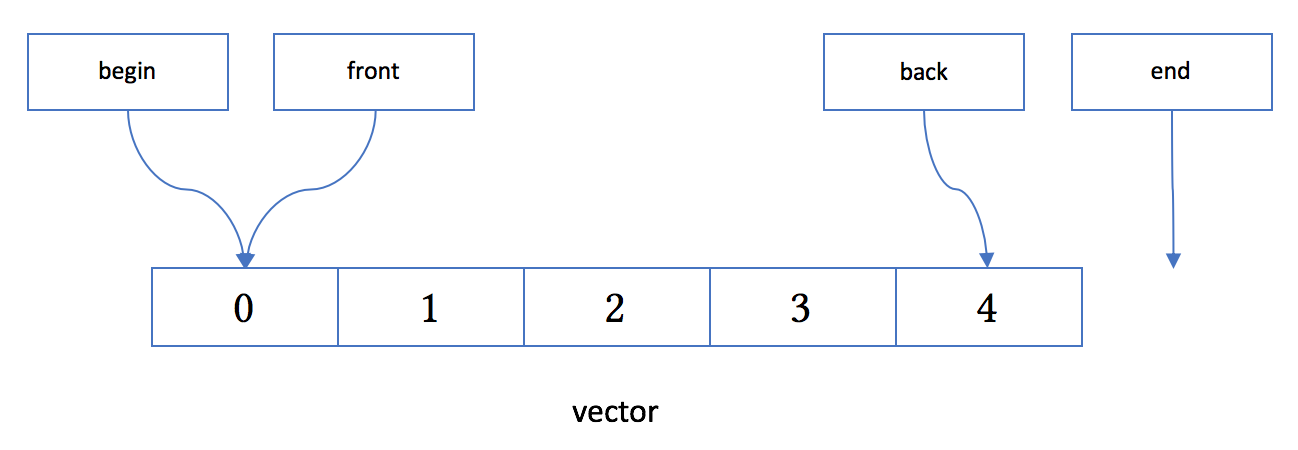
vector 允许下面的操作(不完全列表):
- 可以使用中括号的下标来访问其成员(同 string)
- 可以使用 data 来获得指向其内容的裸指针(同 string)
- 可以使用 capacity 来获得当前分配的存储空间的大小,以元素数量计(同 string)
- 可以使用 reserve 来改变所需的存储空间的大小,成功后 capacity() 会改变(同 string)
- 可以使用 resize 来改变其大小,成功后 size() 会改变(同 string)
- 可以使用 pop_back 来删除最后一个元素(同 string)
- 可以使用 push_back 在尾部插入一个元素(同 string)
- 可以使用 insert 在指定位置前插入一个元素(同 string)
- 可以使用 erase 在指定位置删除一个元素(同 string)
- 可以使用 emplace 在指定位置构造一个元素
- 可以使用 emplace_back 在尾部新构造一个元素
使用经验:
- vector 适合在尾部操作,这是它的内存布局决定的。只有在尾部插入和删除时,其他元素才会不需要移动,除非内存空间不足导致需要重新分配内存空间
- 当 push_back、insert、reserve、resize 等函数导致内存重分配时,或当 insert、erase 导致元素位置移动时,vector 会试图把元素“移动”到新的内存区域。vector 通常保证强异常安全性,如果元素类型没有提供一个保证不抛异常的移动构造函数,vector 通常会使用拷贝构造函数。因此,对于拷贝代价较高的自定义元素类型,我们应当定义移动构造函数,并标其为
noexcept,或只在容器中放置对象的智能指针
注意:
- C++11 开始提供的
emplace…系列函数是为了提升容器的性能而设计的。 你可以试试把 v1.emplace_back() 改成 v1.push_back(Obj1())。对于 vector 里的内容,结果是一样的;但使用 push_back 会额外生成临时对象,多一次(移动或拷贝)构造和析构。如果是移动的情况,那会有小幅性能损失;如果对象没有实现移动的话,那性能差异就可能比较大了。- 现代处理器的体系架构使得对连续内存访问的速度比不连续的内存要快得多。因而,vector 的连续内存使用是它的一大优势所在。当你不知道该用什么容器时,缺省就使用 vector 吧。
- vector 的一个主要缺陷是大小增长时导致的元素移动。如果可能,尽早使用 reserve 函数为 vector 保留所需的内存,这在 vector 预期会增长很大时能带来很大的性能提升。
例子:Obj1 和 Obj2 的定义只差了一个noexcept,但这个小小的差异就导致了 vector 是否会移动对象,这点非常重要。
#include <iostream>
#include <vector>
using namespace std;
class Obj1 {
public:
Obj1() {
cout << "Obj1()\n";
}
Obj1(const Obj1&) {
cout << "Obj1(const Obj1&)\n";
}
Obj1(Obj1&&) {
cout << "Obj1(Obj1&&)\n";
}
};
class Obj2 {
public:
Obj2() {
cout << "Obj2()\n";
}
Obj2(const Obj2&) {
cout << "Obj2(const Obj2&)\n";
}
Obj2(Obj2&&) noexcept {
cout << "Obj2(Obj2&&)\n";
}
};
int main()
{
vector<Obj1> v1;
v1.reserve(1); // 没有内存分配
v1.emplace_back(); // 构造第一个对象
v1.emplace_back(); // 构造第二个对象,并拷贝第一个对象(移动构造函数没有声明 noexcept)
vector<Obj2> v2;
v2.reserve(2);
v2.emplace_back(); // 构造第一个对象
v2.emplace_back(); // 构造第二个对象
v2.emplace_back(); // 构造第三个对象,并移动第一个和第二个对象(由于移动构造函数声明了 noexcept)
}
/*
Obj1()
Obj1()
Obj1(const Obj1&)
Obj2()
Obj2()
Obj2()
Obj2(Obj2&&)
Obj2(Obj2&&)
*/
deque
deque的意思是double-ended queue,双端队列。它主要是用来满足下面这个需求:
- 容器不仅可以从尾部自由地添加和删除元素,也可以从头部自由地添加和删除。
- deque 提供 push_front、emplace_front 和 pop_front 成员函数。
- deque 不提供 data、capacity 和 reserve 成员函数。
deque 的内存布局如下图所示:
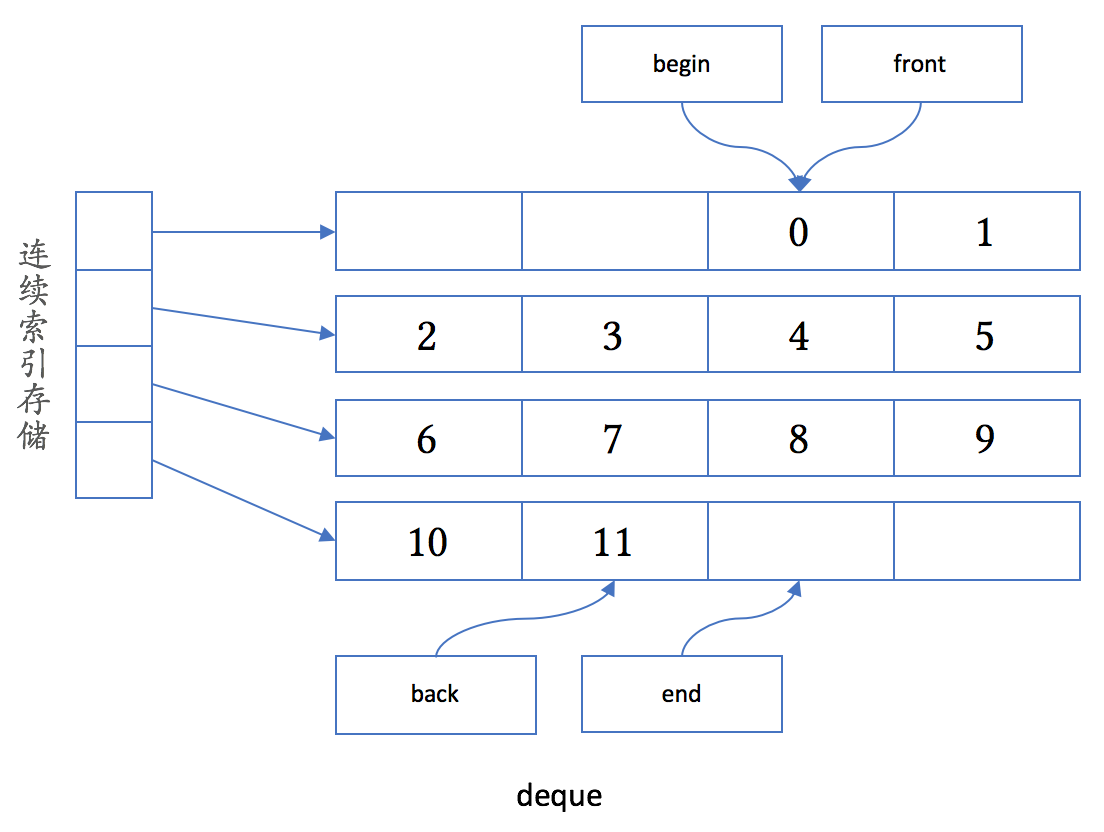
- 如果只从头、尾两个位置对 deque 进行增删操作的话,容器里的对象永远不需要移动
- 容器里的元素只是部分连续的(因而没法提供 data 成员函数)
- 由于元素的存储大部分仍然连续,它的遍历性能是比较高的
- 由于每一段存储大小相等,deque 支持使用下标访问容器元素,大致相当于
index[i / chunk_size][i % chunk_size],也保持高效 - 如果你需要一个经常在头尾增删元素的容器,那 deque 会是个合适的选择
list
list 在 C++ 里代表双向链表。和 vector 相比,它优化了在容器中间的插入和删除:
- list 提供高效的 O(1) 复杂度的任意位置的插入和删除操作。
- list 不提供使用下标访问其元素。
- list 提供 push_front、emplace_front 和 pop_front 成员函数(和 deque 相同)。
- list 不提供 data、capacity 和 reserve 成员函数(和 deque 相同)。
list 的内存布局如下图所示:
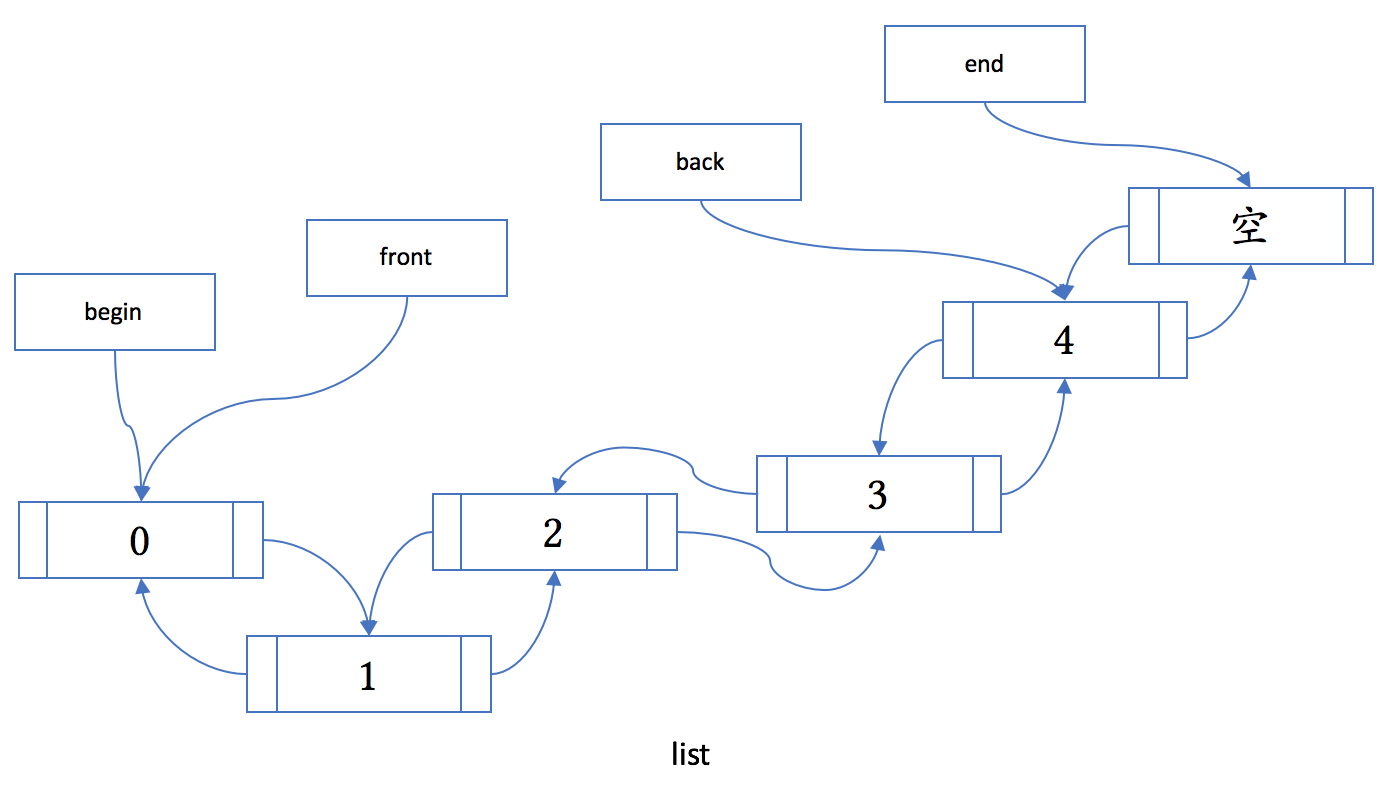
使用经验:
- 虽然 list 提供了任意位置插入新元素的灵活性,但由于每个元素的内存空间都是单独分配、不连续,它的遍历性能比 vector 和 deque 都要低。这在很大程度上抵消了它在插入和删除操作时不需要移动元素的理论性能优势。如果你不太需要遍历容器、又需要在中间频繁插入或删除元素,可以考虑使用 list。
- 因为某些标准算法在 list 上会导致问题,list 提供了成员函数作为替代,比如:merge,remove,remove_if,reverse,sort,unique。
list lst{1, 7, 2, 8, 3};
vector vec{1, 7, 2, 8, 3};
sort(vec.begin(), vec.end()); // 正常
// sort(lst.begin(), lst.end()); // 会出错
lst.sort(); // 正常
forward_list
既然 list 是双向链表,那么 C++ 里有没有单向链表呢?答案是肯定的。从 C++11 开始,前向列表 forward_list 成了标准的一部分。
forward_list 的内存布局如下图所示:
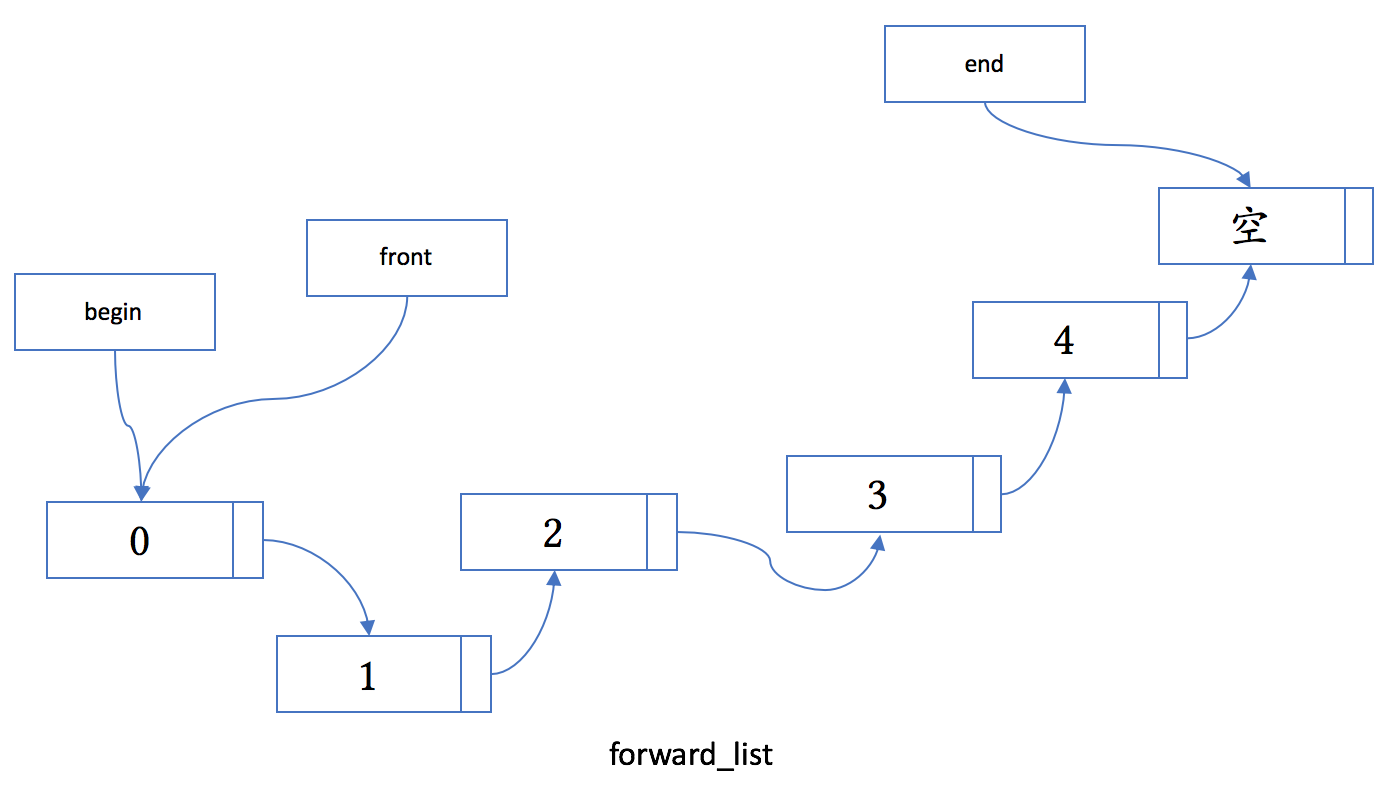
为什么会需要这么一个阉割版的 list 呢?原因是,在元素大小较小的情况下,forward_list 能节约的内存是非常可观的;在列表不长的情况下,不能反向查找也不是个大问题。提高内存利用率,往往就能提高程序性能,更不用说在内存可能不足时的情况了。
queue(类容器)
queue的特别点在于它不是完整的实现,而是依赖于某个现有的容器,因而被称为容器适配器(container adaptor)。
queue 缺省用 deque 来实现。它的接口跟 deque 比,有如下改变:
- 不能按下标访问元素
- 没有 begin、end 成员函数
- 用 emplace 替代了 emplace_back,用 push 替代了 push_back,用 pop 替代了 pop_front;没有其他的 push_…、pop_…、emplace…、insert、erase 函数
它的实际内存布局当然是随底层的容器而定的。从概念上讲,它的结构可如下所示:
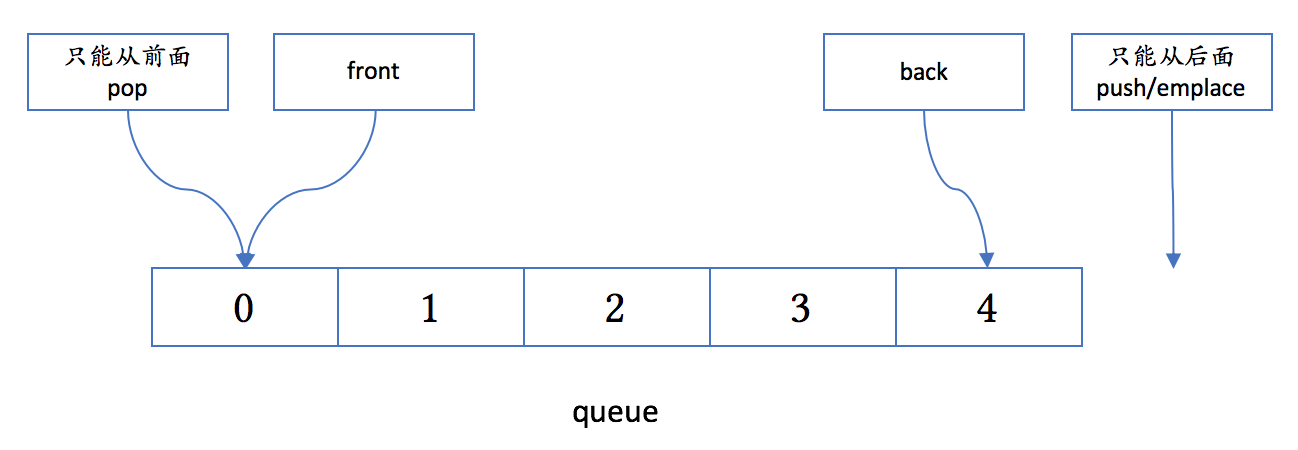
鉴于 queue 不提供 begin 和 end 方法,无法无损遍历:
#include <iostream>
#include <queue>
int main()
{
std::queue<int> q;
q.push(1);
q.push(2);
q.push(3);
while (!q.empty()) {
std::cout << q.front()
<< std::endl;
q.pop();
}
}
stack(类容器)
类似地,栈 stack 是后进先出(LIFO)的数据结构。
stack 缺省也是用 deque 来实现,但它的概念和 vector 更相似。它的接口跟 vector 比,有如下改变:
- 不能按下标访问元素
- 没有 begin、end 成员函数
- back 成了 top,没有 front
- 用 emplace 替代了 emplace_back,用 push 替代了 push_back,用 pop 替代了 pop_back;没有其他的 push_…、pop_…、emplace…、insert、erase 函数
一般图形表示法会把 stack 表示成一个竖起的 vector:
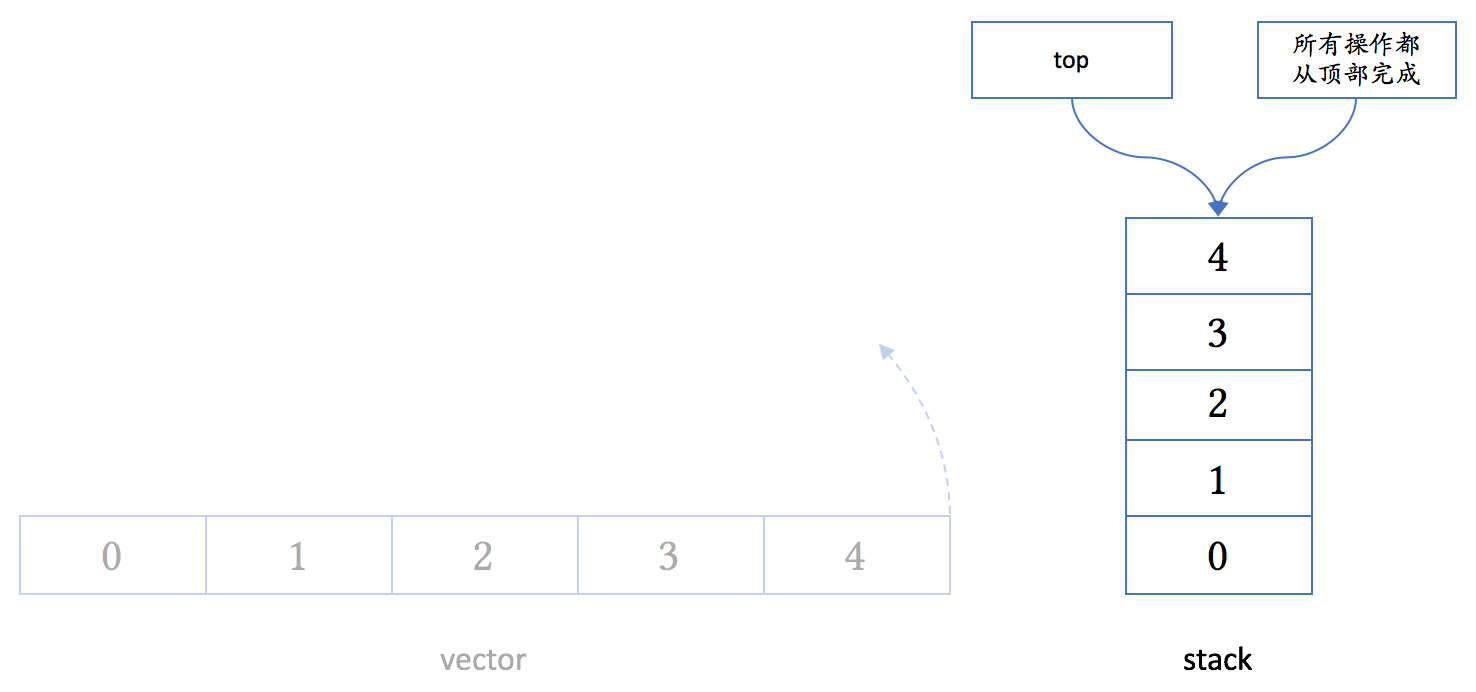
#include <iostream>
#include <stack>
int main()
{
std::stack<int> s;
s.push(1);
s.push(2);
s.push(3);
while (!s.empty()) {
std::cout << s.top()
<< std::endl;
s.pop();
}
}
需要函数对象的容器
函数对象及其特化
首先来讨论一下两个重要的函数对象,less 和 hash。在标准库里,通用的 less 大致是这样定义的:
template <class T>
struct less
: binary_function<T, T, bool> {
bool operator()(const T& x,
const T& y) const
{
return x < y;
}
};
- less 是一个函数对象,并且是个二元函数,执行对任意类型的值的比较,返回布尔类型。作为函数对象,它定义了函数调用运算符(operator()),并且缺省行为是对指定类型的对象进行 < 的比较操作。
- 在需要大小比较的场合,C++ 通常默认会使用 less(如果需要产生相反的顺序的话,则可以使用 greater)。
计算哈希值的函数对象 hash,它的目的是把一个某种类型的值转换成一个无符号整数哈希值,类型为 size_t。它没有一个可用的默认实现。对于常用的类型,系统提供了需要的特化。
例如,int类型的特化:
template <class T> struct hash;
template <>
struct hash<int>
: public unary_function<int, size_t> {
size_t operator()(int v) const
noexcept
{
return static_cast<size_t>(v);
}
};
更复杂的类型,如指针或者 string 的特化。要点是,对于每个类,类的作者都可以提供 hash 的特化,使得对于不同的对象值,函数调用运算符都能得到尽可能均匀分布的不同数值。
#include <algorithm> // std::sort
#include <functional> // std::less/greater/hash
#include <iostream> // std::cout/endl
#include <string> // std::string
#include <vector> // std::vector
#include "output_container.h"
using namespace std;
int main()
{
// 初始数组
vector<int> v{13, 6, 4, 11, 29};
cout << v << endl;
// 从小到大排序
sort(v.begin(), v.end());
cout << v << endl;
// 从大到小排序
sort(v.begin(), v.end(),
greater<int>());
cout << v << endl;
cout << hex;
auto hp = hash<int*>();
cout << "hash(nullptr) = "
<< hp(nullptr) << endl;
cout << "hash(v.data()) = "
<< hp(v.data()) << endl;
cout << "v.data() = "
<< static_cast<void*>(v.data())
<< endl;
auto hs = hash<string>();
cout << "hash(\"hello\") = "
<< hs(string("hello")) << endl;
cout << "hash(\"hellp\") = "
<< hs(string("hellp")) << endl;
}
/*
{ 13, 6, 4, 11, 29 }
{ 4, 6, 11, 13, 29 }
{ 29, 13, 11, 6, 4 }
hash(nullptr) = 0
hash(v.data()) = 55fcc1441e70
v.data() = 0x55fcc1441e70
hash("hello") = 26553298fdbe39c8
hash("hellp") = 62ca8a73f37cbb7b
*/
以上结果为在gcc下编译,若改为MSVC下编译则为:
hash(nullptr) = a8c7f832281a39c5
hash(v.data()) = 7a0bdfd7df0923d2
v.data() = 000001EFFB10EAE0
hash("hello") = a430d84680aabd0b
hash("hellp") = a430e54680aad322
可以看到,在MSVC的实现里,空指针的哈希值是一个非零的数值,指针的哈希值也和指针的数值不一样。要注意不同的实现处理的方式会不一样。事实上,测试结果是 GCC、Clang 和 MSVC 对常见类型的哈希方式都各有不同。
priority_queue
priority_queue 也是一个容器适配器。但是,它用到了比较函数对象(默认是 less)。
- 它和 stack 相似,支持 push、pop、top 等有限的操作,但容器内的顺序既不是后进先出,也不是先进先出,而是(部分)排序的结果。
- 在使用缺省的 less 作为其 Compare 模板参数时,最大的数值会出现在容器的“顶部”。如果需要最小的数值出现在容器顶部,则可以传递 greater 作为其 Compare 模板参数。
#include <functional> // std::greater
#include <iostream> // std::cout/endl
#include <memory> // std::pair
#include <queue> // std::priority_queue
#include <vector> // std::vector
#include "output_container.h"
using namespace std;
int main()
{
priority_queue<
pair<int, int>,
vector<pair<int, int>>,
greater<pair<int, int>>>
q;
q.push({1, 1});
q.push({2, 2});
q.push({0, 3});
q.push({9, 4});
while (!q.empty()) {
cout << q.top() << endl;
q.pop();
}
}
/*
(0, 3)
(1, 1)
(2, 2)
(9, 4)
*/
关联容器
关联容器有 set(集合)、map(映射)、multiset(多重集)和 multimap(多重映射)。跳出 C++ 的语境,map(映射)的更常见的名字是关联数组和字典,而在 JSON 里直接被称为对象(object)。在 C++ 外这些容器常常是无序的,而在 C++ 里关联容器则被认为是有序的。
- 关联容器是一种有序的容器。
- 名字带“multi”的允许键重复,不带的不允许键重复。
set和multiset只能用来存放键,而map和multimap则存放一个个键值对。 - 与序列容器相比,关联容器没有前、后的概念及相关的成员函数,但同样提供 insert、emplace 等成员函数。此外,关联容器都有 find、lower_bound、upper_bound 等查找函数,结果是一个迭代器。
-
find(k) 可以找到任何一个等价于查找键 k 的元素(!(x < k k < x)) - lower_bound(k) 找到第一个不小于( =< )查找键 k 的元素(!(x < k))
- upper_bound(k) 找到第一个大于( > )查找键 k 的元素(k < x)
-
- 如果需要在
multimap里精确查找满足某个键的区间的话,建议使用equal_range,可以一次性取得上下界(半开半闭)。 - 如果在声明关联容器时没有提供比较类型的参数,缺省使用 less 来进行排序。如果键的类型提供了比较算符 < 的重载,我们不需要做任何额外的工作。否则,我们就需要对键类型进行 less 的特化,或者提供一个其他的函数对象类型。
- 对于自定义类型,推荐尽量使用标准的 less 实现,通过重载 <(及其他标准比较运算符)对该类型的对象进行排序。存储在关联容器中的键一般应满足严格弱序关系(strict weak ordering)。
无序关联容器
通过比较来进行查找、插入和删除,复杂度为对数 O(log(n)),有没有达到更好的性能的方法?
从 C++11 开始,每一个关联容器都有一个对应的无序关联容器,它们是:
unordered_set,unordered_map,unordered_multiset,unordered_multimap
这些容器和关联容器非常相似,主要的区别就在于它们是“无序”的。这些容器不要求提供一个排序的函数对象,而要求一个可以计算哈希值的函数对象。你当然可以在声明容器对象时手动提供这样一个函数对象类型,但更常见的情况是,我们使用标准的 hash 函数对象及其特化。
#include <complex> // std::complex
#include <iostream> // std::cout/endl
#include <unordered_map> // std::unordered_map
#include <unordered_set> // std::unordered_set
#include "output_container.h"
using namespace std;
namespace std {
template <typename T>
struct hash<complex<T>> {
size_t
operator()(const complex<T>& v) const
noexcept
{
hash<T> h;
return h(v.real()) + h(v.imag());
}
};
} // namespace std
int main()
{
unordered_set<int> s{
1, 1, 2, 3, 5, 8, 13, 21
};
cout << s << endl;
unordered_map< complex<double>, double > umc{ { {1.0, 1.0}, 1.4142}, { {3.0, 4.0}, 5.0} };
cout << umc << endl;
}
输出可能是(顺序不能保证):
{ 21, 5, 8, 3, 13, 2, 1 }
{ (3,4) => 5, (1,1) => 1.4142 }
- 请注意我们在 std 名空间中添加了特化,这是少数用户可以向 std 名空间添加内容的情况之一。正常情况下,向 std 名空间添加声明或定义是禁止的,属于未定义行为。
- 从实际的工程角度,无序关联容器的主要优点在于其性能。关联容器和 priority_queue 的插入和删除操作,以及关联容器的查找操作,其复杂度都是
O(log(n)),而无序关联容器的实现使用哈希表,可以达到平均O(1)!但这取决于我们是否使用了一个好的哈希函数:在哈希函数选择不当的情况下,无序关联容器的插入、删除、查找性能可能成为最差情况的 O(n),那就比关联容器糟糕得多了。
array
array容器是C 数组的替代品。C 数组在 C++ 里继续存在,主要是为了保留和 C 的向后兼容性。C 数组本身和 C++ 的容器相差是非常大的:
- C 数组没有 begin 和 end 成员函数(虽然可以使用全局的 begin 和 end 函数)
- C 数组没有 size 成员函数(得用一些模板技巧来获取其长度)
- C 数组作为参数有退化行为,传递给另外一个函数后那个函数不再能获得 C 数组的长度和结束位置
获得数组的长度:
#define ARRAY_LEN(a) \
(sizeof(a) / sizeof((a)[0]))
C++17 直接提供了一个 size 方法,可以用于提供数组长度,并且在数组退化成指针的情况下会直接失败:
#include <iostream> // std::cout/endl
#include <iterator> // std::size
void test(int arr[])
{
// 不能编译
// std::cout << std::size(arr)
// << std::endl;
}
int main()
{
int arr[] = {1, 2, 3, 4, 5};
std::cout << "The array length is "
<< std::size(arr)
<< std::endl;
test(arr);
}
如果不用 C 数组的话,该用什么来替代?
- 如果数组较大的话,应该考虑 vector。vector 有最大的灵活性和不错的性能。
- 对于字符串数组,当然应该考虑 string。
- 如果数组大小固定(C 的数组在 C++ 里本来就是大小固定的)并且较小的话,应该考虑 array。array 保留了 C 数组在栈上分配的特点,同时,提供了 begin、end、size 等通用成员函数。
#include <array> // std::array
#include <iostream> // std::cout/endl
#include <map> // std::map
#include "output_container.h"
typedef std::array<char, 8> mykey_t;
int main()
{
std::map<mykey_t, int> mp;
mykey_t mykey{"hello"};
mp[mykey] = 5; // OK
std::cout << mp << std::endl;
}
异常
异常,用还是不用,这是个问题。
首先,开宗明义,如果你不知道到底该不该用异常的话,那答案就是该用。如果你需要避免使用异常,原因必须是你有明确的需要避免使用异常的理由。
没有异常的世界(C)
我们可能有大量需要判断错误的代码,零散分布在代码各处。
matrix c;
// 不清零的话,错误处理和资源清理会更复杂
memset(c, 0, sizeof(matrix));
errcode = matrix_multiply(c, a, b);
if (errcode != MATRIX_SUCCESS) {
goto error_exit;
}
// 使用乘法的结果做其他处理
error_exit:
matrix_dealloc(&c);
return errcode;
上面还只展示了单层的函数调用。事实上,如果出错位置离处理错误的位置相差很远的话,每一层的函数调用里都得有判断错误码的代码,这就既对写代码的人提出了严格要求,也对读代码的人造成了视觉上的干扰。
上面是 C 代码无法用异常,如果是 C++ 用异常可以改善吗?(当然可以,但你会发现结果好不了多少)
使用异常(C++)
- 异常处理并不意味着需要写显式的 try 和 catch。异常安全的代码,可以没有任何 try 和 catch。
- 异常安全,是指当异常发生时,既不会发生资源泄漏,系统也不会处于一个不一致的状态。
- 只要我们适当地组织好代码、利用好 RAII,实现的代码都可以更短、更清晰。我们可以统一在外层某个地方处理异常——通常会记日志、或在界面上向用户报告错误了。
避免异常的风格指南?
但大名鼎鼎的 Google 的 C++ 风格指南不是说要避免异常吗?这又是怎么回事呢?
Given that Google’s existing code is not exception-tolerant, the costs of using exceptions are somewhat greater than the costs in a new project. The conversion process would be slow and error-prone. We don’t believe that the available alternatives to exceptions, such as error codes and assertions, introduce a significant burden.Our advice against using exceptions is not predicated on philosophical or moral grounds, but practical ones. Because we’d like to use our open-source projects at Google and it’s difficult to do so if those projects use exceptions, we need to advise against exceptions in Google open-source projects as well. Things would probably be different if we had to do it all over again from scratch. 鉴于 Google 的现有代码不能承受异常,使用异常的代价要比在全新的项目中使用异常大一些。转换[代码来使用异常的]过程会缓慢而容易出错。我们不认为可代替异常的方法,如错误码或断言,会带来明显的负担。我们反对异常的建议并非出于哲学或道德的立场,而是出于实际考虑。因为我们希望在 Google 使用我们的开源项目,而如果这些项目使用异常的话就会对我们的使用带来困难,我们也需要反对在 Google 的开源项目中使用异常。如果我们从头再来一次的话,事情可能就会不一样了。
这个如果还比较官方、委婉的话,Reddit 上还能找到一个更个人化的表述:
I use [sic] to work at Google, and Craig Silverstein, who wrote the first draft of the style guideline, said that he regretted the ban on exceptions, but he had no choice; when he wrote it, it wasn’t only that the compiler they had at the time did a very bad job on exceptions, but that they already had a huge volume of non-exception-safe code. 我过去在 Google 工作,写了风格指南初稿的 Craig Silverstein 说过他对禁用异常感到遗憾,但他当时别无选择。在他写风格指南的时候,不仅他们使用的编译器在异常上工作得很糟糕,而且他们已经有了一大堆异常不安全的代码了。
当然,除了历史原因以外,也有出于性能等其他原因禁用异常的。美国国防部的联合攻击战斗机(JSF)项目的 C++ 编码规范就禁用异常,因为工具链不能保证抛出异常时的实时性能。不过在那种项目里,被禁用的 C++ 特性就多了,比如动态内存分配都不能使用。
一些游戏项目为了追求高性能,也禁用异常。这个实际上也有一定的历史原因,因为今天的主流 C++ 编译器,在异常关闭和开启时应该已经能够产生性能差不多的代码(在异常未抛出时)。代价是产生的二进制文件大小的增加,因为异常产生的位置决定了需要如何做栈展开,这些数据需要存储在表里。典型情况,使用异常和不使用异常比,二进制文件大小会有约百分之十到二十的上升。LLVM 项目的编码规范里就明确指出这是不使用 RTTI 和异常的原因。
In an effort to reduce code and executable size, LLVM does not use RTTI (e.g. dynamic_cast<>;) or exceptions.
你得想想是否值得这么去做。你的项目对二进制文件的大小和性能有这么渴求吗?需要这么去拼吗?
异常的问题
异常当然不是一个完美的特性,否则也不会招来这些批评和禁用了。对它的批评主要有两条:
- 异常违反了“你不用就不需要付出代价”的 C++ 原则。只要开启了异常,即使不使用异常你编译出的二进制代码通常也会膨胀。
- 异常比较隐蔽,不容易看出来哪些地方会发生异常和发生什么异常。
解释:
GCC/Clang 下的 -fexceptions(缺省开启)。用 GCC,加上 -fno-exceptions 命令行参数,对于下面这样的小程序,也能看到产生的可执行文件的大小的变化。
#include <vector>
int main()
{
std::vector<int> v{1, 2, 3, 4, 5};
v.push_back(20);
}
- 对于第一条,开发者没有什么可做的。事实上,这也算是 C++ 实现的一个折中了。目前的主流异常实现中,都倾向于牺牲可执行文件大小、提高主流程(happy path)的性能。只要程序不抛异常,C++ 代码的性能比起完全不做错误检查的代码,都只有几个百分点的性能损失。除了非常有限的一些场景,可执行文件大小通常不会是个问题。
- 第二条可以算作是一个真正有效的批评。和 Java 不同,C++ 里不会对异常规约进行编译时的检查。从 C++17 开始,C++ 甚至完全禁止了以往的动态异常规约,你不再能在函数声明里写你可能会抛出某某异常。你唯一能声明的,就是某函数不会抛出异常——noexcept、noexcept(true) 或 throw()。这也是 C++ 的运行时唯一会检查的东西了。如果一个函数声明了不会抛出异常、结果却抛出了异常,C++ 运行时会调用 std::terminate 来终止应用程序。不管是程序员的声明,还是编译器的检查,都不会告诉你哪些函数会抛出哪些异常。当然,不声明异常是有理由的。特别是在泛型编程的代码里,几乎不可能预知会发生些什么异常。
对避免异常带来的问题有几点建议:
- 写异常安全的代码,尤其在模板里。可能的话,提供强异常安全保证,在任何第三方代码发生异常的情况下,不改变对象的内容,也不产生任何资源泄漏。
- 如果你的代码可能抛出异常的话,在文档里明确声明可能发生的异常类型和发生条件。确保使用你的代码的人,能在不检查你的实现的情况,了解需要准备处理哪些异常。
- 对于肯定不会抛出异常的代码,将其标为 noexcept。注意类的特殊成员(构造函数、析构函数、赋值函数等)会自动成为 noexcept,如果它们调用的代码都是 noexcept 的话。所以,像 swap 这样的成员函数应当尽可能标成 noexcept。
使用异常的理由
异常是渗透在 C++ 中的标准错误处理方式。标准库的错误处理方式就是异常。其中不仅包括运行时错误,甚至包括一些逻辑错误。比如,在说容器的时候,在能使用 [] 运算符的地方,C++ 的标准容器也提供了 at 成员函数,能够在下标不存在的时候抛出异常,作为一种额外的帮助调试的手段。
vector<int> v{1, 2, 3};
int a = v[0];
int b = v.at(0)
int c = v[3]; // no exception, 越界的数值
// at函数会抛异常
try {
c = v.at(3);
}
catch (const out_of_range& e) {
cerr << e.what() << endl;
}
- C++ 的标准容器在大部分情况下提供了强异常保证,即,一旦异常发生,现场会恢复到调用函数之前的状态,容器的内容不会发生改变,也没有任何资源泄漏。前面提到过,vector 会在元素类型没有提供保证不抛异常的移动构造函数的情况下,在移动元素时会使用拷贝构造函数。这是因为一旦某个操作发生了异常,被移动的元素已经被破坏,处于只能析构的状态,异常安全性就不能得到保证了。
- 只要你使用了标准容器,不管你自己用不用异常,你都得处理标准容器可能引发的异常。至少有 bad_alloc,除非你明确知道你的目标运行环境不会产生这个异常。
- 虽然对于运行时错误,开发者并没有什么选择余地;但对于代码中的逻辑错误,开发者则是可以选择不同的处理方式的:你可以使用异常,也可以使用 assert,在调试环境中报告错误并中断程序运行。由于测试通常不能覆盖所有的代码和分支,assert 在发布模式下一般被禁用,两者并不是完全的替代关系。在允许异常的情况下,使用异常可以获得在调试和发布模式下都良好、一致的效果。
- 标准 C++ 可能会产生哪些异常,可以查看参考资料。
迭代器
迭代器是一个很通用的概念,并不是一个特定的类型。它实际上是一组对类型的要求。
迭代器通常是对象。但需要注意的是,指针可以满足上面所有的迭代器要求,因而也是迭代器。这应该并不让人惊讶,因为本来迭代器就是根据指针的特性,对其进行抽象的结果。事实上,vector 的迭代器,在很多实现里就直接是使用指针的。
迭代器的基本要求是:
- 对象可以被
拷贝构造、拷贝赋值和析构。 - 对象支持
*运算符。 - 对象支持前置
++运算符。
常用迭代器
最常用的迭代器就是容器的 iterator 类型了。以顺序容器为例,它们都定义了嵌套的 iterator 类型和 const_iterator 类型。一般而言,iterator 可写入,const_iterator 类型不可写入,但这些迭代器都被定义为输入迭代器或其派生类型:
- vector::iterator 和 array::iterator 可以满足到连续迭代器
- deque::iterator 可以满足到随机访问迭代器(记得它的内存只有部分连续)
- list::iterator 可以满足到双向迭代器(链表不能快速跳转)
- forward_list::iterator 可以满足到前向迭代器(单向链表不能反向遍历)
如果一个类型像输入迭代器,但 *i 只能作为左值来写而不能读,那它就是个输出迭代器(output iterator)。
#include <algorithm> // std::copy
#include <iterator> // std::back_inserter
#include <vector> // std::vector
#include <iostream> // std::cout
using namespace std;
vector<int> v1{1, 2, 3, 4, 5};
vector<int> v2;
copy(v1.begin(), v1.end(), back_inserter(v2));
// output v2 is { 1, 2, 3, 4, 5 }
copy(v2.begin(), v2.end(), ostream_iterator<int>(cout, " "));
- 输出迭代器是
back_inserter返回的类型back_inserter_iterator,用它可以很方便地在容器的尾部进行插入操作。 - 输出迭代器
ostream_iterator,方便把容器内容“拷贝”到一个输出流。
总结:
cout << *it // 输入迭代器,就是读
*it = 42 // 输出迭代器,就是写
使用输入行迭代器(例子)
通过自定义的输入迭代器。它的功能本身很简单,就是把一个输入流(istream)的内容一行行读进来。配上 C++11 引入的基于范围的 for 循环的语法,我们可以把遍历输入流的代码以一种自然、非过程式的方式写出来。
for (const string& line : istream_line_reader(is)) {
// 示例循环体中仅进行简单输出
cout << line << endl;
}
对比一下以传统的方式写的 C++ 代码,其中需要照顾不少细节:(从 is 读入输入行的逻辑,在前面的代码里一个语句就全部搞定了,在这儿用了 5 个语句)
string line;
for (;;) {
getline(is, line);
if (!is) {
break;
}
cout << line << endl;
}
基于范围的 for 循环这个语法。虽然这可以说是个语法糖,但它对提高代码的可读性真的非常重要。如果不用这个语法糖的话,简洁性上的优势就小多了。我们直接把这个循环改写成等价的普通 for 循环的样子。
{
// auto&& 是用一个“万能”引用捕获一个对象,左值和右值都可以。C++ 的生命期延长规则,保证了引用有效期间,istream_line_reader 这个“临时”对象一直存在。没有生命期延长的话,临时对象在当前语句执行结束后即销毁
auto&& r = istream_line_reader(is);
auto it = r.begin();
auto end = r.end();
for (; it != end; ++it) {
const string& line = *it;
cout << line << endl;
}
}
定义输入行迭代器(例子)
如何实现这个输入行迭代器?
C++ 里有些固定的类型要求规范。对于一个迭代器,我们需要定义下面的类型:
class istream_line_reader {
public:
class iterator { // 实现 InputIterator
public:
typedef ptrdiff_t difference_type;
typedef string value_type;
typedef const value_type* pointer;
typedef const value_type& reference;
typedef input_iterator_tag iterator_category;
…
};
…
};
仿照一般的容器,我们把迭代器定义为 istream_line_reader 的嵌套类。它里面的这五个类型是必须定义的(其他泛型 C++ 代码可能会用到这五个类型。之前标准库定义了一个可以继承的类模板 std::iterator 来产生这些类型定义,但这个类目前已经被废弃)。其中:
difference_type是代表迭代器之间距离的类型,定义为ptrdiff_t只是种标准做法(指针间差值的类型),对这个类型没什么特别作用。value_type是迭代器指向的对象的值类型,我们使用string,表示迭代器指向的是字符串。pointer是迭代器指向的对象的指针类型,这儿就平淡无奇地定义为value_type的常指针了(我们可不希望别人来更改指针指向的内容)。- 类似的,reference 是 value_type 的常引用。
iterator_category被定义为input_iterator_tag,标识这个迭代器的类型是 input iterator(输入迭代器)。
一种实现方式如下:
让 ++ 负责读取,* 负责返回读取的内容。这个 iterator 类需要有一个数据成员指向输入流,一个数据成员来存放读取的结果。
class istream_line_reader {
public:
class iterator {
…
iterator() noexcept
: stream_(nullptr) {}
explicit iterator(istream& is)
: stream_(&is)
{
++*this; // 注意,调用 前置++,读取内容,保证构造后可以通过 * 获取内容
}
reference operator*() const noexcept
{
return line_;
}
pointer operator->() const noexcept
{
return &line_;
}
// 前置++
iterator& operator++()
{
getline(*stream_, line_);
if (!*stream_) {
stream_ = nullptr;
}
return *this;
}
// 后置++,通过 前置++ 和 拷贝构造 实现(迭代器要求前置和后置 ++ 都要定义)
iterator operator++(int)
{
iterator temp(*this);
++*this;
return temp;
}
private:
istream* stream_;
string line_;
};
…
};
- 定义了默认构造函数,将 stream_ 清空
- 在带参数的构造函数里,根据传入的输入流来设置 stream_
- 定义了
*和->运算符来取得迭代器指向的文本行的引用和指针 - 用
++来读取输入流的内容(后置 ++则以惯常方式使用前置 ++和拷贝构造来实现)
注意:唯一“特别”点的地方,是在构造函数里调用了 ++,确保在构造后调用 * 运算符时可以读取内容,符合日常先使用 *、再使用 ++ 的习惯。一旦文件读取到尾部(或出错),则 stream_ 被清空,回到默认构造的情况。
对于迭代器之间的比较,则主要考虑文件有没有读到尾部的情况,简单定义为:
bool operator==(const iterator& rhs) const noexcept
{
return stream_ == rhs.stream_;
}
bool operator!=(const iterator& rhs) const noexcept
{
return !operator==(rhs);
}
有了这个 iterator 的定义后,istream_line_reader 的定义就简单得很了:
class istream_line_reader {
public:
class iterator {…};
istream_line_reader() noexcept
: stream_(nullptr) {}
explicit istream_line_reader(
istream& is) noexcept
: stream_(&is) {}
iterator begin()
{
return iterator(*stream_);
}
iterator end() const noexcept
{
return iterator();
}
private:
istream* stream_;
};
- 构造函数只是简单地把输入流的指针赋给 stream_ 成员变量
- begin 成员函数则负责构造一个真正有意义的迭代器
- end 成员函数则只是返回一个默认构造的迭代器而已
以上就是一个完整的基于输入流的行迭代器了。这个行输入模板的设计动机和性能测试结果可参见参考资料 Python yield and C++ coroutines 和 Performance of my line readers;完整的工程可用代码,请参见https://github.com/adah1972/nvwa/。该项目中还提供了利用 C 文件接口的 file_line_reader 和基于内存映射文件的 mmap_line_reader。
注意以上实现存在一定的使用限制,不能多次调用begin。
#include <fstream>
#include <iostream>
#include "istream_line_reader.h"
using namespace std;
int main()
{
ifstream ifs{"test.cpp"};
istream_line_reader reader{ifs};
auto begin = reader.begin();
for (auto it = reader.begin();
it != reader.end(); ++it) {
cout << *it << '\n';
}
}
// 以上代码,因为 begin 多调用了一次,输出就少了一行……
C++易用性改进
auto
auto 自动类型推断,顾名思义,就是编译器能够根据表达式的类型,自动决定变量的类型(从 C++14 开始,还有函数的返回类型),不再需要程序员手工声明。但需要说明的是,auto 并没有改变 C++ 是静态类型语言这一事实——使用 auto 的变量(或函数返回值)的类型仍然是编译时就确定了,只不过编译器能自动帮你填充而已。
// 完整的写法
vector<int> v;
for (vector<int>::iterator
it = v.begin(),
end = v.end();
it != end; ++it) {
// 循环体
}
// auto的简化写法
for (auto it = v.begin(), end = v.end();
it != end; ++it) {
// 循环体
}
不使用自动类型推断时,如果容器类型未知的话,还需要加上 typename:
template <typename T>
void foo(const T& container)
{
for (typename T::const_iterator
it = v.begin(),
// …
) {}
}
decltype
decltype 的用途是获得一个表达式的类型,结果可以跟类型一样使用。它有两个基本用法:
decltype(变量名)可以获得变量的精确类型。decltype(表达式)(表达式不是变量名,但包括 decltype((变量名)) 的情况)可以获得表达式的引用类型;除非表达式的结果是个纯右值(prvalue),此时结果仍然是值类型。
例如:int a;,那么:
- decltype(a) 会获得 int(因为 a 是 int)
- decltype((a)) 会获得 int&(因为 a 是 lvalue)
- decltype(a + a) 会获得 int(因为 a + a 是 prvalue)
decltype(auto)
decltype(expr) 既可以是值类型,也可以是引用类型。
decltype(expr) a = expr;
这种写法明显不能让人满意,特别是表达式很长的情况(而且,任何代码重复都是潜在的问题)。为此,C++14 引入了 decltype(auto) 语法。对于上面的情况,只需要像下面这样写就行了。
decltype(auto) a = expr;
这种代码主要用在通用的转发函数模板中:你可能根本不知道你调用的函数是不是会返回一个引用。这时使用这种语法就会方便很多。
函数返回值类型推断
后置返回值类型声明。通常,在返回类型比较复杂、特别是返回类型跟参数类型有某种推导关系时会使用这种语法。
auto foo(参数) -> 返回值类型声明
{
// 函数体
}
类模板的模板参数推导
因为函数模板有模板参数推导,使得调用者不必手工指定参数类型;但 C++17 之前的类模板却没有这个功能,也因而催生了像 make_pair 这样的工具函数:
pair pr{1, 42}; // 一般不这样写
auto pr = make_pair(1, 42);// 一般这样写
在进入了 C++17 的世界后,这类函数变得不必要了。现在可以直接写:
pair pr{1, 42};
这种自动推导机制,可以是编译器根据构造函数来自动生成:
template <typename T>
struct MyObj {
MyObj(T value);
…
};
MyObj obj1{string("hello")};
// 得到 MyObj<string>
MyObj obj2{"hello"};
// 得到 MyObj<const char*>
结构化绑定
multimap<string, int>::iterator lower, upper;
std::tie(lower, upper) = mmp.equal_range("four");
返回值是个 pair,希望用两个变量来接收数值,就不得不声明了两个变量,然后使用 tie 来接收结果。在 C++11/14 里,这里是没法使用 auto 的。好在 C++17 引入了一个新语法,解决了这个问题。可以把上面的代码简化为:
auto [lower, upper] = mmp.equal_range("four");
列表初始化
在 C++98 里,标准容器比起 C 风格数组至少有一个明显的劣势:不能在代码里方便地初始化容器的内容。比如,对于数组可以写:
int a[] = {1, 2, 3, 4, 5};
而对于 vector 却得写:
vector<int> v;
v.push(1);
v.push(2);
于是,C++ 标准委员会引入了列表初始化,允许以更简单的方式来初始化对象。现在初始化容器也可以和初始化数组一样简单了:
vector<int> v{1, 2, 3, 4, 5};
从技术角度,编译器的魔法只是对 {1, 2, 3} 这样的表达式自动生成一个初始化列表,在这个例子里其类型是 initializer_list。程序员只需要声明一个接受 initializer_list 的构造函数即可使用。
统一初始化
几乎可以在所有初始化对象的地方使用大括号而不是小括号。
Obj getObj()
{
return {1.0};
}
{1.0} 跟 Obj(1.0) 的主要区别是,后者可以用来调用 Obj(int),而使用大括号时编译器会拒绝“窄”转换,不接受以 {1.0} 或 Obj{1.0} 的形式调用构造函数 Obj(int)。
这个语法主要的限制是,如果一个类既有使用初始化列表的构造函数,又有不使用初始化列表的构造函数,那编译器会千方百计地试图调用使用初始化列表的构造函数,导致各种意外。所以,如果给一个推荐的话,那就是:
- 如果一个类没有使用初始化列表的构造函数时,初始化该类对象可全部使用统一初始化语法。
- 如果一个类有使用初始化列表的构造函数时,则只应用在初始化列表构造的情况。
类数据成员的默认初始化
按照 C++98 的语法,数据成员可以在构造函数里进行初始化。这本身不是问题,但实践中,如果数据成员比较多、构造函数又有多个的话,逐个去初始化是个累赘,并且很容易在增加数据成员时漏掉在某个构造函数中进行初始化。为此,C++11 增加了一个语法,允许在声明数据成员时直接给予一个初始化表达式。这样,当且仅当构造函数的初始化列表中不包含该数据成员时,这个数据成员就会自动使用初始化表达式进行初始化。
使用数据成员的默认初始化的话,可以这么写:
class Complex {
public:
Complex() {}
Complex(float re) : re_(re) {}
Complex(float re, float im)
: re_(re) , im_(im) {}
private:
float re_{0};
float im_{0};
};
- 第一个构造函数没有任何初始化列表,所以类数据成员的初始化全部由默认初始化完成,re_ 和 im_ 都是 0。
- 第二个构造函数提供了 re_ 的初始化,im_ 仍由默认初始化完成。
- 第三个构造函数则完全不使用默认初始化。
自定义字面量
字面量(literal)是指在源代码中写出的固定常量,它们在 C++98 里只能是原生类型,如:
"hello",字符串字面量,类型是const char[6]1,整数字面量,类型是int0.0,浮点数字面量,类型是double3.14f,浮点数字面量,类型是float123456789ul,无符号长整数字面量,类型是unsigned long
C++11 引入了自定义字面量,可以使用 operator"" 后缀,来将用户提供的字面量转换成实际的类型。
#include <chrono>
#include <complex>
#include <iostream>
#include <string>
#include <thread>
using namespace std;
int main()
{
cout << "i * i = " << 1i * 1i
<< endl;
cout << "Waiting for 500ms"
<< endl;
this_thread::sleep_for(500ms);
cout << "Hello world"s.substr(0, 5)
<< endl;
}
上面这个例子展示了 C++ 标准里提供的帮助生成虚数、时间和 basic_string 字面量的后缀。
如何在自己的类里支持字面量?
struct length {
double value;
enum unit {
metre,
kilometre,
millimetre,
centimetre,
inch,
foot,
yard,
mile,
};
static constexpr double factors[] =
{1.0, 1000.0, 1e-3,
1e-2, 0.0254, 0.3048,
0.9144, 1609.344};
explicit length(double v,
unit u = metre)
{
value = v * factors[u];
}
};
length operator+(length lhs,
length rhs)
{
return length(lhs.value +
rhs.value);
}
// 可能有其他运算符
可以手写 length(1.0, length::metre) 这样的表达式,但估计大部分开发人员都不愿意这么做,而更希望是 1.0_m + 10.0_cm。要允许这个表达式,只需要提供下面的运算符即可:
length operator"" _m(long double v)
{
return length(v, length::metre);
}
length operator"" _cm(long double v)
{
return length(v, length::centimetre);
}
二进制字面量
从 C++14 开始,对于二进制也有了直接的字面量:
unsigned mask = 0b111000000;
这在需要比特级操作等场合还是非常有用的。
数字分隔符
数字长了之后,看清位数就变得麻烦了。有了二进制字面量,这个问题变得分外明显。C++14 开始,允许在数字型字面量中任意添加 ' 来使其更可读。具体怎么添加,完全由程序员根据实际情况进行约定。某些常见的情况可能会是:
- 十进制数字使用三位的分隔,对应英文习惯的 thousand、million 等单位。
- 十进制数字使用四位的分隔,对应中文习惯的万、亿等单位。
- 十六进制数字使用两位或四位的分隔,对应字节或双字节。
- 二进制数字使用三位的分隔,对应文件系统的权限分组。
- 等等。
例子:
unsigned mask = 0b111'000'000;
long r_earth_equatorial = 6'378'137;
double pi = 3.14159'26535'89793;
const unsigned magic = 0x44'42'47'4E;
静态断言
C++98 的 assert 允许在运行时检查一个函数的前置条件是否成立。没有一种方法允许开发人员在编译的时候检查假设是否成立。
C++11 直接从语言层面提供了静态断言机制,不仅能输出更好的信息,而且适用性也更好,可以直接放在类的定义中。
static_assert(编译期条件表达式,
可选输出信息);
例如:
static_assert((alignment & (alignment - 1)) == 0,
"Alignment must be power of two");
default 和 delete 成员函数
在类的定义时,C++ 有一些规则决定是否生成默认的特殊成员函数。这些特殊成员函数可能包括:
默认构造函数/析构函数/拷贝构造函数/拷贝赋值函数/移动构造函数/移动赋值函数
生成这些特殊成员函数(或不生成)的规则比较复杂。
每个特殊成员函数有几种不同的状态:
- 隐式声明还是用户声明
- 默认提供还是用户提供
- 正常状态还是删除状态
这三个状态是可组合的,虽然不是所有的组合都有效。隐式声明的必然是默认提供的;默认提供的才可能被删除;用户提供的也必然是用户声明的。
经验:
- 如果正常情况不需要复制行为、只是想防止其他开发人员误操作时,可以简单地在类的定义中加入:
class shape_wrapper {
…
shape_wrapper(
const shape_wrapper&) = delete;
shape_wrapper& operator=(
const shape_wrapper&) = delete;
…
};
在 C++11 之前,我们可能会用在 private 段里声明这些成员函数的方法,来达到相似的目的。但目前这个语法效果更好,可以产生更明确的错误信息。另外,你可以注意一下,用户声明成删除也是一种声明,因此编译器不会提供默认版本的移动构造和移动赋值函数。
override 和 final 说明符
override 和 final 是两个 C++11 引入的新说明符。它们不是关键词,仅在出现在函数声明尾部时起作用,不影响我们使用这两个词作变量名等其他用途。这两个说明符可以单个或组合使用,都是加在类成员函数声明的尾部。
override 显式声明了成员函数是一个虚函数且覆盖了基类中的该函数。如果有 override 声明的函数不是虚函数,或基类中不存在这个虚函数,编译器会报告错误。这个说明符的主要作用有两个:
- 给开发人员更明确的提示,这个函数覆写了基类的成员函数;
- 让编译器进行额外的检查,防止程序员由于拼写错误或代码改动没有让基类和派生类中的成员函数名称完全一致;
final 则声明了成员函数是一个虚函数,且该虚函数不可在派生类中被覆盖。如果有一点没有得到满足的话,编译器就会报错。
final 还有一个作用是标志某个类或结构不可被派生。同样,这时应将其放在被定义的类或结构名后面。
例子:
class A {
public:
virtual void foo();
virtual void bar();
void foobar();
};
class B : public A {
public:
void foo() override; // OK
void bar() override final; // OK
//void foobar() override; // 非虚函数不能 override
};
class C final : public B {
public:
void foo() override; // OK
//void bar() override; // final 函数不可 override
};
class D : public C {
// 错误:final 类不可派生
…
};
到底应不应该返回对象?
《C++ 核心指南》的 Bjarne Stroustrup and Herb Sutter (editors), “C++ core guidelines”, item F.20 或者非官方版本,这一条款是这么说的:
F.20: For “out” output values, prefer return values to output parameters
在函数输出数值时,尽量使用返回值而非输出参数。
之前的做法:调用者负责管理内存,接口负责生成
一种常见的做法是,接口的调用者负责分配一个对象所需的内存并负责其生命周期,接口负责生成或修改该对象。这种做法意味着对象可以默认构造(甚至只是一个结构),代码一般使用错误码而非异常。例如:
MyObj obj;
ec = initialize(&obj);
// …
另一种做法:接口负责对象的堆上生成和内存管理
另外一种可能的做法是接口提供生成和销毁对象的函数,对象在堆上维护。fopen 和 fclose 就是这样的接口的实例。
如何返回一个对象?
- 一个用来返回的对象,通常应当是可移动构造 / 赋值的,一般也同时是可拷贝构造 / 赋值的。
- 如果这样一个对象同时又可以默认构造,我们就称其为一个半正则(semiregular)的对象。如果可能的话,应当尽量让我们的类满足半正则这个要求。
class matrix {
public:
// 普通构造
matrix(size_t rows, size_t cols);
// 半正则要求的构造
matrix();
matrix(const matrix&);
matrix(matrix&&);
// 半正则要求的赋值
matrix& operator=(const matrix&);
matrix& operator=(matrix&&);
};
在没有返回值优化的情况下 C++ 是怎样返回对象的?
matrix operator*(const matrix& lhs,
const matrix& rhs)
{
if (lhs.cols() != rhs.rows()) {
throw runtime_error("sizes mismatch");
}
matrix result(lhs.rows(), rhs.cols());
// 具体计算过程
return result;
}
- 注意对于一个本地变量,我们永远不应该返回其引用(或指针),不管是作为左值还是右值。从标准的角度,这会导致未定义行为(undefined behavior)
- 从实际的角度,这样的对象一般放在栈上可以被调用者正常覆盖使用的部分,随便一个函数调用或变量定义就可能覆盖这个对象占据的内存。这还是这个对象的析构不做事情的情况:如果析构函数会释放内存或破坏数据的话,那你访问到的对象即使内存没有被覆盖,也早就不是有合法数据的对象了……
- 返回非引用类型的表达式结果是个纯右值(prvalue)。在执行 auto r = … 的时候,编译器会认为我们实际是在构造 matrix r(…),而“…”部分是一个纯右值。因此编译器会首先试图匹配
matrix(matrix&&),在没有时则试图匹配matrix(const matrix&);也就是说,有移动支持时使用移动,没有移动支持时则拷贝。
返回值优化(拷贝消除)
#include <iostream>
using namespace std;
// Can copy and move
class A {
public:
A() { cout << "Create A\n"; }
~A() { cout << "Destroy A\n"; }
A(const A&) { cout << "Copy A\n"; }
A(A&&) { cout << "Move A\n"; }
};
A getA_unnamed()
{
return A();
}
int main()
{
auto a = getA_unnamed();
}
如果你认为执行结果里应当有一行“Copy A”或“Move A”的话,你就忽视了返回值优化的威力了。
即使完全关闭优化,三种主流编译器(GCC、Clang 和 MSVC)都只输出两行:
Create A
Destroy A
把代码稍稍改一下:
A getA_named()
{
A a;
return a;
}
int main()
{
auto a = getA_named();
}
这回结果有了一点点小变化。虽然 GCC 和 Clang 的结果完全不变,但 MSVC 在非优化编译的情况下产生了不同的输出(优化编译——使用命令行参数 /O1、/O2 或 /Ox——则不变):
Create A
Move A
Destroy A
Destroy A
也就是说,返回内容被移动构造了。
继续变形一下:
#include <stdlib.h>
A getA_duang()
{
A a1;
A a2;
if (rand() > 42) {
return a1;
} else {
return a2;
}
}
int main()
{
auto a = getA_duang();
}
这回所有的编译器都被难倒了,输出是:
Create A
Create A
Move A
Destroy A
Destroy A
Destroy A
关于返回值优化的实验我们就做到这里。下一步,我们试验一下把移动构造函数删除:
A(A&&) = delete;
可以立即看到“Copy A”出现在了结果输出中,说明目前结果变成拷贝构造了。
如果再进一步,把拷贝构造函数也删除呢?是不是上面的 getA_unnamed、getA_named 和 getA_duang 都不能工作了?
在 C++14 及之前确实是这样的。但从 C++17 开始,对于类似于 getA_unnamed 这样的情况,即使对象不可拷贝、不可移动,这个对象仍然是可以被返回的!C++17 要求对于这种情况,对象必须被直接构造在目标位置上,不经过任何拷贝或移动的步骤。refer: cppreference.com, “Copy elision”
理解了 C++ 里的对返回值的处理和返回值优化之后,我们再回过头看一下 F.20 里陈述的理由的话,应该就显得很自然了:
A return value is self-documenting, whereas a & could be either in-out or out-only and is liable to be misused.
返回值是可以自我描述的;而 & 参数既可能是输入输出,也可能是仅输出,且很容易被误用。(当然也有一些例外的情况)
总结:
在 C++11 之前,返回一个本地对象意味着这个对象会被拷贝,除非编译器发现可以做返回值优化(named return value optimization,或 NRVO),能把对象直接构造到调用者的栈上。从 C++11 开始,返回值优化仍可以发生,但在没有返回值优化的情况下,编译器将试图把本地对象移动出去,而不是拷贝出去。这一行为不需要程序员手工用 std::move 进行干预——使用std::move 对于移动行为没有帮助,反而会影响返回值优化。
Unicode:进入多文字支持的世界
从编码的历史谈起,讨论编程中对中文和多语言的支持,然后重点看一下 C++ 中应该如何处理这些问题。
一些历史
ASCII (American Standard Code for Information Interchange) 是一种创立于 1963 年的 7 位编码,用 0 到 127 之间的数值来代表最常用的字符,包含了控制字符(很多在今天已不再使用)、数字、大小写拉丁字母、空格和基本标点。它在编码上具有简单性,字母和数字的编码位置非常容易记忆。时至今日,ASCII 可以看作是字符编码的基础,主要的编码方式都保持着与 ASCII 的兼容性。
ASCII 里只有基本的拉丁字母,它既没有带变音符的拉丁字母(如 é 和 ä ),也不支持像希腊字母(如 α、β、γ)、西里尔字母(如 Пушкин)这样的其他欧洲文字(也难怪,毕竟它是 American Standard Code for Information Interchange)。很多其他编码方式纷纷应运而生,包括 ISO 646 系列、ISO/IEC 8859 系列等等;大部分编码方式都是头 128 个字符与 ASCII 兼容,后 128 个字符是自己的扩展,总共最多是 256 个字符。每次只有一套方式可以生效,称之为一个代码页(code page)。这种做法,只能适用于文字相近、且字符数不多的国家。比如,ISO-8859-1(也称作 Latin-1)和后面的 Windows 扩展代码页 1252,就只能适用于西欧国家。
最早的中文字符集标准是 1980 年的国标 GB2312,其中收录了 6763 个常用汉字和 682 个其他符号。我们平时会用到编码 GB2312,其实更正确的名字是 EUC-CN,它是一种与 ASCII 兼容的编码方式。它用单字节表示 ASCII 字符而用双字节表示 GB2312 中的字符;由于 GB2312 中本身也含有 ASCII 中包含的字符,在使用中逐渐就形成了“半角”和“全角”的区别。
国标字符集后面又有扩展,这个扩展后的字符集就是 GBK,是中文版 Windows 使用的标准编码方式。GB2312 和 GBK 所占用的编码位置可以参看下面的图(由 John M. Długosz 为 Wikipedia 绘制):
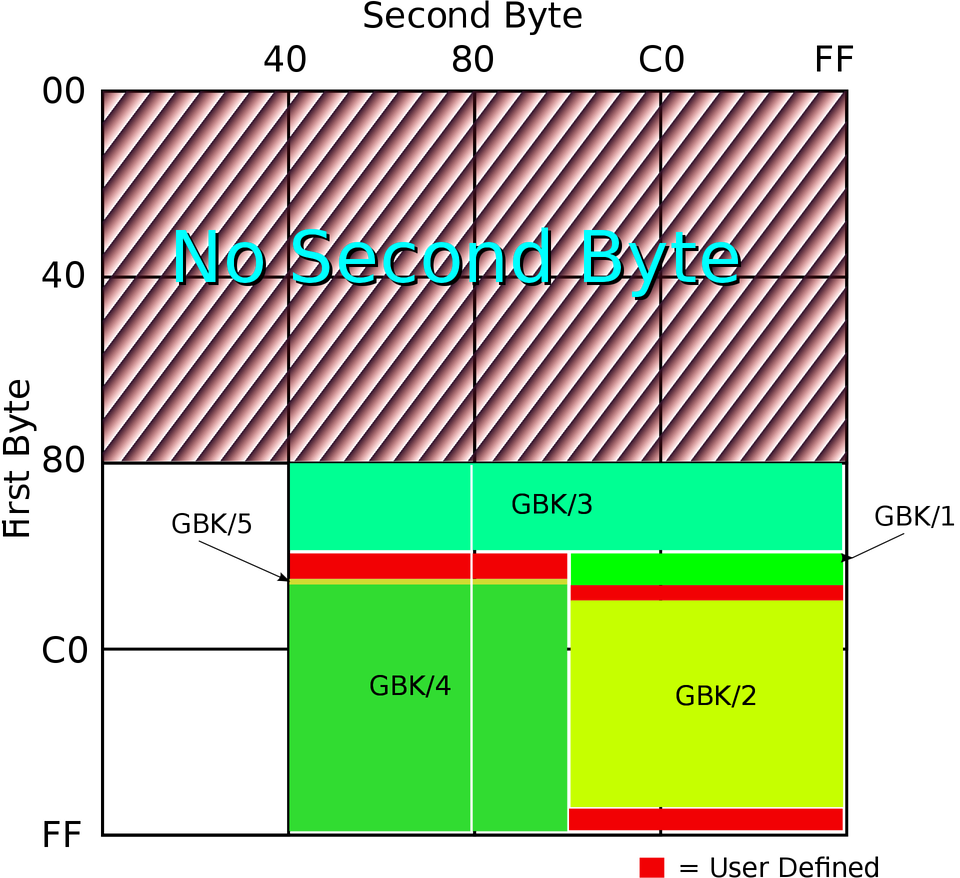
图中 GBK/1 和 GBK/2 为 GB2312 中已经定义的区域,其他的则是后面添加的字符,总共定义了两万多个编码点,支持了绝大部分现代汉语中还在使用的字。
Unicode作为一种统一编码的努力,诞生于八十年代末九十年代初,标准的第一版出版于 1991—1992 年。由于最初发明者的目标放得太低,只期望对活跃使用中的现代文字进行编码,他们认为 16 比特的“宽 ASCII”就够用了。这就导致了早期采纳 Unicode 的组织,特别是微软,在其操作系统和工具链中广泛采用了 16 比特的编码方式。在今天,微软的系统中宽字符类型 wchar_t 仍然是 16 位的,操作系统底层接口大量使用 16 位字符编码的 API,说到 Unicode 编码时仍然指的是 16 位的编码 UTF-16(这一不太正确的名字,跟中文 GBK 编码居然可以被叫做 ANSI 相比,实在是小巫见大巫了)。在微软以外的世界,Unicode 本身不作编码名称用,并且最主流的编码方式并不是 UTF-16,而是和 ASCII 全兼容的 UTF-8。
Unicode 简介
Unicode 在今天已经大大超出了最初的目标。到 Unicode 12.1 为止,Unicode 已经包含了 137,994 个字符,囊括所有主要语言(使用中的和已经不再使用的),并包含了表情符号、数学符号等各种特殊字符。
Unicode 的编码点是从 0x0 到 0x10FFFF,一共 1,114,112 个位置。一般用“U+”后面跟 16 进制的数值来表示一个 Unicode 字符,如 U+0020 表示空格,U+6C49 表示“汉”,U+1F600 表示“😀”,等等(不足四位的一般写四位)。
Unicode 字符的常见编码方式有:
- UTF-32
- 32 比特,是编码点的直接映射
- UTF-16
- 对于从 U+0000 到 U+FFFF 的字符,使用 16 比特的直接映射
- UTF-8
- 1 到 4 字节的变长编码
例子:
UTF-32:U+0020 映射为 0x00000020,U+6C49 映射为 0x00006C49,U+1F600 映射为 0x0001F600。
UTF-16:U+0020 映射为 0x0020,U+6C49 映射为 0x6C49,而 U+1F600 会映射为 0xD83D DE00。
UTF-8:U+0020 映射为 0x20,U+6C49 映射为 0xE6 B1 89,而 U+1F600 会映射为 0xF0 9F 98 80。
在上面三种编码方式里,只有 UTF-8 完全保持了和 ASCII 的兼容性,目前得到了最广泛的使用。
任何一种编码方式需要跟传统的编码方式容易区分,因此,Unicode 文本文件通常有一个使用 BOM(byte order mark)字符的约定,即字符 U+FEFF。在文件开头加一个 BOM 即可区分各种不同编码。
例如:
如果文件开头是 0xEF BB BF,那这是 UTF-8 编码。
编辑器可以(有些在配置之后)根据 BOM 字符来自动决定文本文件的编码。
比如,一般在 Vim 中配置 set fileencodings=ucs-bom,utf-8,gbk,latin1。这样,Vim 在读入文件时,会首先检查 BOM 字符,有 BOM 字符按 BOM 字符决定文件编码;否则,试图将文件按 UTF-8 来解码(由于 UTF-8 有格式要求,非 UTF-8 编码的文件通常会导致失败);不行,则试图按 GBK 来解码(失败的概率就很低了);还不行,就把文件当作 Latin1 来处理(永远不会失败)。
在 UTF-8 编码下使用 BOM 字符并非必需,尤其在 Unix 上。但 Windows 上通常会使用 BOM 字符,以方便区分 UTF-8 和传统编码。
编译期多态:泛型编程和模板入门
面向对象和多态
在面向对象的开发里,最基本的一个特性就是“多态” —— 用相同的代码得到不同结果。以 shape 类为例,它可能会定义一些通用的功能,然后在子类里进行实现或覆盖:
class shape {
public:
…
void draw(const position&) = 0;
};
上面的类定义意味着所有的子类必须实现 draw 函数,所以可以认为 shape 是定义了一个接口(按 Java 的概念)。在面向对象的设计里,接口抽象了一些基本的行为,实现类里则去具体实现这些功能。当我们有着接口类的指针或引用时,我们实际可以唤起具体的实现类里的逻辑。
比如,在一个绘图程序里,我们可以在用户选择一种形状时,把形状赋给一个 shape 的(智能)指针,在用户点击绘图区域时,执行 draw 操作。根据指针指向的形状不同,实际绘制出的可能是圆,可能是三角形,也可能是其他形状。
但这种面向对象的方式,并不是唯一一种实现多态的方式。在很多动态类型语言里,有所谓的“鸭子”类型:
如果一只鸟走起来像鸭子、游起泳来像鸭子、叫起来也像鸭子,那么这只鸟就可以被当作鸭子。
在这样的语言里,你可以不需要继承来实现 circle、triangle 等类,然后可以直接在这个类型的变量上调用 draw 方法。如果这个类型的对象没有 draw 方法,你就会在执行到 draw() 语句的时候得到一个错误(或异常)。
鸭子类型使得开发者可以不使用继承体系来灵活地实现一些“约定”,尤其是使得混合不同来源、使用不同对象继承体系的代码成为可能。唯一的要求只是,这些不同的对象有“共通”的成员函数。这些成员函数应当有相同的名字和相同结构的参数(并不要求参数类型相同)。
容器类的共性
容器类是有很多共性的。其中,一个最最普遍的共性就是,容器类都有 begin 和 end 成员函数——这使得通用地遍历一个容器成为可能。容器类不必继承一个共同的 Container 基类,而我们仍然可以写出通用的遍历容器的代码,如使用基于范围的循环。
大部分容器是有 size 成员函数的,在“泛型”编程中,我们同样可以取得一个容器的大小,而不要求容器继承一个叫 SizeableContainer 的基类。
很多容器具有 push_back 成员函数,可以在尾部插入数据。同样,我们不需要一个叫 BackPushableContainer 的基类。在这个例子里,push_back 函数的参数显然是都不一样的,但明显,所有的 push_back 函数都只接收一个参数。
我们可以清晰看到的是,虽然 C++ 的标准容器没有对象继承关系,但彼此之间有着很多的同构性。这些同构性很难用继承体系来表达,也完全不必要用继承来表达。C++ 的模板,已经足够表达这些鸭子类型。
当然,作为一种静态类型语言,C++ 是不会在运行时才报告“没找到 draw 方法”这类问题的。这类错误可以在编译时直接捕获,更精确地来说,是在模板实例化的过程中。
C++ 模板
定义模板函数
// 求最大公约数的辗转相除法
template <typename E>
E my_gcd(E a, E b)
{
while (b != E(0)) {
E r = a % b;
a = b;
b = r;
}
return a;
}
除了函数模版,还有类模板,比如智能指针类。
实例化模板
不管是类模板还是函数模板,编译器在看到其定义时只能做最基本的语法检查,真正的类型检查要在实例化(instantiation)的时候才能做。一般而言,这也是编译器会报错的时候。
实例化失败的话,编译当然就出错退出了。如果成功的话,模板的实例就产生了。在整个的编译过程中,可能产生多个这样的(相同)实例,但最后链接时,会只剩下一个实例。这也是为什么 C++ 会有一个单一定义的规则:如果不同的编译单元看到不同的定义的话,那链接时使用哪个定义是不确定的,结果就可能会让人吃惊。
模板还可以显式实例化(使用 template 关键字并给出完整的类型来声明函数)和外部实例化。
注意:显式实例化和外部实例化通常在大型项目中可以用来集中模板的实例化,从而加速编译过程——不需要在每个用到模板的地方都进行实例化了——但这种方式有额外的管理开销,如果实例化了不必要实例化的模板的话,反而会导致可执行文件变大。因而,显式实例化和外部实例化应当谨慎使用。
特化模板
我们需要使用的模板参数类型,不能完全满足模板的要求,应该怎么办?
实际上有好几个选择:
- 添加代码,让那个类型支持所需要的操作(对成员函数无效,在很多情况下,尤其是对对象的成员函数有要求的情况下,这个方法不可行)。
- 对于函数模板,可以直接针对那个类型进行重载。
- 对于类模板和函数模板(,可以针对那个类型进行特化。
特化的例子:
template <typename E>
E my_mod(const E& lhs,
const E& rhs)
{
return lhs % rhs;
}
// 针对 cln::cl_I 类型的特化
template <>
cln::cl_I my_mod<cln::cl_I>(
const cln::cl_I& lhs,
const cln::cl_I& rhs)
{
return mod(lhs, rhs);
}
注意: ** 1. 特化和重载在行为上没有本质的区别。就一般而言,特化是一种更通用的技巧,最主要的原因是特化可以用在类模板和函数模板上,而重载只能用于函数。** ** 2. Herb Sutter 给出了明确的建议:对函数使用重载,对类模板进行特化。refer: Herb Sutter, “Why not specialize function templates?”** (重载比特化优先。一般而言,函数特化是不推荐的)
展示特化的更好的例子是 C++11 之前的静态断言。使用特化技巧可以大致实现 static_assert 的功能:
template <bool>
struct compile_time_error;
template <>
struct compile_time_error<true> {};
#define STATIC_ASSERT(Expr, Msg) \
{ \
compile_time_error<bool(Expr)> \
ERROR_##_Msg; \
(void)ERROR_##_Msg; \
}
原理:
上面首先声明了一个 struct 模板,然后仅对 true 的情况进行了特化,产生了一个 struct 的定义。这样。如果遇到 compile_time_error<false> 的情况——也就是下面静态断言里的 Expr 不为真的情况——编译就会失败报错,因为 compile_time_error<false> 从来就没有被定义过。
“动态”多态和“静态”多态的对比
面向对象的“动态”多态 和 基于泛型编程的“静态”多态,两者解决的实际上是不太一样的问题。
- “动态”多态解决的是运行时的行为变化——例如,选择了一个形状之后,再选择在某个地方绘制这个形状——这个是无法在编译时确定的。
- “静态”多态或者“泛型”——解决的是很不同的问题,让适用于不同类型的“同构”算法可以用同一套代码来实现,实际上强调的是对代码的复用。
问题:为什么并非所有的语言都支持这些不同的多态方式?
以 Python 为例,它是动态类型的语言。所以它不会有真正的静态多态。但和静态类型的面向对象语言(如 Java)不同,它的运行期多态不需要继承。没有参数化多态初看是个缺陷,但由于 Python 的动态参数系统允许默认参数和可变参数,并没有什么参数化多态能做得到而 Python 做不到的事。
RTTI(运行期)
decltype 得到的是编译期的类型。运行期的类型,C++ 里挺有争议(跟异常类似)的功能——RTTI。(还是要强调一句,你应该考虑是否用虚函数可以达到你需要的功能。很多项目,如 Google 的,会禁用 RTTI。)
可以用 typeid 直接来获取对象的实际类型,例如:
#include <iostream>
#include <typeinfo>
#include <boost/core/demangle.hpp>
using namespace std;
using boost::core::demangle;
class shape {
public:
virtual ~shape() {}
};
class circle : public shape {
};
int main()
{
shape* ptr = new circle();
auto& type = typeid(*ptr);
cout << type.name() << endl;
cout << demangle(type.name()) << endl;
cout << boolalpha;
cout << (type == typeid(shape) ? "is shape\n" : "");
cout << (type == typeid(circle) ? "is circle\n" : "");
delete ptr;
}
在 GCC 下的输出:
6circle
circle
is circle
编译期计算(模板元编程)
编译期能做些什么?一个完整的计算世界
首先,我们给出一个已经被证明的结论:C++ 模板是图灵完全的 refer: Todd L. Veldhuizen, “C++ templates are Turing complete”。这句话的意思是,使用 C++ 模板,你可以在编译期间模拟一个完整的图灵机,也就是说,可以完成任何的计算任务。
当然,这只是理论上的结论。从实际的角度,我们并不想、也不可能在编译期完成所有的计算,更不用说编译期的编程是很容易让人看不懂的——因为这并不是语言设计的初衷。
但是,即便如此,我们也还是需要了解一下模板元编程的基本概念:它仍然有一些实用的场景,并且在实际的工程中你也可能会遇到这样的代码。虽然我们在开篇就说过不要炫技,但使用模板元编程写出的代码仍然是可理解的,尤其是如果你对递归不发怵的话。
计算阶乘
template <int n>
struct factorial {
static const int value =
n * factorial<n - 1>::value;
};
template <>
struct factorial<0> {
static const int value = 1;
};
注意,要先定义,才能特化。那怎么知道这个计算是不是在编译时做的呢?可以直接看编译输出。下面直接贴出对上面这样的代码加输出(printf("%d\n", factorial<10>::value);)在 x86-64 下的编译结果:
.LC0:
.string "%d\n"
main:
push rbp
mov rbp, rsp
mov esi, 3628800
mov edi, OFFSET FLAT:.LC0
mov eax, 0
call printf
mov eax, 0
pop rbp
ret
编译结果直接出现了常量 3628800。上面那些递归什么的,完全都没有了踪影。
如果我们传递一个负数给 factorial 呢?这时的结果就应该是编译期间的递归溢出。如 GCC 会报告:
fatal error: template instantiation depth exceeds maximum of 900 (use -ftemplate-depth= to increase the maximum)
通用的解决方案是使用 static_assert,确保参数永远不会是负数。
template <int n>
struct factorial {
static_assert(
n >= 0,
"Arg must be non-negative");
static const int value =
n * factorial<n - 1>::value;
};
这样,当 factorial 接收到一个负数作为参数时,就会得到一个干脆的错误信息:
error: static assertion failed: Arg must be non-negative
结论:可以看到,要进行编译期编程,最主要的一点,是需要把计算转变成类型推导。
条件语句
再看一个例子,下面的模板可以代表条件语句:
template <bool cond,
typename Then,
typename Else>
struct If;
template <typename Then,
typename Else>
struct If<true, Then, Else> {
typedef Then type;
};
template <typename Then,
typename Else>
struct If<false, Then, Else> {
typedef Else type;
};
- If 模板有三个参数,第一个是布尔值,后面两个则是代表不同分支计算的类型
- 第一个 struct 声明规定了模板的形式,然后我们不提供通用定义,而是提供了两个特化
- 第一个特化是真的情况,定义结果 type 为 Then 分支;第二个特化是假的情况,定义结果 type 为 Else 分支
下面的函数和模板是基本等价的:
int foo(int n)
{
if (n == 2 || n == 3 || n == 5) {
return 1;
} else {
return 2;
}
}
template <int n>
struct Foo {
typedef typename If<
(n == 2 || n == 3 || n == 5),
integral_constant<int, 1>,
integral_constant<int, 2>>::type
type;
};
// foo(3) 等价于 Foo<3>::type::value
循环
另一个例子,循环:
template <bool condition,
typename Body>
struct WhileLoop;
template <typename Body>
struct WhileLoop<true, Body> {
typedef typename WhileLoop<
Body::cond_value,
typename Body::next_type>::type
type;
};
template <typename Body>
struct WhileLoop<false, Body> {
typedef
typename Body::res_type type;
};
template <typename Body>
struct While {
typedef typename WhileLoop<
Body::cond_value, Body>::type
type;
};
- 首先,我们对循环体类型有一个约定,它必须提供一个静态数据成员,cond_value,及两个子类型定义,res_type 和 next_type。
- cond_value 代表循环的条件(真或假)
- res_type 代表退出循环时的状态
- next_type 代表下面循环执行一次时的状态
- 这里面比较绕的地方是用类型来代表执行状态,把例子多看两遍,自己编译、修改、把玩一下,就会渐渐理解的。
- 用
::取一个成员类型、并且::左边有模板参数的话,得额外加上typename关键字来标明结果是一个类型
通用的代表数值的类型
下面这个模板可以通用地代表一个整数常数:
template <class T, T v>
struct integral_constant {
static const T value = v;
typedef T value_type;
typedef integral_constant type;
};
- integral_constant 模板同时包含了整数的类型和数值,而通过这个类型的 value 成员我们又可以重新取回这个数值。
- 有了这个模板的帮忙,我们就可以进行一些更通用的计算了。
template <int result, int n>
struct SumLoop {
static const bool cond_value =
n != 0;
static const int res_value =
result;
typedef integral_constant<
int, res_value>
res_type;
typedef SumLoop<result + n, n - 1>
next_type;
};
template <int n>
struct Sum {
typedef SumLoop<0, n> type;
};
然后使用 While<Sum<10>::type>::type::value 就可以得到 1 加到 10 的结果。
编译期类型推导
C++ 标准库在 <type_traits> 头文件里定义了很多工具类模板,用来提取某个类型(type)在某方面的特点(trait) refer: cppreference.com, “Standard library header ”。
typedef std::integral_constant<
bool, true> true_type;
typedef std::integral_constant<
bool, false> false_type;
template <typename T>
class SomeContainer {
public:
…
static void destroy(T* ptr)
{
_destroy(ptr,
is_trivially_destructible<
T>());
}
private:
static void _destroy(T* ptr,
true_type)
{}
static void _destroy(T* ptr,
false_type)
{
ptr->~T();
}
};
- 类似上面,很多容器类里会有一个 destroy 函数,通过指针来析构某个对象。为了确保最大程度的优化,常用的一个技巧就是用 is_trivially_destructible 模板来判断类是否是可平凡析构的——也就是说,不调用析构函数,不会造成任何资源泄漏问题。
- 模板返回的结果还是一个类,要么是 true_type,要么是 false_type。如果要得到布尔值的话,当然使用
is_trivially_destructible<T>::value就可以,但此处不需要。我们需要的是,使用 () 调用该类型的构造函数,让编译器根据数值类型来选择合适的重载。这样,在优化编译的情况下,编译器可以把不需要的析构操作彻底全部删除。
另外一些模板,可以用来做一些类型的转换。以一个常见的模板 remove_const 为例(用来去除类型里的 const 修饰):
template <class T>
struct remove_const {
typedef T type;
};
template <class T>
struct remove_const<const T> {
typedef T type;
};
- 利用模板的特化,针对 const 类型去掉相应的修饰。
- 例如,
remove_const<const string&>::type等价于string&。
通用的 fmap 函数模板
从概念本源来看,map 和 reduce 都来自函数式编程。
template <
template <typename, typename>
class OutContainer = vector,
typename F, class R>
auto fmap(F&& f, R&& inputs)
{
typedef decay_t<decltype(
f(*inputs.begin()))>
result_type;
OutContainer<
result_type,
allocator<result_type>>
result;
for (auto&& item : inputs) {
result.push_back(f(item));
}
return result;
}
- 用 decltype 来获得用 f 来调用 inputs 元素的类型
- 用 decay_t 来把获得的类型变成一个普通的值类型
- 缺省使用 vector 作为返回值的容器,但可以通过模板参数改为其他容器
- 使用基于范围的 for 循环来遍历 inputs,对其类型不作其他要求
- 存放结果的容器需要支持 push_back 成员函数
下面的代码可以验证其功能:
vector<int> v{1, 2, 3, 4, 5};
int add_1(int x)
{
return x + 1;
}
// 在 fmap 执行之后,在 result 里得到一个新容器,其内容是 2, 3, 4, 5, 6
auto result = fmap(add_1, v);
完整代码:使用 C++17、GCC 7编译
#include <iostream>
#include <vector>
#include <type_traits>
using namespace std;
template< class T >
using decay_t = typename decay<T>::type;
template < template <typename, typename> class OutContainer = vector,
typename F, class R>
auto fmap(F&& f, R&& inputs)
{
typedef decay_t<decltype( f(*inputs.begin()))> result_type;
OutContainer< result_type, allocator<result_type>> result;
for (auto&& item : inputs) {
result.push_back(f(item));
}
return result;
}
int add_1(int x)
{
return x + 1;
}
int main()
{
vector<int> v{1, 2, 3, 4, 5};
auto result = fmap(add_1, v);
for (auto &&v : result) {
cout << v << endl;
}
}
总结:模板元编程,其本质是把计算过程用编译期的类型推导和类型匹配表达出来。
SFINAE:不是错误的替换失败是怎么回事?
替换失败非错(Substituion Failure is Not An Error),英文简称为 SFINAE。
函数模板的重载决议
当一个函数名称和某个函数模板名称匹配时,重载决议过程大致如下:
- 根据名称找出所有适用的函数和函数模板
- 对于适用的函数模板,要根据实际情况对模板形参进行替换;替换过程中如果发生错误,这个模板会被丢弃
- 在上面两步生成的可行函数集合中,编译器会寻找一个最佳匹配,产生对该函数的调用
- 如果没有找到最佳匹配,或者找到多个匹配程度相当的函数,则编译器需要报错
例子:
#include <stdio.h>
struct Test {
typedef int foo;
};
template <typename T>
void f(typename T::foo)
{
puts("1");
}
template <typename T>
void f(T)
{
puts("2");
}
int main()
{
f<Test>(10);
f<int>(10);
}
输出为:
1
2
首先看 f<Test>(10) 的情况:
- 有两个模板符合名字 f
- 替换结果为 f(Test::foo) 和 f(Test)
- 使用参数 10 去匹配,只有前者参数可以匹配,因而第一个模板被选择
再看一下 f<int>(10) 的情况:
- 还是两个模板符合名字 f
- 替换结果为 f(int::foo) 和 f(int);显然前者不是个合法的类型,被抛弃
- 使用参数 10 去匹配 f(int),没有问题,那就使用这个模板实例了
总结:体现的是 SFINAE 设计的最初用法:如果模板实例化中发生了失败,没有理由编译就此出错终止,因为还是可能有其他可用的函数重载的。 这儿的失败仅指函数模板的原型声明,即参数和返回值。函数体内的失败不考虑在内。如果重载决议选择了某个函数模板,而函数体在实例化的过程中出错,那仍然会得到一个编译错误。
编译期成员检测
根据某个实例化的成功或失败来在编译期检测类的特性。
下面这个模板,就可以检测一个类是否有一个名叫 reserve、参数类型为 size_t 的成员函数:
template <typename T>
struct has_reserve {
struct good { char dummy; };
struct bad { char dummy[2]; };
template <class U,
void (U::*)(size_t)>
struct SFINAE {};
template <class U>
static good
reserve(SFINAE<U, &U::reserve>*);
template <class U>
static bad reserve(...);
static const bool value =
sizeof(reserve<T>(nullptr))
== sizeof(good);
};
- 首先定义了两个结构 good 和 bad;它们的内容不重要,我们只关心它们的大小必须不一样。
- 然后定义了一个 SFINAE 模板,内容也同样不重要,但模板的第二个参数需要是第一个参数的成员函数指针,并且参数类型是 size_t,返回值是 void。
- 随后,定义了一个要求 SFINAE* 类型的 reserve 成员函数模板,返回值是 good;再定义了一个对参数类型无要求的 reserve 成员函数模板,返回值是 bad。
- 最后,我们定义常整型布尔值 value,结果是 true 还是 false,取决于 nullptr 能不能和 SFINAE* 匹配成功,而这又取决于模板参数 T 有没有返回类型是 void、接受一个参数并且类型为 size_t 的成员函数 reserve。
SFINAE 模板技巧
C++11 开始,标准库里有了一个叫 enable_if 的模板(定义在 <type_traits> 里)(refer: cppreference.com, “std::enable_if”),可以用它来选择性地启用某个函数的重载。
假设有一个函数,用来往一个容器尾部追加元素。我们希望原型是这个样子的:
template <typename C, typename T>
void append(C& container, T* ptr,
size_t size);
显然,container 有没有 reserve 成员函数,是对性能有影响的——如果有的话,我们通常应该预留好内存空间,以免产生不必要的对象移动甚至拷贝操作。利用 enable_if 和上面的 has_reserve 模板,我们就可以这么写:
// 有 reserve 的 append 版本
template <typename C, typename T>
enable_if_t<has_reserve<C>::value,
void>
append(C& container, T* ptr,
size_t size)
{
container.reserve(
container.size() + size);
for (size_t i = 0; i < size;
++i) {
container.push_back(ptr[i]);
}
}
// 没有 reserve 的 append 版本
template <typename C, typename T>
enable_if_t<!has_reserve<C>::value,
void>
append(C& container, T* ptr,
size_t size)
{
for (size_t i = 0; i < size;
++i) {
container.push_back(ptr[i]);
}
}
我们可以用 enable_if_t 来取到结果的类型。
enable_if_t<has_reserve<C>::value, void> 的意思可以理解成:如果类型 C 有 reserve 成员的话,那我们启用下面的成员函数,它的返回类型为 void。
decltype 返回值
如果只需要在某个操作有效的情况下启用某个函数,而不需要考虑相反的情况的话。
template <typename C, typename T>
auto append(C& container, T* ptr,
size_t size)
-> decltype(
declval<C&>().reserve(1U),
void())
{
container.reserve(container.size() + size);
for (size_t i = 0; i < size;
++i) {
container.push_back(ptr[i]);
}
}
上面使用到了 declval (refer: cppreference.com, “std::declval”)
- 这个模板用来声明一个某个类型的参数,但这个参数只是用来参加模板的匹配,不允许实际使用。使用这个模板,我们可以在某类型没有默认构造函数的情况下,假想出一个该类的对象来进行类型推导。
declval<C&>().reserve(1U)用来测试 C& 类型的对象是不是可以拿 1U 作为参数来调用 reserve 成员函数。此外,我们需要记得,C++ 里的逗号表达式的意思是按顺序逐个估值,并返回最后一项。所以,上面这个函数的返回值类型是 void。- 这个方式和
enable_if不同,很难表示否定的条件。如果要提供一个专门给没有 reserve 成员函数的 C 类型的 append 重载,这种方式就不太方便了。因而,这种方式的主要用途是避免错误的重载。
void_t
void_t 是 C++17 新引入的一个模板。它的定义简单得令人吃惊:
template <typename...>
using void_t = void;
这个类型模板会把任意类型映射到 void。它的特殊性在于,在这个看似无聊的过程中,编译器会检查那个“任意类型”的有效性。
constexpr:一个常态的世界
存在两类 constexpr 对象:
- 一个 constexpr 变量是一个编译时完全确定的常数。
- 一个 constexpr 函数至少对于某一组实参可以在编译期间产生一个编译期常数。
#include <array>
constexpr int sqr(int n)
{
return n * n;
}
int main()
{
constexpr int n = sqr(3);
std::array<int, n> a;
int b[n];
}
以阶乘函数为例:
#include <cstdio>
#include <stdexcept>
constexpr int factorial(int n)
{
if (n < 0) {
throw std::invalid_argument(
"Arg must be non-negative");
}
if (n == 0) {
return 1;
} else {
return n * factorial(n - 1);
}
}
int main()
{
//constexpr int n = factorial(10); // ok
constexpr int n = factorial(-1); // compile error
printf("%d\n", n);
}
/*
$ g++ -o constexpr constexpr.cpp
constexpr.cpp: In function ‘int main()’:
constexpr.cpp:21:29: in constexpr expansion of ‘factorial(-1)’
constexpr.cpp:8:31: error: expression ‘<throw-expression>’ is not a constant expression
"Arg must be non-negative");
^
*/
验证确实得到了一个编译期常量。如果看产生的汇编代码的话,一样可以直接看到常量 3628800。
注意:这里有一个问题:在这个 constexpr 函数里,是不能写 static_assert(n >= 0) 的。一个 constexpr 函数仍然可以作为普通函数使用——显然,传入一个普通 int 是不能使用静态断言的。
如果没有检查判断,编译展开时会报错:
$ g++ -o constexpr constexpr.cpp
constexpr.cpp: In function ‘int main()’:
constexpr.cpp:23:29: in constexpr expansion of ‘factorial(-1)’
constexpr.cpp:16:23: in constexpr expansion of ‘factorial((n + -1))’
constexpr.cpp:16:23: in constexpr expansion of ‘factorial((n + -1))’
...
constexpr.cpp:16:23: in constexpr expansion of ‘factorial((n + -1))’
constexpr.cpp:23:32: error: constexpr evaluation depth exceeds maximum of 512 (use -fconstexpr-depth= to increase the maximum)
constexpr int n = factorial(-1);
^
constexpr 和 const
初学 constexpr 时,一个很可能有的困惑是,它跟 const 用法上的区别到底是什么?产生这种困惑是正常的,毕竟 const 是个重载了很多不同含义的关键字。const 的原本和基础的含义,自然是表示它修饰的内容不会变化,如:
const int n = 1:
n = 2; // 出错!
注意: const 在类型声明的不同位置会产生不同的结果。对于常见的 const char* 这样的类型声明,意义和 char const* 相同,是指向常字符的指针,指针指向的内容不可更改;但和 char * const 不同,那代表指向字符的常指针,指针本身不可更改。本质上,const 用来表示一个运行时常量。
在 C++ 里,const 后面渐渐带上了现在的 constexpr 用法,也代表编译期常数。现在在有了 constexpr 之后——我们应该使用 constexpr 在这些用法中替换 const 了。从编译器的角度,为了向后兼容性,const 和 constexpr 在很多情况下还是等价的。但有时候,它们也有些细微的区别,其中之一为是否内联的问题。
constexpr 变量仍是 const。
一个 constexpr 变量仍然是 const 常类型。需要注意的是,就像 const char* 类型是指向常量的指针、自身不是 const 常量一样,下面这个表达式里的 const 也是不能缺少的:
constexpr int a = 42;
constexpr const int& b = a;
constexpr 表示 b 是一个编译期常量,const 表示这个引用是常量引用。去掉这个 const 的话,编译器就会认为你是试图将一个普通引用绑定到一个常数上,报一个类似下面的错误信息:error: binding reference of type ‘int&’ to ‘const int’ discards qualifiers
函数对象和lambda:进入函数式编程
C++98 的函数对象
函数对象(function object) 自 C++98 开始就已经被标准化了。从概念上来说,函数对象是一个可以被当作函数来用的对象。它有时也会被叫做 functor,但这个术语在范畴论里有着完全不同的含义,还是不用为妙——否则玩函数式编程的人可能会朝着你大皱眉头的。
下面定义了一个简单的加 n 的函数对象类:
struct adder {
adder(int n) : n_(n) {}
int operator()(int x) const
{
return x + n_;
}
private:
int n_;
};
adder add_2(2);
int res = add_2(5); // 2 + 5 = 7
函数的指针和引用
除非用一个引用模板参数来捕捉函数类型,传递给一个函数的函数实参会退化成为一个函数指针。不管是函数指针还是函数引用,都可以当成函数对象来用。
#include <cstdio>
template <typename T>
auto test1(T fn)
{
return fn(2);
}
template <typename T>
auto test2(T& fn)
{
return fn(2);
}
template <typename T>
auto test3(T* fn)
{
return (*fn)(2);
}
int add_2(int x)
{
return x + 2;
}
int main()
{
printf("%d\n", test1(add_2));
}
/*
test1(T fn)
add_2(int x)
4
*/
当用 add_2 去调用这三个函数模板时,fn 的类型将分别被推导为 int (*)(int)、int (&)(int) 和 int (*)(int)。不管得到的是指针还是引用,都可以直接拿它当普通的函数用。当然,在函数指针的情况下,直接写 *value 也可以。因而上面三个函数拿 add_2 作为实参调用的结果都是 4。
Lambda 表达式
auto add_2 = [](int x) {
return x + 2;
};
- Lambda 表达式以一对中括号开始
- 跟函数定义一样,有参数列表
- 跟正常的函数定义一样,会有一个函数体,里面会有 return 语句
- Lambda 表达式一般不需要说明返回值(相当于 auto);有特殊情况需要说明时,则应使用箭头语法的方式
- 每个 lambda 表达式都有一个全局唯一的类型,要精确捕捉 lambda 表达式到一个变量中,只能通过 auto 声明的方式
定义一个通用的 adder:
auto adder = [](int n) {
return [n](int x) {
return x + n;
};
};
auto seven = adder(2)(5);
不过,最常见的情况是,写匿名函数就是希望不需要起名字。以前面的把所有容器元素值加 2 的操作为例,使用匿名函数可以得到更简洁可读的代码:
transform(v.begin(), v.end(),
v.begin(),
[](int x) {
return x + 2;
});
一个 lambda 表达式除了没有名字之外,还有一个特点是你可以立即进行求值。一个 lambda 表达式默认就是 constexpr 函数。
// 9
[](int x) { return x * x; }(3)
另外一种用途是解决多重初始化路径的问题。假设有这样的代码:
Obj obj;
switch (init_mode) {
case init_mode1:
obj = Obj(…);
break;
case init_mode2;
obj = Obj(…);
break;
…
}
这样的代码,实际上是调用了默认构造函数、带参数的构造函数和(移动)赋值函数:既可能有性能损失,也对 Obj 提出了有默认构造函数的额外要求。对于这样的代码,有一种重构意见是把这样的代码分离成独立的函数。不过,有时候更直截了当的做法是用一个 lambda 表达式来进行改造,既可以提升性能(不需要默认函数或拷贝 / 移动),又让初始化部分显得更清晰:
auto obj = [init_mode]() {
switch (init_mode) {
case init_mode1:
return Obj(…);
break;
case init_mode2:
return Obj(…);
break;
…
}
}();
变量捕获
lambda 表达式中变量捕获的细节:
变量捕获的开头是可选的默认捕获符 = 或 &,表示会自动按值或按引用捕获用到的本地变量,然后后面可以跟(逗号分隔):
- 本地变量名标明对其按值捕获
&加本地变量名标明对其按引用捕获this标明按引用捕获外围对象(针对 lambda 表达式定义出现在一个非静态类成员内的情况)*this标明按值捕获外围对象(针对 lambda 表达式定义出现在一个非静态类成员内的情况;C++17 新增语法)变量名 = 表达式标明按值捕获表达式的结果(可理解为 auto 变量名 = 表达式)&变量名 = 表达式标明按引用捕获表达式的结果(可理解为 auto& 变量名 = 表达式)
** 经验:**
- 从工程的角度,大部分情况不推荐使用默认捕获符。更一般化的一条工程原则是:显式的代码比隐式的代码更容易维护。当然,在这条原则上走多远是需要权衡的,你也不愿意写出非常啰嗦的代码吧?否则的话,大家就全部去写 C 了。
- 一般而言,按值捕获是比较安全的做法。按引用捕获时则需要更小心些,必须能够确保被捕获的变量和 lambda 表达式的生命期至少一样长,并在有下面需求之一时才使用:
- 需要在 lambda 表达式中修改这个变量并让外部观察到
- 需要看到这个变量在外部被修改的结果
- 这个变量的复制代价比较高
例子:
按引用捕获:按引用捕获 v1 和 v2,因为需要修改它们的内容。
vector<int> v1;
vector<int> v2;
…
auto push_data = [&](int n) {
// 或使用 [&v1, &v2] 捕捉
v1.push_back(n);
v2.push_back(n)
};
push_data(2);
push_data(3);
按值捕获外围对象:
#include <chrono>
#include <iostream>
#include <sstream>
#include <thread>
using namespace std;
int get_count()
{
static int count = 0;
return ++count;
}
class task {
public:
task(int data) : data_(data) {}
auto lazy_launch()
{
return
[*this, count = get_count()]()
mutable {
ostringstream oss;
oss << "Done work " << data_
<< " (No. " << count
<< ") in thread "
<< this_thread::get_id()
<< '\n';
msg_ = oss.str();
calculate();
};
}
void calculate()
{
this_thread::sleep_for(100ms);
cout << msg_;
}
private:
int data_;
string msg_;
};
int main()
{
auto t = task{37};
thread t1{t.lazy_launch()};
thread t2{t.lazy_launch()};
t1.join();
t2.join();
}
/*
g++ -o lambda lambda.cpp -std=c++1z -lpthread
$ ./lambda
Done work 37 (No. 2) in thread 140555858978560
Done work 37 (No. 1) in thread 140555867371264
*/
如果将 *this(按值) 改成 this(按引用),则结果为:
Done work 37 (No. 1) in thread 139984678594304
Done work 37 (No. 1) in thread 139984678594304
泛型 lambda 表达式
在 lambda 表达式的定义过程中是没法写 template 关键字的。
template <typename T1,
typename T2>
auto sum(T1 x, T2 y)
{
return x + y;
}
跟上面的函数等价的 lambda 表达式是:
auto sum = [](auto x, auto y)
{
return x + y;
}
你可能要问,这么写有什么用呢?问得好。简单来说,答案是可组合性。上面这个 sum,就跟标准库里的 plus 模板一样,是可以传递给其他接受函数对象的函数的,而 + 本身则不行。
#include <array> // std::array
#include <iostream> // std::cout/endl
#include <numeric> // std::accumulate
using namespace std;
int main()
{
array a{1, 2, 3, 4, 5};
auto s = accumulate(
a.begin(), a.end(), 0,
[](auto x, auto y) {
return x + y;
});
cout << s << endl;
}
function 模板
每一个 lambda 表达式都是一个单独的类型,所以只能使用 auto 或模板参数来接收结果。在很多情况下,我们需要使用一个更方便的通用类型来接收,这时我们就可以使用 function 模板。function 模板的参数就是函数的类型,一个函数对象放到 function 里之后,外界可以观察到的就只剩下它的参数、返回值类型和执行效果了。注意 function 对象的创建还是比较耗资源的,所以请你只在用 auto 等方法解决不了问题的时候使用这个模板。
map<string, function<int(int, int)>>
op_dict{
{"+",
[](int x, int y) {
return x + y;
}},
{"-",
[](int x, int y) {
return x - y;
}},
{"*",
[](int x, int y) {
return x * y;
}},
{"/",
[](int x, int y) {
return x / y;
}},
};
op_dict.at("+")(1, 6);
函数式编程:一种越来越流行的编程范式
函数式编程的特点
函数式编程期望函数的行为像数学上的函数,而非一个计算机上的子程序。这样的函数一般被称为纯函数(pure function),要点在于:
- 会影响函数结果的只是函数的参数,没有对环境的依赖
- 返回的结果就是函数执行的唯一后果,不产生对环境的其他影响
高阶函数
既然函数(对象)可以被传递、使用和返回,自然就有函数会接受函数作为参数或者把函数作为返回值,这样的函数就被称为高阶函数。
C++ 里以 algorithm(算法)名义提供的很多函数都是高阶函数。
-
Map在 C++ 中的直接映射是transform(在 头文件中提供)。它所做的事情也是数学上的映射,把一个范围里的对象转换成相同数量的另外一些对象。这个函数的基本实现非常简单,但这是一种强大的抽象,在很多场合都用得上。 -
Reduce在 C++ 中的直接映射是accumulate(在 头文件中提供)。它的功能是在指定的范围里,使用给定的初值和函数对象,从左到右对数值进行归并。在不提供函数对象作为第四个参数时,功能上相当于默认提供了加法函数对象,这时相当于做累加;提供了其他函数对象时,那当然就是使用该函数对象进行归并了。
命令式编程和说明式编程
传统上 C++ 属于命令式编程。命令式编程里,代码会描述程序的具体执行步骤。好处是代码显得比较直截了当;缺点就是容易让人只见树木、不见森林,只能看到代码啰嗦地怎么做(how),而不是做什么(what),更不用说为什么(why)了。
说明式编程则相反。以数据库查询语言 SQL 为例,SQL 描述的是类似于下面的操作:你想从什么地方(from)选择(select)满足什么条件(where)的什么数据,并可选指定排序(order by)或分组(group by)条件。你不需要告诉数据库引擎具体该如何去执行这个操作。事实上,在选择查询策略上,大部分数据库用户都不及数据库引擎“聪明”;正如大部分开发者在写出优化汇编代码上也不及编译器聪明一样。
说明式编程(优雅)和命令式编程(高效)可以结合起来产生既优雅又高效的代码。
不可变性和并发
在多核的时代里,函数式编程比以前更受青睐,一个重要的原因是函数式编程对并行并发天然友好。影响多核性能的一个重要因素是数据的竞争条件——由于共享内存数据需要加锁带来的延迟。函数式编程强调不可变性(immutability)、无副作用,天然就适合并发。更妙的是,如果你使用高层抽象的话,有时可以轻轻松松“免费”得到性能提升。
启用 C++17 的并行执行策略([refer: cppreference.com, “Standard library header
int count_lines(const char** begin,
const char** end)
{
vector<int> count(end - begin);
transform(execution::par,
begin, end,
count.begin(),
count_file);
return reduce(
execution::par,
count.begin(), count.end());
}
两个高阶函数的调用中都加入了 execution::par,来启动自动并行计算。
refer: Functional Programming in C++. Manning, 2019
应用可变模板和tuple的编译期技巧
如何使用可变模板和tuple来完成一些常见的功能,尤其是编译期计算。
可变模板
可变模板(refer: cppreference.com, “Parameter pack”)是 C++11 引入的一项新功能,使我们可以在模板参数里表达不定个数和类型的参数。从实际的角度,它有两个明显的用途:
- 用于在通用工具模板中转发参数到另外一个函数
- 用于在递归的模板中表达通用的情况(另外会有至少一个模板特化来表达边界情况)
转发用法
以标准库里的 make_unique 为例,它的定义差不多是下面这个样子:
template <typename T,
typename... Args>
inline unique_ptr<T>
make_unique(Args&&... args)
{
return unique_ptr<T>(
new T(forward<Args>(args)...));
}
这样,它就可以把传递给自己的全部参数转发到模板参数类的构造函数上去。注意,在这种情况下,我们通常会使用 std::forward,确保参数转发时仍然保持正确的左值或右值引用类型。
解释一下上面三处出现的 ...:
typename... Args声明了一系列的类型——class...或typename...表示后面的标识符代表了一系列的类型。Args&&... args声明了一系列的形参 args,其类型是Args&&。forward<Args>(args)...会在编译时实际逐项展开Args和args,参数有多少项,展开后就是多少项。
例如,如果需要在堆上传递一个 vector,假设希望初始构造的大小为 100,每个元素都是 1:
make_unique<vector<int>>(100, 1)
模板实例化之后,会得到相当于下面的代码:
template <>
inline unique_ptr<vector<int>>
make_unique(int&& arg1, int&& arg2)
{
return unique_ptr<vector<int>>(
new vector<int>(
forward<int>(arg1),
forward<int>(arg2)));
}
递归用法
也可以用可变模板来实现编译期递归。
template <typename T>
constexpr auto sum(T x)
{
return x;
}
template <typename T1, typename T2,
typename... Targ>
constexpr auto sum(T1 x, T2 y,
Targ... args)
{
return sum(x + y, args...);
}
在上面的定义里,如果 sum 得到的参数只有一个,会走到上面那个重载。如果有两个或更多参数,编译器就会选择下面那个重载,执行一次加法,随后你的参数数量就少了一个,因而递归总会终止到上面那个重载,结束计算。
要使用上面这个模板,就可以写出像下面这样的函数调用:
auto result = sum(1, 2, 3.5, x);
模板会这样依次展开:
sum(1 + 2, 3.5, x)
sum(3 + 3.5, x)
sum(6.5 + x)
6.5 + x
注意我们都不必使用相同的数据类型:只要这些数据之间可以应用 +,它们的类型无关紧要。
tuple
在 C++ 里,要通用地用一个变量来表达多个值,那就得看多元组 tuple 模板了。tuple 算是 C++98 里的 pair 类型的一般化,可以表达任意多个固定数量、固定类型的值的组合。
#include <algorithm>
#include <iostream>
#include <string>
#include <tuple>
#include <vector>
using namespace std;
// 整数、字符串、字符串的三元组
using num_tuple =
tuple<int, string, string>;
ostream&
operator<<(ostream& os,
const num_tuple& value)
{
os << get<0>(value) << ','
<< get<1>(value) << ','
<< get<2>(value);
return os;
}
int main()
{
// 阿拉伯数字、英文、法文
vector<num_tuple> vn{
{1, "one", "un"},
{2, "two", "deux"},
{3, "three", "trois"},
{4, "four", "quatre"}};
// 修改第 0 项的法文
get<2>(vn[0]) = "une";
// 按法文进行排序
sort(vn.begin(), vn.end(),
[](auto&& x, auto&& y) {
return get<2>(x) <
get<2>(y);
});
// 输出内容
for (auto&& value : vn) {
cout << value << endl;
}
// 输出多元组项数
constexpr auto size = \
tuple_size_v<num_tuple>;
cout << "Tuple size is " << size << endl;
}
可以看到:
- tuple 的成员数量由尖括号里写的类型数量决定。
- 可以使用
get函数对 tuple 的内容进行读和写。 - 可以用
tuple_size_v(在编译期)取得多元组里面的项数。
数值预算
需求:希望快速地计算一串二进制数中 1 比特的数量。举个例子,如果有十进制的 31 和 254,转换成二进制是 00011111 和 11111110,那我们应该得到 5 + 7 = 12。
利用 constexpr 函数,可以通过编译期完成计算:
constexpr int
count_bits(unsigned char value)
{
if (value == 0) {
return 0;
} else {
return (value & 1) +
count_bits(value >> 1);
}
}
定义一个模板,它的参数是一个序列,在初始化时这个模板会对参数里的每一项计算比特数,并放到数组成员里。
template <size_t... V>
struct bit_count_t {
unsigned char
count[sizeof...(V)] = {
static_cast<unsigned char>(
count_bits(V))...};
};
- 用
sizeof...(V)可以获得参数的个数。
thread和future:领略异步中的未来
为什么要使用并发编程?
伴随摩尔定律免费午餐的结束,计算要求则从单线程变成了多线程甚至异构——不仅要使用 CPU,还得使用 GPU。
我们讲 C++ 里的并发,主要讲的就是多线程。它对开发人员的挑战是全方位的。从纯逻辑的角度,并发的思维模式就比单线程更为困难。在其之上,还得加上:
- 编译器和处理器的重排问题
- 原子操作和数据竞争
- 互斥锁和死锁问题
- 无锁算法
- 条件变量
- 信号量
- etc.
对于并发的基本挑战,Herb Sutter 在他的 Effective Concurrency 专栏给出了一个较为全面的概述。
基于 thread 的多线程开发
一个使用thread 线程类的例子:
#include <chrono>
#include <iostream>
#include <mutex>
#include <thread>
using namespace std;
mutex output_lock;
void func(const char* name)
{
this_thread::sleep_for(100ms);
lock_guard<mutex> guard{output_lock};
cout << "I am thread " << name << '\n';
}
int main()
{
thread t1{func, "A"};
thread t2{func, "B"};
t1.join();
t2.join();
}
这是某次执行的结果:
I am thread B
I am thread A
注意:一个平台细节,在 Linux 上编译线程相关的代码都需要加上
-pthread命令行参数。Windows 和 macOS 上则不需要。
- thread 的构造函数的第一个参数是函数(对象),后面跟的是这个函数所需的参数。
- thread 要求在析构之前要么
join(阻塞直到线程退出),要么detach(放弃对线程的管理),否则程序会异常退出。 sleep_for是this_thread名空间下的一个自由函数,表示当前线程休眠指定的时间。- 如果没有 output_lock 的同步,输出通常会交错到一起。
thread 不能在析构时自动 join 有点不那么自然,这可以算是一个缺陷吧。在 C++20 的 jthread 到来之前,我们只能自己小小封装一下了。
class scoped_thread {
public:
template <typename... Arg>
scoped_thread(Arg&&... arg)
: thread_(
std::forward<Arg>(arg)...)
{}
scoped_thread(
scoped_thread&& other)
: thread_(
std::move(other.thread_))
{}
scoped_thread(
const scoped_thread&) = delete;
~scoped_thread()
{
if (thread_.joinable()) {
thread_.join();
}
}
private:
thread thread_;
};
int main()
{
scoped_thread t1{func, "A"};
scoped_thread t2{func, "B"};
}
- 使用了可变模板和完美转发来构造 thread 对象。
- thread 不能拷贝,但可以移动。
- 只有 joinable(已经 join 的、已经 detach 的或者空的线程对象都不满足 joinable)的 thread 才可以对其调用 join 成员函数,否则会引发异常。
通过上面的例子,可以发现并发程序的特点:
- 执行顺序不可预期,或者说不具有决定性。
- 如果没有互斥量的帮助,我们连完整地输出一整行信息都成问题。
mutex(互斥量)
互斥量的基本语义是,一个互斥量只能被一个线程锁定,用来保护某个代码块在同一时间只能被一个线程执行。在前面那个多线程的例子里,我们就需要限制同时只有一个线程在使用 cout,否则输出就会错乱。
目前的 C++ 标准中,事实上提供了不止一个互斥量类。我们先看最简单、也最常用的 mutex 类。mutex 只可默认构造,不可拷贝(或移动),不可赋值,主要提供的方法是:
lock:锁定,锁已经被其他线程获得时则阻塞执行try_lock:尝试锁定,获得锁返回 true,在锁被其他线程获得时返回 falseunlock:解除锁定(只允许在已获得锁时调用)
注意:
如果一个线程已经锁定了某个互斥量,再次锁定会发生什么?对于 mutex,回答是危险的未定义行为。
头文件
中也定义了锁的 **RAII 包装类**,如 `lock_guard`。为了避免手动加锁、解锁的麻烦,以及在有异常或出错返回时发生漏解锁,一般应当使用 `lock_guard`,而不是手工调用互斥量的 `lock` 和 `unlock` 方法。
执行任务,返回数据
如果我们要在某个线程执行一些后台任务,然后取回结果,该怎么做呢?
比较传统的做法是使用信号量或者条件变量。
#include <chrono>
#include <condition_variable>
#include <functional>
#include <iostream>
#include <mutex>
#include <thread>
#include <utility>
using namespace std;
class scoped_thread {
… // 定义同上,略
};
void work(condition_variable& cv,
int& result)
{
// 假装我们计算了很久
this_thread::sleep_for(2s);
result = 42;
cv.notify_one();
}
int main()
{
condition_variable cv;
mutex cv_mut;
int result;
scoped_thread th{work, ref(cv),
ref(result)};
// 干一些其他事
cout << "I am waiting now\n";
unique_lock lock{cv_mut};// 单一锁
cv.wait(lock);
cout << "Answer: " << result << '\n';
}
用 ref 模板来告诉 thread 的构造函数,我们需要传递条件变量和结果变量的引用,因为 thread 默认复制或移动所有的参数作为线程函数的参数。
future
更简单的方法是,把上面的代码直接翻译成使用 async(它会返回一个 future):
#include <chrono>
#include <future>
#include <iostream>
#include <thread>
using namespace std;
int work()
{
// 假装我们计算了很久
this_thread::sleep_for(2s);
return 42;
}
int main()
{
auto fut = async(launch::async, work);
// 干一些其他事
cout << "I am waiting now\n";
cout << "Answer: " << fut.get() << '\n';
}
- work 函数现在不需要考虑条件变量之类的实现细节了,专心干好自己的计算活、老老实实返回结果就可以了。
- 调用 async 可以获得一个未来量,
launch::async是运行策略,告诉函数模板 async 应当在新线程里异步调用目标函数。在一些老版本的 GCC 里,不指定运行策略,默认不会起新线程。 - async 函数模板可以根据参数来推导出返回类型,在例子里,返回类型是
future<int>。 - 在未来量上调用
get成员函数可以获得其结果。这个结果可以是返回值,也可以是异常,即,如果 work 抛出了异常,那 main 里在执行fut.get()时也会得到同样的异常,需要有相应的异常处理代码程序才能正常工作。
注意:
- 一个 future 上只能调用一次 get 函数,第二次调用为未定义行为,通常导致程序崩溃。
- 这样一来,自然一个 future 是不能直接在多个线程里用的。
promise
上面用 async 函数生成了未来量,但这不是唯一的方式。另外有一种常用的方式是 promise,我称之为“承诺量”。用 promise 该怎么写:
#include <chrono>
#include <future>
#include <iostream>
#include <thread>
using namespace std;
class scoped_thread {
… // 定义同上,略
};
void work(promise<int> prom)
{
// 假装我们计算了很久
this_thread::sleep_for(2s);
prom.set_value(42);
}
int main()
{
promise<int> prom;
auto fut = prom.get_future();
scoped_thread th{work,
move(prom)};
// 干一些其他事
cout << "I am waiting now\n";
cout << "Answer: " << fut.get() << '\n';
}
promise 和 future 在这里成对出现,可以看作是一个一次性管道:有人需要兑现承诺,往 promise 里放东西(set_value);有人就像收期货一样,到时间去 future(写到这里想到,期货英文不就是 future 么,是不是该翻译成期货量呢?)里拿(get)就行了。我们把 prom 移动给新线程,这样老线程就完全不需要管理它的生命周期了。
promise 和 future 还有个有趣的用法是使用 void 类型模板参数。这种情况下,两个线程之间不是传递参数,而是进行同步:当一个线程在一个 future 上等待时(使用 get() 或 wait()),另外一个线程可以通过调用 promise 上的 set_value() 让其结束等待、继续往下执行。
内存模型和atomic:理解并发的复杂性
C++ 里的内存模型和原子量。
C++98 的执行顺序问题
C++98 的年代里,开发者们已经了解了线程的概念,但 C++ 的标准里则完全没有提到线程。从实践上,估计大家觉得不提线程,C++ 也一样能实现多线程的应用程序吧。不过,很多聪明人都忽略了,下面的事实可能会产生不符合直觉预期的结果:
- 为了优化的必要,编译器是可以调整代码的执行顺序的。唯一的要求是,程序的“可观测”外部行为是一致的。
- 处理器也会对代码的执行顺序进行调整(所谓的 CPU 乱序执行)。在单处理器的情况下,这种乱序无法被程序观察到;但在多处理器的情况下,在另外一个处理器上运行的另一个线程就可能会察觉到这种不同顺序的后果了。
对于上面的后一点,大部分开发者并没有意识到。原因有好几个方面:
- 多处理器的系统在那时还不常见
- 主流的 x86 体系架构仍保持着较严格的内存访问顺序
- 只有在数据竞争(data race)激烈的情况下才能看到“意外”的后果
例子,假设有两个全局变量:
int x = 0;
int y = 0;
然后在一个线程里执行:
x = 1;
y = 2;
在另一个线程里执行:
if (y == 2) {
x = 3;
y = 4;
}
想一下,x、y 的数值有几种可能?
你如果认为有两种可能,1、2 和 3、4 的话,那说明你是按典型程序员的思维模式看问题的——没有像编译器和处理器一样处理问题。事实上,1、4 也是一种结果的可能。有两个基本的原因可以造成这一后果:
- 编译器没有义务一定按代码里给出的顺序产生代码。事实上,跟据上下文调整代码的执行顺序,使其最有利于处理器的架构,是优化中很重要的一步。就单个线程而言,先执行 x = 1 还是先执行 y = 2 完全是件无关紧要的事:它们没有外部“可观察”的区别。
- 在多处理器架构中,各个处理器可能存在缓存不一致性问题。取决于具体的处理器类型、缓存策略和变量地址,对变量 y 的写入有可能先反映到主内存中去。之所以这个问题似乎并不常见,是因为常见的 x86 和 x86-64 处理器是在顺序执行方面做得最保守的——大部分其他处理器,如 ARM、DEC Alpha、PA-RISC、IBM Power、IBM z/ 架构和 Intel Itanium 在内存序问题上都比较“松散”。x86 使用的内存模型基本提供了顺序一致性(sequential consistency);相对的,ARM 使用的内存模型就只是松散一致性(relaxed consistency)。
虽说 Intel 架构处理器的顺序一致性比较好,但在多处理器(包括多核)的情况下仍然能够出现写读序列变成读写序列的情况,产生意料之外的后果。
Jeff Preshing, “Memory reordering caught in the act” 中提供了完整的例子,包括示例代码。对于缓存不一致性问题的一般中文介绍,可以查看参考王欢明, 《多处理器编程:从缓存一致性到内存模型》。
双重检查锁定
在多线程可能对同一个单件进行初始化的情况下,有一个双重检查锁定的技巧,可基本示意如下:
// 头文件
class singleton {
public:
static singleton* instance();
…
private:
static singleton* inst_ptr_;
};
// 实现文件
singleton* singleton::inst_ptr_ = nullptr;
singleton* singleton::instance()
{
if (inst_ptr_ == nullptr) {
lock_guard lock; // 加锁
if (inst_ptr_ == nullptr) {
inst_ptr_ = new singleton();
}
}
return inst_ptr_;
}
这个代码的目的是消除大部分执行路径上的加锁开销。原本的意图是:如果 inst_ptr_ 没有被初始化,执行才会进入加锁的路径,防止单件被构造多次;如果 inst_ptr_ 已经被初始化,那它就会被直接返回,不会产生额外的开销。虽然看上去很美,但它一样有着上面提到的问题。Scott Meyers 和 Andrei Alexandrecu 详尽地分析了这个用法(refer: Scott Meyers and Andrei Alexandrescu, “C++ and the perils of double-checked locking”),然后得出结论:即使花上再大的力气,这个用法仍然有着非常多的难以填补的漏洞。本质上还是上面说的,优化编译器会努力击败你试图想防止优化的努力,而多处理器会以令人意外的方式让代码走到错误的执行路径上去。
volatile
在某些编译器里,使用 volatile 关键字可以达到内存同步的效果。但我们必须记住,这不是 volatile 的设计意图,也不能通用地达到内存同步的效果。volatile 的语义只是防止编译器“优化”掉对内存的读写而已。它的合适用法,目前主要是用来读写映射到内存地址上的 I/O 操作。
注意:由于 volatile 不能在多处理器的环境下确保多个线程能看到同样顺序的数据变化,在今天的通用应用程序中,不应该再看到 volatile 的出现。
C++11 的内存模型
为了从根本上消除这些漏洞,C++11 里引入了适合多线程的内存模型。(refer: cppreference.com, “Memory model”)
跟我们开发密切相关的是:现在我们有了原子对象(atomic)和使用原子对象的获得(acquire)、释放(release)语义,可以真正精确地控制内存访问的顺序性,保证我们需要的内存序。
内存屏障和获得、释放语义
拿刚才的那个例子来说,如果我们希望结果只能是 1、2 或 3、4,即满足程序员心中的完全存储序(total store ordering),我们需要在 x = 1 和 y = 2 两句语句之间加入内存屏障,禁止这两句语句交换顺序。
- 获得是一个对内存的读操作,当前线程的任何后面的读写操作都不允许重排到这个操作的前面去。(即,读操作,先完成)
- 释放是一个对内存的写操作,当前线程的任何前面的读写操作都不允许重排到这个操作的后面去。(即,写操作,最后完成)
实现方法:
在线程 1 需要使用释放语义:
atomic<int> y;
x = 1;
y.store(2, memory_order_release); // 释放,写操作
在线程 2 对 y 的读取应当使用获得语义,但存储只需要松散内存序即可:
if (y.load(memory_order_acquire) == 2) { // 获得,读操作
x = 3;
y.store(4, memory_order_relaxed);
}
用下图示意一下,每一边的代码都不允许重排越过黄色区域,且如果 y 上的释放早于 y 上的获取的话,释放前对内存的修改都在另一个线程的获取操作后可见:
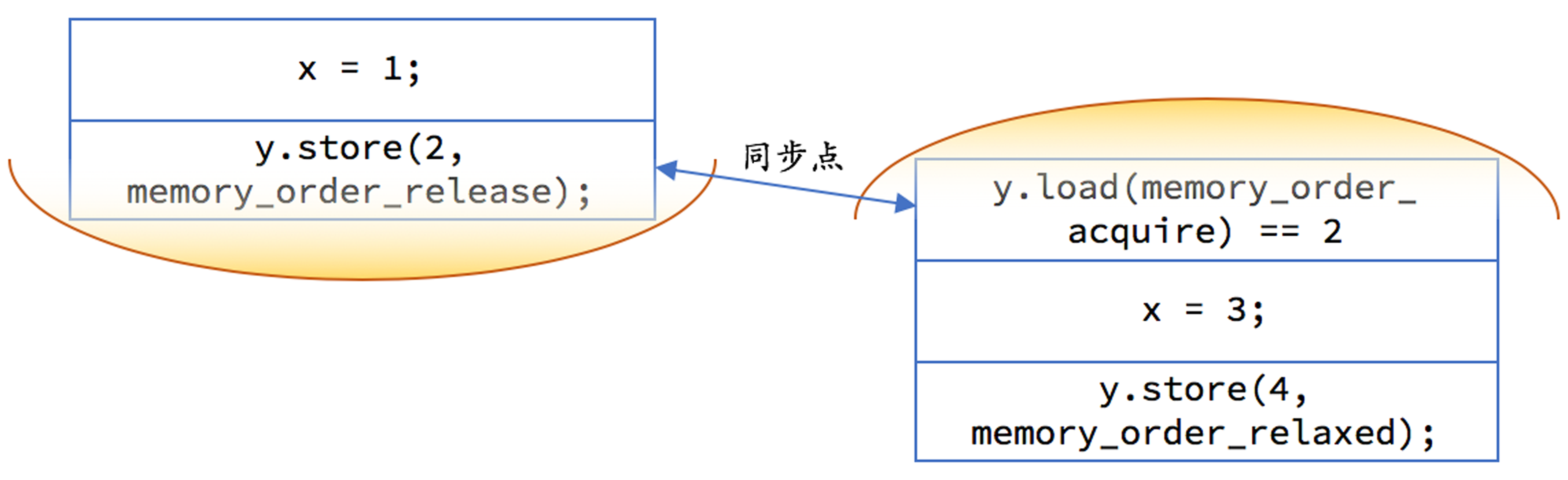
事实上,在把 y 改成 atomic 之后,两个线程的代码一行不改,执行结果都会是符合我们的期望的。因为 atomic 变量的写操作缺省就是释放语义,读操作缺省就是获得语义。即:
y = 2相当于y.store(2, memory_order_release)y == 2相当于y.load(memory_order_acquire) == 2
注意:
- 缺省行为可能是对性能不利的:我们并不需要在任何情况下都保证操作的顺序性。
- acquire 和 release 通常都是配对出现的,目的是保证如果对同一个原子对象的 release 发生在 acquire 之前的话,release 之前发生的内存修改能够被 acquire 之后的内存读取全部看到。
atomic
C++11 在 头文件中引入了 atomic 模板,对原子对象进行了封装。
我们可以将其应用到任何类型上去。当然对于不同的类型效果还是有所不同的:
- 对于整型量和指针等简单类型,通常结果是无锁的原子对象;
- 而对于另外一些类型,比如 64 位机器上大小不是 1、2、4、8(有些平台 / 编译器也支持对更大的数据进行无锁原子操作)的类型,编译器会自动为这些原子对象的操作加上锁。
- 编译器提供了一个原子对象的成员函数
is_lock_free,可以检查这个原子对象上的操作是否是无锁的。
原子操作有三类:
- 读:在读取的过程中,读取位置的内容不会发生任何变动。
- 写:在写入的过程中,其他执行线程不会看到部分写入的结果。
- 读‐修改‐写:读取内存、修改数值、然后写回内存,整个操作的过程中间不会有其他写入操作插入,其他执行线程不会看到部分写入的结果。
<atomic>头文件中还定义了内存序,分别是:
- memory_order_relaxed:松散内存序,只用来保证对原子对象的操作是原子的
- memory_order_consume:目前不鼓励使用
- memory_order_acquire:获得操作,在读取某原子对象时,当前线程的任何后面的读写操作都不允许重排到这个操作的前面去,并且其他线程在对同一个原子对象释放之前的所有内存写入都在当前线程可见
- memory_order_release:释放操作,在写入某原子对象时,当前线程的任何前面的读写操作都不允许重排到这个操作的后面去,并且当前线程的所有内存写入都在对同一个原子对象进行获取的其他线程可见
- memory_order_acq_rel:获得释放操作,一个读‐修改‐写操作同时具有获得语义和释放语义,即它前后的任何读写操作都不允许重排,并且其他线程在对同一个原子对象释放之前的所有内存写入都在当前线程可见,当前线程的所有内存写入都在对同一个原子对象进行获取的其他线程可见
- memory_order_seq_cst:顺序一致性语义,对于读操作相当于获取,对于写操作相当于释放,对于读‐修改‐写操作相当于获得释放,是所有原子操作的默认内存序
如何实现多线程计数的例子:
由于我们并不需要 ++ 之后计数值影响其他行为,在 add_count 中执行简单的 ++、使用顺序一致性语义略有浪费。更好的做法是将其实现成:
#include <atomic>
std::atomic_long count_;// atomic_long 是 atomic<long> 的类型别名
void add_count() noexcept
{
count_.fetch_add(
1, std::memory_order_relaxed);
}
注意:is_lock_free 的可能问题
macOS 上在使用 Clang 时似乎不支持对需要加锁的对象使用
is_lock_free成员函数,此时链接会出错。而 GCC 在这种情况下,需要确保系统上装了 libatomic。以 CentOS 7 下的 GCC 7 为例,我们可以使用下面的语句来安装:sudo yum install devtoolset-7-libatomic-devel
然后,用下面的语句编译可以通过:
g++ -pthread test.cpp -latomic
Windows 下使用 MSVC 则没有问题。
mutex
- 互斥量的加锁操作(lock)具有获得语义
- 互斥量的解锁操作(unlock)具有释放语义
实现一个真正安全的双重检查锁定:
// 头文件
class singleton {
public:
static singleton* instance();
…
private:
static mutex lock_;
static atomic<singleton*>
inst_ptr_;
};
// 实现文件
mutex singleton::lock_;
atomic<singleton*>
singleton::inst_ptr_;
singleton* singleton::instance()
{
singleton* ptr = inst_ptr_.load(
memory_order_acquire);
if (ptr == nullptr) {
lock_guard<mutex> guard{lock_};
ptr = inst_ptr_.load(
memory_order_relaxed);
if (ptr == nullptr) {
ptr = new singleton();
inst_ptr_.store(
ptr, memory_order_release);
}
}
return inst_ptr_;
}
注意:对互斥量和原子量的区别。
用原子量的地方,粗想一下,你用锁都可以。但如果锁导致阻塞的话,性能比起原子量那是会有好几个数量级的差异了。锁即使不导致阻塞,性能也会比原子量低——锁本身的实现就会用到原子量,是个复杂的复合操作。
反过来不成立,用互斥量的地方不能都改用原子量。原子量本身没有阻塞机制,没有保护代码段的功能。
并发队列的接口(无锁队列)
标准库里 queue 有下面这样的接口:
template <typename T>
class queue {
public:
…
T& front();
const T& front() const;
void pop();
…
}
会不会在我们正在访问 front() 的时候,这个元素就被 pop 掉了?
事实上,上面这样的接口是不可能做到并发安全的。并发安全的接口大概长下面这个样子:
template <typename T>
class queue {
public:
…
void wait_and_pop(T& dest)
bool try_pop(T& dest);
…
}
换句话说,要准备好位置去接收;然后如果接收成功了,才安安静静地在自己的线程里处理已经被弹出队列的对象。接收方式还得分两种,阻塞式的和非阻塞式的……
并发队列的实现,经常是用原子量来达到无锁和高性能的。
- 单生产者、单消费者的并发队列,用原子量和获得、释放语义就能简单实现。
- 对于多生产者或多消费者的情况,那实现就比较复杂了,一般会使用 compare_exchange_strong 或 compare_exchange_weak。
参考:
- nvwa::fc_queue 给出了一个单生产者、单消费者的无锁并发定长环形队列,代码长度是几百行的量级。
- moodycamel::ConcurrentQueue 给出了一个多生产者、多消费者的无锁通用并发队列,代码长度是几千行的量级。
- 陈皓给出了一篇很棒的对无锁队列的中文描述,推荐阅读。
讨论
感觉这里的无锁操作就像分布式系统里面谈到的乐观锁,普通的互斥量就像悲观锁。只是CPU级的乐观锁由CPU提供指令集级别的支持。
内存重排会引起内存数据的不一致性,尤其是在多CPU的系统里。这又让我想起分布式系统里讲的CAP理论。
多线程就像分布式系统里的多个节点,每个CPU对自己缓存的写操作在CPU同步之前就造成了主内存中数据的值在每个CPU缓存中的不一致,相当于分布式系统中的分区。
我大概看了参考文献一眼,因为一级缓存相对主内存速度有数量级上的优势,所以各个缓存选择的策略相当于分布式系统中的可用性,即保留了AP(分区容错性与可用性,放弃数据的一致性),然后在涉及到缓存数据一致性问题上,相当于采取了最终一致性。
其实我觉得不论是什么系统,时间颗足够小的话,都会存在数据的不一致,只是CPU的速度太快了,所以看起来都是最终一致性。在保证可用性的时候,整个程序的某个变量或内存中的值看起来就是进行了重排。
分布式系统中将多个节点解耦的方式是用异步、用队列。生产者把变化事件写到队列里就返回,然后由消费者取出来异步的实施这些操作,达到数据的最终一致性。
看资料里,多CPU同步时,也有在CPU之间引入队列。当需要“释放前对内存的修改都在另一个线程的获取操作后可见”时,我的理解就是用了所谓的“内存屏障”强制让消费者消费完队列里的”CPU级的事物”。所以才会在达到严格内存序的过程中降低了程序的性能。
也许,这个和操作系统在调度线程时,过多的上下文切换会导致系统性能降低有关系。
操作系统的上下文切换和内存序的关系我略有不同意见。内存屏障的开销我查下来大概是 100、200 个时钟周期,也就是约 50 纳秒左右吧。而 Linux 的上下文切换开销约在 1 微秒多,也就是两者之前的性能差异超过 20 倍。因此,内存屏障不太可能是上下文切换性能开销的主因。上下文切换实际需要做的事情非常多,那应该才是主要原因。
处理数据类型变化和错误:optional、variant、expected和Herbception
optional
在面向对象(引用语义)的语言里,我们有时候会使用空值 null 表示没有找到需要的对象。也有人推荐使用一个特殊的空对象,来避免空值带来的一些问题。可不管是空值,还是空对象,对于一个返回普通对象(值语义)的 C++ 函数都是不适用的——空值和空对象只能用在返回引用 / 指针的场合,一般情况下需要堆内存分配,在 C++ 里会引致额外的开销。
C++17 引入的 optional 模板 可以(部分)解决这个问题。语义上来说,optional 代表一个“也许有效”“可选”的对象。语法上来说,一个 optional 对象有点像一个指针,但它所管理的对象是直接放在 optional 里的,没有额外的内存分配。
variant
optional 是一个非常简单而又好用的模板,很多情况下,使用它就足够解决问题了。在某种意义上,可以把它看作是允许有两种数值的对象:要么是你想放进去的对象,要么是 nullopt(再次提醒,联想 nullptr)。
如果希望除了想放进去的对象,还可以是 nullopt 之外的对象怎么办呢(比如,某种出错的状态)?又比如,如果希望有三种或更多不同的类型呢?这种情况下,variant 可能就是一个合适的解决方案。
在没有 variant 类型之前,你要达到类似的目的,恐怕会使用一种叫做带标签的联合(tagged union)的数据结构。比如,下面就是一个可能的数据结构定义:
struct FloatIntChar {
enum {
Float,
Int,
Char
} type;
union {
float float_value;
int int_value;
char char_value;
};
};
这个数据结构的最大问题,就是它实际上有很多复杂情况需要特殊处理。对于上面例子里的 POD 类型,这么写就可以了。如果把其中一个类型换成非 POD 类型,就会有复杂问题出现(编译器会很合理地看到在 union 里使用 string 类型会带来构造和析构上的问题,所以会拒绝工作)。
所以,目前的主流建议是,应该避免使用“裸” union 了。替换为 variant。
variant<string, int, char> obj{"Hello world"};
cout << get<string>(obj) << endl;
- 可以注意到我上面构造时使用的是
const char*,但构造函数仍然能够正确地选择string类型,这是因为标准要求实现在没有一个完全匹配的类型的情况下,会选择成员类型中能够以传入的类型来构造的那个类型进行初始化(有且只有一个时)。string类存在形式为string(const char*)的构造函数(不精确地说),所以上面的构造能够正确进行。 - 跟
tuple相似,variant上可以使用get函数模板,其模板参数可以是代表序号的数字,也可以是类型。如果编译时可以确定序号或类型不合法,在编译时就会出错。如果序号或类型合法,但运行时发现 variant 里存储的并不是该类对象,则会得到一个异常bad_variant_access。 variant上还有一个重要的成员函数是index,通过它能获得当前的数值的序号。就上面的例子而言,obj.index() 即为 1。正常情况下,variant里总有一个有效的数值(缺省为第一个类型的默认构造结果),但如果emplace等修改操作中发生了异常,variant里也可能没有任何有效数值,此时index()将会得到variant_npos。
总结:从基本概念来讲,variant 就是一个安全的 union。
expected
expected 不是 C++ 标准里的类型。但概念上这三者有相关性。
optional 可以作为一种代替异常的方式:在原本该抛异常的地方,我们可以改而返回一个空的 optional 对象。当然,此时只知道没有返回一个合法的对象,而不知道为什么没有返回合法对象了。可以考虑改用一个 variant,但此时需要给错误类型一个独特的类型才行,因为这是 variant 模板的要求。比如:
enum class error_code {
success,
operation_failure,
object_not_found,
…
};
variant<Obj, error_code>
get_object(…);
这当然是一种可行的错误处理方式:我们可以判断返回值的 index(),来决定是否发生了错误。但这种方式不那么直截了当,也要求实现对允许的错误类型作出规定。
Andrei Alexandrescu 在 2012 年首先提出的 Expected 模板,提供了另外一种错误处理方式。他的方法的要点在于,把完整的异常信息放在返回值,并在必要的时候,可以“重放”出来,或者手工检查是不是某种类型的异常。
他的概念并没有被广泛推广,最主要的原因可能是性能。异常最被人诟病的地方是性能,而他的方式对性能完全没有帮助。不过,后面的类似模板都汲取了他的部分思想,至少会用一种显式的方式来明确说明当前是异常情况还是正常情况。在目前的 expected 的标准提案(refer: Vicente J. Botet Escribá and JF Bastien, “Utility class to represent expected object”)里,用法有点是 optional 和 variant 的某种混合:模板的声明形式像 variant,使用正常返回值像 optional。
例子:Simon Brand, expected展示了expected的用法。
思考:错误处理是一个非常复杂的问题,在 C++ 诞生之后这么多年仍然没有该如何处理的定论。如何对易用性和性能进行取舍,一直是一个有矛盾的老大难问题。
refer:
数字计算
Boost.Multiprecision
众所周知,C 和 C++(甚至推而广之到大部分的常用编程语言)里的数值类型是有精度限制的。比如,INT_MIN,最小的整数。很多情况下,使用目前这些类型是够用的(最高一般是 64 位整数和 80 位浮点数)。但也有很多情况,这些标准的类型远远不能满足需要。这时你就需要一个高精度的数值类型了。
#include <iomanip>
#include <iostream>
#include <boost/multiprecision/cpp_int.hpp>
using namespace std;
int main()
{
using namespace boost::
multiprecision::literals;
using boost::multiprecision::
cpp_int;
cpp_int a =
0x123456789abcdef0_cppi;
cpp_int b = 16;
cpp_int c{"0400"};
cpp_int result = a * b / c;
cout << hex << result << endl;
cout << dec << result << endl;
}
可以看到,cpp_int 可以通过自定义字面量(后缀 _cppi;只能十六进制)来初始化,可以通过一个普通整数来初始化,也可以通过字符串来初始化(并可以使用 0x 和 0 前缀来选择十六进制和八进制)。拿它可以正常地进行加减乘除操作,也可以通过 IO 流来输入输出。
Boost.Multiprecision 使用了表达式模板和 C++11 的移动来避免不必要的拷贝。
Boost:你需要的“瑞士军刀”
Boost 作为 C++ 世界里标准库之外最知名的开放源码程序库。
Boost 的网站把 Boost 描述成为经过同行评审的、可移植的 C++ 源码库(peer-reviewed portable C++ source libraries)。换句话说,它跟很多个人开源库不一样的地方在于,它的代码是经过评审的。事实上,Boost 项目的背后有很多 C++ 专家,比如发起人之一的 Dave Abarahams 是 C++ 标准委员会的成员,也是《C++ 模板元编程》一书的作者。这也就使得 Boost 有了很不一样的特殊地位:它既是 C++ 标准库的灵感来源之一,也是 C++ 标准库的试验田。
下面这些 C++ 标准库就源自 Boost:
智能指针/thread/regex/random/array/bind/tuple/optional/variant/any/string_view/filesystem/等等
当然,将来还会有新的库从 Boost 进入 C++ 标准,如网络库的标准化就是基于 Boost.Asio 进行的。因此,即使相关的功能没有被标准化,我们也可能可以从 Boost 里看到某个功能可能会被标准化的样子——当然,最终标准化之后的样子还是经常有所变化的。
我们也可以在编译器落后于标准、不能提供标准库的某个功能时使用 Boost 里的替代品。比如,老版本的 macOS 上苹果的编译器不支持 optional 和 variant。除了我描述的不正规做法,改用 Boost 也是方法之一。
Boost.TypeIndex
TypeIndex 是一个很轻量级的库,它不需要链接,解决的也是使用模板时的一个常见问题,如何精确地知道一个表达式或变量的类型。
#include <iostream>
#include <typeinfo>
#include <utility>
#include <vector>
#include <boost/type_index.hpp>
using namespace std;
using boost::typeindex::type_id;
using boost::typeindex::type_id_with_cvr;
int main()
{
vector<int> v;
auto it = v.cbegin();
cout << "*** Using typeid\n";
cout << typeid(const int).name()
<< endl;
cout << typeid(v).name() << endl;
cout << typeid(it).name() << endl;
cout << "*** Using type_id\n";
cout << type_id<const int>() << endl;
cout << type_id<decltype(v)>()
<< endl;
cout << type_id<decltype(it)>()
<< endl;
cout << "*** Using "
"type_id_with_cvr\n";
cout
<< type_id_with_cvr<const int>()
<< endl;
cout << type_id_with_cvr<decltype(
(v))>()
<< endl;
cout << type_id_with_cvr<decltype(
move((v)))>()
<< endl;
cout << type_id_with_cvr<decltype(
(it))>()
<< endl;
}
typeid是标准 C++ 的关键字,可以应用到变量或类型上,返回一个std::type_info。我们可以用它的name成员函数把结果转换成一个字符串,但标准不保证这个字符串的可读性和唯一性。type_id是 Boost 提供的函数模板,必须提供类型作为模板参数——所以对于表达式和变量我们需要使用decltype。结果可以直接输出到 IO 流上。type_id_with_cvr和type_id相似,但它获得的结果会包含 const/volatile 状态及引用类型。
另外一个例子:
#include <iostream>
#include <typeinfo>
#include <boost/type_index.hpp>
using namespace std;
using boost::typeindex::type_id;
class shape {
public:
virtual ~shape() {}
};
class circle : public shape {};
#define CHECK_TYPEID(object, type) \
cout << "typeid(" #object << ")" \
<< (typeid(object) == \
typeid(type) \
? " is " \
: " is NOT ") \
<< #type << endl
#define CHECK_TYPE_ID(object, \
type) \
cout << "type_id(" #object \
<< ")" \
<< (type_id<decltype( \
object)>() == \
type_id<type>() \
? " is " \
: " is NOT ") \
<< #type << endl
int main()
{
shape* ptr = new circle();
CHECK_TYPEID(*ptr, shape);
CHECK_TYPEID(*ptr, circle);
CHECK_TYPE_ID(*ptr, shape);
CHECK_TYPE_ID(*ptr, circle);
delete ptr;
}
输出:
typeid(*ptr) is NOT shape
typeid(*ptr) is circle
type_id(*ptr) is shape
type_id(*ptr) is NOT circle
Boost.Core
Core 里面提供了一些通用的工具,这些工具常常被 Boost 的其他库用到,而我们也可以使用,不需要链接任何库。
addressof,在即使用户定义了operator&时也能获得对象的地址enable_ifis_same,判断两个类型是否相同,C++11 开始在 中定义ref,和标准库的相同
boost::core::demangle
boost::core::demangle 能够用来把 typeid 返回的内部名称“反粉碎”(demangle)成可读的形式。
#include <iostream>
#include <typeinfo>
#include <utility>
#include <vector>
#include <boost/core/demangle.hpp>
using namespace std;
using boost::core::demangle;
int main()
{
vector<int> v;
auto it = v.cbegin();
cout << "*** Using typeid\n";
cout << typeid(const int).name()
<< endl;
cout << typeid(v).name() << endl;
cout << typeid(it).name() << endl;
cout << "*** Demangled\n";
cout << demangle(typeid(const int)
.name())
<< endl;
cout << demangle(typeid(v).name())
<< endl;
cout << demangle(
typeid(it).name())
<< endl;
}
boost::noncopyable
boost::noncopyable 提供了一种非常简单也很直白的把类声明成不可拷贝的方式。
#include <boost/core/noncopyable.hpp>
class shape_wrapper
: private boost::noncopyable {
…
};
你当然也可以自己把拷贝构造和拷贝赋值函数声明成 = delete,不过,上面的写法是不是可读性更佳?
boost::swap
在通用的代码如何对一个不知道类型的对象执行交换操作?
{
using std::swap;
swap(lhs, rhs);
}
即,我们需要(在某个小作用域里)引入 std::swap,然后让编译器在“看得到” std::swap 的情况下去编译 swap 指令。根据 ADL,如果在被交换的对象所属类型的名空间下有 swap 函数,那个函数会被优先使用,否则,编译器会选择通用的 std::swap。似乎有点小啰嗦。使用 Boost 的话,你可以一行搞定:
#include <boost/core/swap.hpp>
boost::swap(lhs, rhs);
Boost.Conversion
Conversion 同样是一个不需要链接的轻量级的库。它解决了标准 C++ 里的另一个问题,标准类型之间的转换不够方便。在 C++11 之前,这个问题尤为严重。在 C++11 里,标准引入了一系列的函数,已经可以满足常用类型之间的转换。但使用 Boost.Conversion 里的 lexical_cast 更不需要去查阅方法名称或动脑子去努力记忆。
#include <iostream>
#include <stdexcept>
#include <string>
#include <boost/lexical_cast.hpp>
using namespace std;
using boost::bad_lexical_cast;
using boost::lexical_cast;
int main()
{
// 整数到字符串的转换
int d = 42;
auto d_str =
lexical_cast<string>(d);
cout << d_str << endl;
// 字符串到浮点数的转换
auto f =
lexical_cast<float>(d_str) /
4.0;
cout << f << endl;
// 测试 lexical_cast 的转换异常
try {
int t = lexical_cast<int>("x");
cout << t << endl;
}
catch (bad_lexical_cast& e) {
cout << e.what() << endl;
}
// 测试标准库 stoi 的转换异常
try {
int t = std::stoi("x");
cout << t << endl;
}
catch (invalid_argument& e) {
cout << e.what() << endl;
}
}
输出:
42
10.5
bad lexical cast: source type value could not be interpreted as target
stoi
GCC 里 stoi 的异常输出有点太言简意赅了。而 lexical_cast 的异常输出在不同的平台上有很好的一致性。
Boost.ScopeExit
RAII 是推荐的 C++ 里管理资源的方式。不过,作为 C++ 程序员,跟 C 函数打交道也很正常。每次都写个新的 RAII 封装也有点浪费。Boost 里提供了一个简单的封装,你可以从下面的示例代码里看到它是如何使用的:
#include <stdio.h>
#include <boost/scope_exit.hpp>
void test()
{
FILE* fp = fopen("test.cpp", "r");
if (fp == NULL) {
perror("Cannot open file");
}
BOOST_SCOPE_EXIT(&fp) {
if (fp) {
fclose(fp);
puts("File is closed");
}
} BOOST_SCOPE_EXIT_END
puts("Faking an exception");
throw 42;
}
int main()
{
try {
test();
}
catch (int) {
puts("Exception received");
}
}
唯一需要说明的可能就是 BOOST_SCOPE_EXIT 里的那个 & 符号了——把它理解成 lambda 表达式的按引用捕获就对了(虽然 BOOST_SCOPE_EXIT 可以支持 C++98 的代码)。如果不需要捕获任何变量,BOOST_SCOPE_EXIT 的参数必须填为 void。
Faking an exception
File is closed
Exception received
注意:使用这个库也只需要头文件。注意实现类似的功能在 C++11 里相当容易,但由于 ScopeExit 可以支持 C++98 的代码,因而它的实现还是相当复杂的。
Boost.Program_options
传统上 C 代码里处理命令行参数会使用 getopt。比如在下面的代码中:
https://github.com/adah1972/breaktext/blob/master/breaktext.c
这种方式有不少缺陷:
- 一个选项通常要在三个地方重复:说明文本里,getopt 的参数里,以及对 getopt 的返回结果进行处理时。
- 对选项的附加参数需要手工写代码处理,因而常常不够严格(C 的类型转换不够方便,尤其是检查错误)。
Program_options 正是解决这个问题的。这个代码有点老了,不过还挺实用;懒得去找特别的处理库时,至少这个伸手可用。使用这个库需要链接 boost_program_options 库。
#include <iostream>
#include <string>
#include <stdlib.h>
#include <boost/program_options.hpp>
namespace po = boost::program_options;
using std::cout;
using std::endl;
using std::string;
string locale;
string lang;
int width = 72;
bool keep_indent = false;
bool verbose = false;
int main(int argc, char* argv[])
{
po::options_description desc(
"Usage: breaktext [OPTION]... "
"<Input File> [Output File]\n"
"\n"
"Available options");
desc.add_options()
("locale,L",
po::value<string>(&locale),
"Locale of the console (system locale by default)")
("lang,l",
po::value<string>(&lang),
"Language of input (asssume no language by default)")
("width,w",
po::value<int>(&width),
"Width of output text (72 by default)")
("help,h", "Show this help message and exit")
(",i",
po::bool_switch(&keep_indent),
"Keep space indentation")
(",v",
po::bool_switch(&verbose),
"Be verbose");
po::variables_map vm;
try {
po::store(
po::parse_command_line(
argc, argv, desc),
vm);
}
catch (po::error& e) {
cout << e.what() << endl;
exit(1);
}
vm.notify();
if (vm.count("help")) {
cout << desc << "\n";
exit(1);
}
}
options_description是基本的选项描述对象的类型,构造时我们给出对选项的基本描述。options_description对象的add_options成员函数会返回一个函数对象,然后我们直接用括号就可以添加一系列的选项。- 每个选项初始化时可以有两个或三个参数,第一项是选项的形式,使用长短选项用逗号隔开的字符串(可以只提供一种),最后一项是选项的文字描述,中间如果还有一项的话,就是选项的值描述。
- 选项的值描述可以用
value,bool_switch等方法,参数是输出变量的指针。 variables_map,变量映射表,用来存储对命令行的扫描结果;它继承了标准的std::map。notify成员函数用来把变量映射表的内容实际传送到选项值描述里提供的那些变量里去。count成员函数继承自 std::map,只能得到 0 或 1 的结果。
这样,程序就能处理上面的那些选项了。如果运行时在命令行加上 -h 或 --help 选项,程序就会输出跟原来类似的帮助输出——额外的好处是选项的描述信息较长时还能自动帮你折行,不需要手工排版了。
单元测试
两个单元测试库:C++里如何进行单元测试?
Boost.Test
#define BOOST_TEST_MAIN
#include <boost/test/unit_test.hpp>
#include <stdexcept>
void test(int n)
{
if (n == 42) {
return;
}
throw std::runtime_error(
"Not the answer");
}
// 一个测试用例
BOOST_AUTO_TEST_CASE(my_test)
{
// 多个测试语句
BOOST_TEST_MESSAGE("Testing");
BOOST_TEST(1 + 1 == 2);
BOOST_CHECK_THROW(test(41), std::runtime_error);
BOOST_CHECK_NO_THROW(test(42));
int expected = 5;
BOOST_TEST(2 + 2 == expected);
BOOST_CHECK(2 + 2 == expected);
}
BOOST_AUTO_TEST_CASE(null_test)
{
}
- 在包含单元测试的头文件之前定义了
BOOST_TEST_MAIN。如果编译时用到了多个源文件,只有一个应该定义该宏。多文件测试的时候,一般会考虑把这个定义这个宏加包含放在一个单独的文件里(只有两行)。 - 用
BOOST_AUTO_TEST_CASE来定义一个测试用例。一个测试用例里应当有多个测试语句(如BOOST_CHECK)。 - 用
BOOST_CHECK或BOOST_TEST来检查一个应当成立的布尔表达式。区别:BOOST_TEST能利用模板技巧来输出表达式的具体内容。但在某些情况下,BOOST_TEST试图输出表达式的内容会导致编译出错,这时可以改用更简单的BOOST_CHECK。 - 用
BOOST_CHECK_THROW来检查一个应当抛出异常的语句。 - 用
BOOST_CHECK_NO_THROW来检查一个不应当抛出异常的语句。 - 不管是
BOOST_CHECK还是BOOST_TEST,在测试失败时,执行仍然会继续。在某些情况下,一个测试失败后继续执行后面的测试已经没有意义,这时,就可以考虑使用BOOST_REQUIRE或BOOST_TEST_REQUIRE——表达式一旦失败,整个测试用例会停止执行(但其他测试用例仍会正常执行)。 - 缺省情况下单元测试的输出只包含错误信息和结果摘要,但输出的详细程度是可以通过命令行选项来进行控制的。如在运行测试程序时加上命令行参数
--log_level=all(或-l all)- 在进入、退出测试模块和用例时的提示
- BOOST_TEST_MESSAGE 的输出
- 正常通过的测试的输出
- 用例里无测试断言的警告
- Boost.Test 产生的可执行代码支持很多命令行参数,可以用
--help命令行选项来查看。- build_info 可用来展示构建信息
- color_output 可用来打开或关闭输出中的色彩
- log_format 可用来指定日志输出的格式,包括纯文本、XML、JUnit 等
- log_level 可指定日志输出的级别,有 all、test_suite、error、fatal_error、nothing 等一共 11 个级别
- run_test 可选择只运行指定的测试用例
- show_progress 可在测试时显示进度,在测试数量较大时比较有用
编译方式:
- MSVC:
cl /DBOOST_TEST_DYN_LINK /EHsc /MD test.cpp - GCC:
g++ -DBOOST_TEST_DYN_LINK test.cpp -lboost_unit_test_framework - Clang:
clang++ -DBOOST_TEST_DYN_LINK test.cpp -lboost_unit_test_framework
例子:https://github.com/adah1972/nvwa/blob/master/test/boosttest_split.cpp
Catch2
要选择 Boost 之外的库,一定有一个比较强的理由。Catch2 有着它自己独有的优点:
- 只需要单个头文件即可使用,不需要安装和链接,简单方便
- 可选使用
BDD(Behavior-Driven Development)风格的分节形式 - 测试失败可选直接进入调试器(Windows 和 macOS 上)
#define CATCH_CONFIG_MAIN
#include "catch.hpp"
#include <stdexcept>
void test(int n)
{
if (n == 42) {
return;
}
throw std::runtime_error(
"Not the answer");
}
TEST_CASE("My first test", "[my]")
{
INFO("Testing");
CHECK(1 + 1 == 2);
CHECK_THROWS_AS(
test(41), std::runtime_error);
CHECK_NOTHROW(test(42));
int expected = 5;
CHECK(2 + 2 == expected);
}
TEST_CASE("A null test", "[null]")
{
}
什么是 BDD (Behavior-driven development) 风格的测试 ?
BDD 风格的测试一般采用这样的结构:
- Scenario:场景,我要做某某事
- Given:给定,已有的条件
- When:当,某个事件发生时
- Then:那样,就应该发生什么
假设测试一个容器,那代码就应该是这个样子的:
SCENARIO("Int container can be accessed and modified",
"[container]")
{
GIVEN("A container with initialized items")
{
IntContainer c{1, 2, 3, 4, 5};
REQUIRE(c.size() == 5);
WHEN("I access existing items")
{
THEN("The items can be retrieved intact")
{
CHECK(c[0] == 1);
CHECK(c[1] == 2);
CHECK(c[2] == 3);
CHECK(c[3] == 4);
CHECK(c[4] == 5);
}
}
WHEN("I modify items")
{
c[1] = -2;
c[3] = -4;
THEN("Only modified items are changed")
{
CHECK(c[0] == 1);
CHECK(c[1] == -2);
CHECK(c[2] == 3);
CHECK(c[3] == -4);
CHECK(c[4] == 5);
}
}
}
}
Catch2 是一个很现代、很好用的测试框架。它的宏更简单,一个 CHECK 可以替代 Boost.Test 中的 BOOST_TEST 和 BOOST_CHECK,也没有 BOOST_TEST 在某些情况下不能用、必须换用 BOOST_CHECK 的问题。对于一个新项目,使用 Catch2 应该是件更简单、更容易上手的事——尤其如果你在 Windows 上开发的话。
refer:
https://en.wikipedia.org/wiki/List_of_unit_testing_frameworks#C++
日志库
Easylogging++和spdlog:两个好用的日志库。
Easylogging++
Easylogging++ 一共只有两个文件,一个是头文件,一个是普通 C++ 源文件。事实上,它的一个较早版本只有一个文件。正如 Catch2 里一旦定义了 CATCH_CONFIG_MAIN 编译速度会大大减慢一样,把什么东西都放一起最终证明对编译速度还是相当不利的,因此,有人提交了一个补丁,把代码拆成了两个文件。使用 Easylogging++ 也只需要这两个文件——除此之外,就只有对标准和系统头文件的依赖了。
要使用 Easylogging++,推荐直接把这两个文件放到你的项目里。
Easylogging++ 有很多的配置项会影响编译结果,常用的可配置项:
- ELPP_UNICODE:启用 Unicode 支持,为在 Windows 上输出混合语言所必需
- ELPP_THREAD_SAFE:启用多线程支持
- ELPP_DISABLE_LOGS:全局禁用日志输出
- ELPP_DEFAULT_LOG_FILE:定义缺省日志文件名称
- ELPP_NO_DEFAULT_LOG_FILE:不使用缺省的日志输出文件
- ELPP_UTC_DATETIME:在日志里使用协调世界时而非本地时间
- ELPP_FEATURE_PERFORMANCE_TRACKING:开启性能跟踪功能
- ELPP_FEATURE_CRASH_LOG:启用 GCC 专有的崩溃日志功能
- ELPP_SYSLOG:允许使用系统日志(Unix 世界的 syslog)来记录日志
- ELPP_STL_LOGGING:允许在日志里输出常用的标准容器对象(std::vector 等)
- ELPP_QT_LOGGING:允许在日志里输出 Qt 的核心对象(QVector 等)
- ELPP_BOOST_LOGGING:允许在日志里输出某些 Boost 的容器(boost::container::vector 等)
例子:
#include "easylogging++.h"
INITIALIZE_EASYLOGGINGPP
int main()
{
LOG(INFO) << "My first info log";
}
g++ -std=c++17 test.cpp easylogging++.cc
运行生成的可执行程序,就可以看到结果输出到终端和 myeasylog.log 文件里,包含了日期、时间、级别、日志名称和日志信息,形如:
2020-01-25 20:47:50,990 INFO [default] My first info log
INITIALIZE_EASYLOGGINGPP 展开后(可以用编译器的 -E 参数查看宏展开后的结果)是定义了 Easylogging++ 使用到的全局对象,而 LOG(INFO) 则是 Info 级别的日志记录器,同时传递了文件名、行号、函数名等日志需要的信息。
改变输出文件名:
Easylogging++ 的缺省输出日志名为 myeasylog.log,这在大部分情况下都是不适用的。可以直接在命令行上使用宏定义来修改(当然,稍大点的项目就应该放在项目的编译配置文件里了,如 Makefile)。比如,要把输出文件名改成 test.log,只需要在命令行上加入下面的选项就可以:-DELPP_DEFAULT_LOG_FILE=test.log
使用配置文件设置日志选项:
Easylogging++ 库自己支持配置文件,推荐使用一个专门的配置文件,并让 Easylogging++ 自己来加载配置文件。
* GLOBAL:
FORMAT = "%datetime{\%Y-%M-%d %H:%m:%s.%g} %levshort %msg"
FILENAME = "test.log"
ENABLED = true
TO_FILE = true ## 输出到文件
TO_STANDARD_OUTPUT = true ## 输出到标准输出
SUBSECOND_PRECISION = 6 ## 秒后面保留 6 位
MAX_LOG_FILE_SIZE = 2097152 ## 最大日志文件大小设为 2MB
LOG_FLUSH_THRESHOLD = 10 ## 写 10 条日志刷新一次缓存
* DEBUG:
FORMAT = "%datetime{\%Y-%M-%d %H:%m:%s.%g} %levshort [%fbase:%line] %msg"
TO_FILE = true
TO_STANDARD_OUTPUT = false ## 调试日志不输出到标准输出
- 第一节是全局(global)配置,配置了适用于所有级别的日志选项
- 第二节是专门用于调试(debug)级别的配置(你当然也可以自己配置 fatal、error、warning 等其他级别)
假设这个配置文件的名字是 log.conf,在代码中可以这样使用:
#include "easylogging++.h"
INITIALIZE_EASYLOGGINGPP
int main()
{
el::Configurations conf{
"log.conf"};
el::Loggers::
reconfigureAllLoggers(conf);
LOG(DEBUG) << "A debug message";
LOG(INFO) << "An info message";
}
注意编译命令行上应当加上 -DELPP_NO_DEFAULT_LOG_FILE,否则 Easylogging++ 仍然会生成缺省的日志文件。
运行生成的可执行程序,会在终端上看到一条信息,但在日志文件里则可以看到两条信息。如下所示:
2020-01-26 12:54:58.986739 D [test.cpp:11] A debug message
2020-01-26 12:54:58.987444 I An info message
推荐在编译时定义宏 ELPP_DEBUG_ASSERT_FAILURE,这样能在找不到配置文件时直接终止程序,而不是继续往下执行、在终端上以缺省的方式输出日志了。
性能跟踪
Easylogging++ 可以用来在日志中记录程序执行的性能数据。这个功能还是很方便的。下面的代码展示了用于性能跟踪的三个宏的用法:
#include <chrono>
#include <thread>
#include "easylogging++.h"
INITIALIZE_EASYLOGGINGPP
void foo()
{
TIMED_FUNC(timer);
LOG(WARNING) << "A warning message";
}
void bar()
{
using namespace std::literals;
TIMED_SCOPE(timer1, "void bar()");
foo();
foo();
TIMED_BLOCK(timer2, "a block") {
foo();
std::this_thread::sleep_for(100us);
}
}
int main()
{
el::Configurations conf{
"log.conf"};
el::Loggers::
reconfigureAllLoggers(conf);
bar();
}
TIMED_FUNC接受一个参数,是用于性能跟踪的对象的名字。它能自动产生函数的名称。示例中的TIMED_FUNC和TIMED_SCOPE的作用是完全相同的。TIMED_SCOPE接受两个参数,分别是用于性能跟踪的对象的名字,以及用于记录的名字。如果你不喜欢TIMED_FUNC生成的函数名字,可以用TIMED_SCOPE来代替。TIMED_BLOCK用于对下面的代码块进行性能跟踪,参数形式和TIMED_SCOPE相同。
在编译含有上面三个宏的代码时,需要定义宏 ELPP_FEATURE_PERFORMANCE_TRACKING。你一般也应该定义 ELPP_PERFORMANCE_MICROSECONDS,来获取微秒级的精度。下面是定义了上面两个宏编译的程序的某次执行的结果:
2020-01-26 15:00:11.99736 W A warning message
2020-01-26 15:00:11.99748 I Executed [void foo()] in [110 us]
2020-01-26 15:00:11.99749 W A warning message
2020-01-26 15:00:11.99750 I Executed [void foo()] in [5 us]
2020-01-26 15:00:11.99750 W A warning message
2020-01-26 15:00:11.99751 I Executed [void foo()] in [4 us]
2020-01-26 15:00:11.99774 I Executed [a block] in [232 us]
2020-01-26 15:00:11.99776 I Executed [void bar()] in [398 us]
注意:
由于 Easylogging++ 本身有一定开销,且开销有一定的不确定性,这种方式只适合颗粒度要求比较粗的性能跟踪。
性能跟踪产生的日志级别固定为 Info。性能跟踪本身可以在配置文件里的 GLOBAL 节下用
PERFORMANCE_TRACKING = false来关闭。当然,关闭所有 Info 级别的输出也能达到关闭性能跟踪的效果。
记录崩溃日志
在 GCC 和 Clang 下,通过定义宏 ELPP_FEATURE_CRASH_LOG 可以启用崩溃日志。此时,当程序崩溃时,Easylogging++ 会自动在日志中记录程序的调用栈信息。通过记录下的信息,再利用 addr2line 这样的工具,就能知道是程序的哪一行引发了崩溃。
#include "easylogging++.h"
INITIALIZE_EASYLOGGINGPP
void boom()
{
char* ptr = nullptr;
*ptr = '\0';
}
int main()
{
el::Configurations conf{
"log.conf"};
el::Loggers::
reconfigureAllLoggers(conf);
boom();
}
注意:使用 macOS 的需要特别注意一下:由于缺省方式产生的可执行文件是位置独立的,系统每次加载程序会在不同的地址,导致无法通过地址定位到程序行。在编译命令行尾部加上 -Wl,-no_pie 可以解决这个问题。
spdlog
#include "spdlog/spdlog.h"
int main()
{
spdlog::info("My first info log");
}
从代码中已经注意到,spdlog 不是使用 IO 流风格的输出了。它采用跟 Python 里的 str.format 一样的方式,使用大括号——可选使用序号和格式化要求——来对参数进行格式化。
spdlog::warn(
"Message with arg {}", 42);
spdlog::error(
"{0:d}, {0:x}, {0:o}, {0:b}",
42);
输出:
[2020-01-26 17:20:08.355] [warning] Message with arg 42
[2020-01-26 17:20:08.355] [error] 42, 2a, 52, 101010
事实上,这就是 C++20 的 format 的风格了——spdlog 就是使用了一个 format 的库实现 fmt。
设置输出文件
在 spdlog 里,要输出文件得打开专门的文件日志记录器。
#include "spdlog/spdlog.h"
#include "spdlog/sinks/basic_file_sink.h"
int main()
{
auto file_logger =
spdlog::basic_logger_mt(
"basic_logger",
"test.log");
spdlog::set_default_logger(
file_logger);
spdlog::info("Into file: {1} {0}",
"world", "hello");
}
执行之后,终端上没有任何输出,但 test.log 文件里就会增加如下的内容:
[2020-01-26 17:47:37.864] [basic_logger] [info] Into file: hello world
日志文件切
在 Easylogging++ 里实现日志文件切换是需要写代码的,而且完善的多文件切换代码需要写上几十行代码才能实现。这项工作在 spdlog 则是超级简单的,因为 spdlog 直接提供了一个实现该功能的日志槽。把上面的例子改造成带日志文件切换只需要修改两处:
#include "spdlog/sinks/rotating_file_sink.h"
// 替换 basic_file_sink.h
…
auto file_sink = make_shared<
rotating_file_sink_mt>(
"test.log", 1048576 * 5, 3);
// 替换 basic_file_sink_mt,文件大
// 小为 5MB,一共保留 3 个日志文件
工具漫谈:编译、格式化、代码检查、排错各显身手
编译器
MSVC
三种编译器里最老资格的就是 MSVC 了。据微软员工在 2015 年的一篇博客,在 MSVC 的代码里还能找到 1982 年写下的注释。这意味着 MSVC 是最历史悠久、最成熟,但也是最有历史包袱的编译器。
微软的编译器在传统代码的优化方面做得一直不错,但对模板的支持则是它的软肋,在 Visual Studio 2015 之前尤其不行——之前模板问题数量巨大,之后就好多了。而 2018 年 11 月 MSVC 宣布终于能够编译 range-v3 库,也成了一件值得庆贺的事。此外,我已经提过,微软对代码的“容忍度”一直有点太高(缺省情况下,不使用 /Za 选项),能接受 C++ 标准认为非法的代码,这至少对写跨平台的代码而言,绝不是一件好事。
MSVC 当然也有领先的地方。它对标准库的实现一直不算慢,较早就提供了比较健壮的线程、正则表达式等标准库。在并发方面,微软也是比较领先的,并主导了协程的技术规格书(ISO/IEC JTC1 SC22 WG21, “Programming languages—C++extensions for coroutines”)。微软一开始支持 C++ 标准的速度比较慢,但慢慢地,微软已经把全面支持 C++ 标准当作了目标,并在 2018 年宣布已全面支持 C++17 标准;虽然同时也承认仍有一些重大问题影响了其编译一些重要的开源 C++ 项目。
另外,在免费的 C++ 集成开发环境里,Visual Studio Community Edition 恐怕可以算是最好的了,至少在 Windows 上是这样。在自动完成功能和调试功能上 Visual Studio 做得特别好,为其他的免费工具所不及。如果你开发的 C++ 程序主要在 Windows 上运行,那 MSVC 就应该是首选了。
Clang
在三个编译器里,最新的就是 Clang。作为 LLVM 项目的一部分,它的最早发布是在 2007 年,然后流行程度一路飙升,到现在成了一个通用的跨平台编译器。其中有不少苹果的支持——因为苹果对 GCC 的许可要求不满意,苹果把 LLVM 开发者 Chris Lattner 招致麾下(2005—2017),期间他除了为苹果设计开发了全新的语言 Swift,Clang 的 C++ 支持也得到了飞速的发展。
作为后来者,Clang 在错误信息易用性上做出了极大的改善。Clang 虽然一直在模拟 GCC 的功能和命令行,但错误信息的友好性是它的最大亮点。在语言层面,Clang 对 C++ 标准的支持也是飞速。
Clang 目前在 macOS 下是默认的 C/C++ 编译器。在 Linux 和 Windows 下当然也都能安装:这种情况下,Clang 会使用平台上的主流 C++ 库,也就是在 Linux 上使用 libstdc++,在 Windows 上使用 MSVC 的 C++ 运行时。只有在 macOS 上,Clang 才会使用其原生 C++ 库,libc++。顺便说一句,如果你想阅读一下现代 C++ 标准库的参考实现的话,libc++ 是可读性最好的——不过,任何一个软件产品的源代码都不是以可读性为第一考量,比起教科书、专栏里的代码例子,libc++ 肯定是要复杂多了。
要想使用最新版本的 Clang,最方便的方式是使用 Homebrew 安装 llvm:
brew install llvm
安装完之后,新的 clang 和 clang++ 工具在 /usr/local/opt/llvm/bin 目录下,和系统原有的命令不会发生冲突。你如果需要使用新的工具的话,需要改变路径的顺序,或者自己创建命令的别名(alias)。
GCC
GCC 的第一个版本发布于 1987 年,是由自由软件运动的发起人 Richard Stallman(常常被缩写为 RMS)亲自写的。因而,从诞生伊始,GCC 就带着很强的意识形态,承担着振兴自由软件的任务。在 GNU/Linux 平台上,GCC 自然是首选的编译器。自由软件的开发者,大部分也选择了 GCC。由于 GCC 是用 GPL 发布的,任何对 GCC 的修改都必须以 GPL 协议发布。这就迫使想修改 GCC 的人要为 GCC 做出贡献。这对自由软件当然是件好事,但对一家公司来讲就未必了。此外,你想拆出 GCC 的一部分来做其他事情,比如对代码进行分析,也绝不是件容易的事。这些问题,实际上就是迫使苹果公司在 LLVM/Clang 上投资的动机了。
初期 GCC 在出错信息的友好程度上一直做得不太好。但 Clang 的出现刺激出了一种和 GCC 之间的良性竞争,到今天,GCC 的错误信息反而是最友好的了。如果遇到程序编译出错在 Clang 里看不明白的话,试着用 GCC 再编译看看,在某些情况下,可能 GCC 的出错信息会更让人明白一些。在可预见的将来,在自由 / 开源软件的开发上,GCC 一直会是编译器的标准。
格式化工具(Clang-Format)
Clang 有着非常模块化的设计,容易被其他工具复用其代码分析功能。LLVM 团队自己也提供一些工具,其中我个人最常用的就是 Clang-Format。
代码检查工具
Clang-Tidy
Clang 项目也提供了其他一些工具,包括代码的静态检查工具 Clang-Tidy 。这是一个比较全面的工具,它除了会提示你危险的用法,也会告诉你如何去现代化你的代码。默认情况下,Clang-Tidy 只做基本的分析。你也可以告诉它你想现代化你的代码和提高代码的可读性:
clang-tidy --checks='clang-analyzer-*,modernize-*,readability-*' test.cpp
Cppcheck
Clang-Tidy 还是一个比较“重”的工具。它需要有一定的配置,需要能看到文件用到的头文件,运行的时间也会较长。而 Cppcheck 就是一个非常轻量的工具了。它运行速度飞快,看不到头文件、不需要配置就能使用。它跟 Clang-Tidy 的重点也不太一样:它强调的是发现代码可能出问题的地方,而不太着重代码风格问题,两者功能并不完全重叠。有条件的情况下,这两个工具可以一起使用。
排错工具
Valgrind
Valgrind 算是一个老牌工具了。它是一个非侵入式的排错工具。根据 Valgrind 的文档,它会导致可执行文件的速度减慢 20 至 30 倍。但它可以在不改变可执行文件的情况下,只要求你在编译时增加产生调试信息的命令行参数(-g),即可查出内存相关的错误。
int main()
{
char* ptr = new char[20];
}
在 Linux 上使用 g++ -g test.cpp 编译之后,然后使用 valgrind --leak-check=full ./a.out 检查运行结果,得到的输出会如下所示:
即其中包含了内存泄漏的信息,包括内存是从什么地方泄漏的。Valgrind 的功能并不只是内存查错,也包含了多线程问题分析等其他功能。要进一步了解相关信息,请查阅其文档。
nvwa::debug_new
在 nvwa 项目里,我也包含了一个很小的内存泄漏检查工具。它的最大优点是小巧,并且对程序运行性能影响极小;缺点主要是不及 Valgrind 易用和强大,只能检查 new 导致的内存泄漏,并需要侵入式地对项目做修改。
c++ test.cpp \../nvwa/nvwa/debug_new.cpp
网页工具
Compiler Explorer
编译器都有输出汇编代码的功能:在 MSVC 上可使用 /Fa,在 GCC 和 Clang 上可使用 -S。不过,要把源代码和汇编对应起来,就需要一定的功力了。在这点上,godbolt.org 可以提供很大的帮助。它配置了多个不同的编译器,可以过滤掉编译器产生的汇编中开发者一般不关心的部分,并能够使用颜色和提示来帮助你关联源代码和产生的汇编。使用这个网站,你不仅可以快速查看你的代码在不同编译器里的优化结果,还能快速分享结果。比如,下面这个链接,就可以展示之前的一个模板元编程代码的编译结果:https://godbolt.org/z/zPNEJ4

当然,作为一个网站,godbolt.org 对代码的复杂度有一定的限制,也不能任意使用你在代码里用到的第三方库(不过,它已经装了不少主流的 C++ 库,如 Boost、Catch2、range-v3 和 cppcoro)。要解决这个问题,你可以在你自己的机器上本地安装它背后的引擎,compiler-explorer 。如果你的代码较复杂,或者有安全、隐私方面的顾虑的话,可以考虑这个方案。
C++ Insights
如果你在上面的链接里点击了“CppInsights”按钮的话,你就会跳转到 C++ Insights 网站,并且你贴在 godbolt.org 的代码也会一起被带过去。这个网站提供了另外一个编译器目前没有提供、但十分有用的功能:展示模板的展开过程。
回想在模板编程时的痛苦之一来自于我们需要在脑子中想象模板是如何展开的,而这个过程非常容易出错。当编译器出错时,我们得通过冗长的错误信息来寻找出错原因的蛛丝马迹;当编译器成功编译了一段我们不那么理解的模板代码时,我们在感到庆幸的同时,也往往会仍然很困惑——而使用这个网站,你就可以看到一个正确工作的模板是如何展开的。
编辑器
Vim
和 C++ 开发有关:
- clang_complete
- nerdcommenter(注释)
- vim-fugitive(git)
- vim-gitgutter(git)
- code_complete
- echofunc
另外,在 .vimrc 里加了下面几句来集成 clang-format:
" Key mappings to use clang-format
noremap <silent> <Tab> :pyxf /usr/local/opt/llvm/share/clang/clang-format.py<CR>
inoremap <silent> <C-F> <ESC>:pyxf /usr/local/opt/llvm/share/clang/clang-format.py<CR>
第三方库管理工具
vcpkg
STL
const引用减少拷贝
#include <cstdio>
#include <iostream>
#include <vector>
using namespace std;
vector<string> func()
{
vector<string> vec = {"a", "b"};
return vec;
}
void print(const vector<string>& vec)
{
for (auto& item : vec) {
cout << item << " ";
}
cout << endl;
}
int main()
{
const vector<string>& res = func();
print(res);
}
字符串分割
#include <cstdio>
#include <iostream>
#include <vector>
#include <string>
std::vector<std::string> split_str(const std::string& src, char split)
{
std::vector<std::string> res;
if (src.empty()) {
return res;
}
std::string::size_type start = 0, next;
while ((next = src.find(split, start)) != std::string::npos) {
res.push_back(src.substr(start, next - start));
start = next + 1;
}
res.push_back(src.substr(start));
return res;
}
void print(std::vector<std::string> &vec)
{
for (auto &item : vec) {
std::cout << item << "|";
}
std::cout << std::endl;
}
int main()
{
std::vector<int> vec;
std::cout << "size: " << vec.size()
<< " capacity: " << vec.capacity() << std::endl;
vec.reserve(10);
vec.push_back(1);
std::cout << "size: " << vec.size()
<< " capacity: " << vec.capacity() << std::endl;
std::string s;
std::vector<std::string> res;
s = "1,2";
res = split_str(s, ',');
print(res);
s = "1,2,";
res = split_str(s, ',');
print(res);
s = ",1,2";
res = split_str(s, ',');
print(res);
s = "1";
res = split_str(s, ',');
print(res);
s = "";
res = split_str(s, ',');
print(res);
s = ",";
res = split_str(s, ',');
print(res);
s = ",,";
res = split_str(s, ',');
print(res);
}
/*
g++ -o test test.cpp -std=c++11
./test
size: 0 capacity: 0
size: 1 capacity: 10
1|2|
1|2||
|1|2|
1|
||
|||
*/
代码片段
Time
DateTime and UnixTime
#define _XOPEN_SOURCE
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <time.h>
int main()
{
struct tm tm = {0};
char *res = strptime("2019-10-01 18:00:00", "%Y-%m-%d %H:%M:%S", &tm);
if (res == NULL) {
printf("strptime err\n");
return -1;
}
time_t t = mktime(&tm);
// equal to `date -d "2019-10-01 18:00:00" +%s`
printf("t[%ld]\n", t);
return 0;
}
int datetime_to_unixtime(std::string &end_time, time_t &expired_time, std::string &errinfo)
{
struct tm tm = {0};
// end_time's format is like "2019-10-01 18:00:00"
char *res = strptime(end_time.c_str(), "%Y-%m-%d %H:%M:%S", &tm);
if (res == NULL) {
errinfo = "tc_subscribe ans, end_time is invalid";
printf("%s", errinfo.c_str());
return 1;
}
expired_time = mktime(&tm);
return 0;
}
int get_unixtime(time_t &unixtime, std::string &datetime)
{
unixtime = time(NULL);
char buf[64] = {0};
struct timeval tv;
struct tm tm_obj;
gettimeofday(&tv, NULL);
localtime_r(&tv.tv_sec, &tm_obj);
strftime(buf, sizeof(buf), "%Y-%m-%d %H:%M:%S", &tm_obj);
datetime = buf;
return 0;
}
refer:
- strptime
- mktime
- How to convert a string variable containing time to time_t type in c++?
- Date/time conversion: string representation to time_t
Regex
How do I write a regular expression that matches an IPv4 dotted address?
#include <boost/regex.hpp>
/*
作用: 使用boost库, 实现IPv4匹配
10.0.0.0 - 10.255.255.255
172.16.0.0 - 172.31.255.255
192.168.0.0 - 192.168.255.255
*/
void test_regex_ip()
{
std::string ip[] = {
std::string("10.0.0.1"),
std::string("172.16.0.1"),
std::string("192.168.0.1"),
std::string("10.*.*.*"),
std::string("172.16.*.*"),
std::string("192.168.*.*")
};
for (int i = 0; i != sizeof(ip) / sizeof(ip[0]); ++i) {
auto match = [&] {
//boost::regex pattern("(\\d{1,3}(\\.\\d{1,3}){3})");
//boost::regex pattern("(\\d{1,3}(\\..*){3})");
boost::regex pattern("(172(\\.\\d{1,3}){2}(\\..*))");
boost::smatch match;
try {
if (boost::regex_search(ip[i], match, pattern)) {
std::cout << "ip: " << match[1] << std::endl;
} else {
std::cout << ip[i] << " did not match\n";
}
} catch (boost::regex_error &e) {
std::cout << "err: " << e.what() << std::endl;
}
};
match();
}
}
Unit Test
#include "test.h"
std::string ss;
def_test(100000);
def_case(ss = "");
def_case(ss = std::to_string(12345678));
// test.h
#include "base/def.h"
#include "base/time.h"
#include "base/log.h"
#define def_test(n) \
int N = n; \
int64 _us; \
Timer _t
#define def_case(func) \
do { \
_t.restart(); \
for (int i = 0; i < N; ++i) { \
func; \
} \
_us = _t.us(); \
CLOG << #func << ":\t" << (_us * 1.0 / N) << " us"; \
} while (0)
Log
内联汇编
GCC为内联汇编提供特殊结构,其格式如下。汇编程序模板由汇编指令组成。输入操作数是充当指令输入操作数使用的C表达式。输出操作数是将对其执行汇编指令输出的C表达式。内联汇编的重要性体现在它能够灵活操作,而且可以使其输出通过C变量显示出来。因为它具有这种能力,所以”asm”可以用作汇编指令和包含它的C程序之间的接口。简单内联汇编只包括指令,而扩展内联汇编包括操作数。
asm ( assembler template
: output operands (optional)
: input operands (optional)
: list of clobbered registers
(optional)
);
编译器
is-pragma-once-a-safe-include-guard
网络
网络就看 Boost.Asio 吧。这个将是未来 C++ 网络标准库的基础。
C++ REST SDK:使用现代C++开发网络应用
C++ REST SDK(也写作 cpprestsdk),一个支持 HTTP 协议、主要用于 RESTful 接口开发的 C++ 库。
问题,你认为用多少行代码可以写出一个类似于 curl 的 HTTP 客户端?
答案:使用 C++ REST SDK 的话,只需要五十多行有效代码(即使是适配到目前的窄小的手机屏幕上)。
#include <iostream>
#ifdef _WIN32
#include <fcntl.h>
#include <io.h>
#endif
#include <cpprest/http_client.h>
using namespace utility;
using namespace web::http;
using namespace web::http::client;
using std::cerr;
using std::endl;
#ifdef _WIN32
#define tcout std::wcout
#else
#define tcout std::cout
#endif
auto get_headers(http_response resp)
{
auto headers = resp.to_string();
auto end =
headers.find(U("\r\n\r\n"));
if (end != string_t::npos) {
headers.resize(end + 4);
};
return headers;
}
auto get_request(string_t uri)
{
http_client client{uri};
// 用 GET 方式发起一个客户端请求
auto request =
client.request(methods::GET)
.then([](http_response resp) {
if (resp.status_code() !=
status_codes::OK) {
// 不 OK,显示当前响应信息
auto headers =
get_headers(resp);
tcout << headers;
}
// 进一步取出完整响应
return resp
.extract_string();
})
.then([](string_t str) {
// 输出到终端
tcout << str;
});
return request;
}
#ifdef _WIN32
int wmain(int argc, wchar_t* argv[])
#else
int main(int argc, char* argv[])
#endif
{
#ifdef _WIN32
_setmode(_fileno(stdout),
_O_WTEXT);
#endif
if (argc != 2) {
cerr << "A URL is needed\n";
return 1;
}
// 等待请求及其关联处理全部完成
try {
auto request =
get_request(argv[1]);
request.wait();
}
// 处理请求过程中产生的异常
catch (const std::exception& e) {
cerr << "Error exception: "
<< e.what() << endl;
return 1;
}
}
- 根据平台来定义
tcout,确保多语言的文字能够正确输出。 - 定义了 get_headers,来从 http_response 中取出头部的字符串表示。
client.request(methods::GET).then构造了一个客户端请求,并使用then方法串联了两个下一步的动作。http_client::request的返回值是pplx::task<http_response>。then是pplx::task类模板的成员函数,参数是能接受其类型参数对象的函数对象。除了最后一个then块,其他每个then里都应该返回一个pplx::task,而task的内部类型就是下一个 then 块里函数对象接受的参数的类型。.then([](http_response resp)之后,是第一段异步处理代码。参数类型是http_response——因为http_client::request的返回值是pplx::task<http_response>。代码中判断如果响应的 HTTP 状态码不是 200 OK,就会显示响应头来帮助调试。然后,进一步取出所有的响应内容(可能需要进一步的异步处理,等待后续的 HTTP 响应到达)。.then([](string_t str)之后,是第二段异步处理代码。参数类型是string_t——因为上一段then块的返回值是pplx::task<string_t>。代码中就是简单地把需要输出的内容输出到终端。- 根据平台来定义合适的程序入口,确保命令行参数的正确处理。
- 在 Windows 上把标准输出设置成宽字符模式,来确保宽字符(串)能正确输出。注意
string_t在 Windows 上是wstring,在其他平台上是string。 - 程序主体,产生 HTTP 请求、等待 HTTP 请求完成,并处理相关的异常。
整体而言,这个代码还是很简单的,虽然这种代码风格,对于之前没有接触过这种函数式编程风格的人来讲会有点奇怪——这被称作持续传递风格(continuation-passing style),显式地把上一段处理的结果传递到下一个函数中。这个代码已经处理了 Windows 环境和 Unix 环境的差异,底下是相当复杂的。
安装和编译
上面的代码本身虽然简单,但要把它编译成可执行文件却比较复杂——C++ REST SDK 有外部依赖,在 Windows 上和 Unix 上还不太一样。它的编译和安装也略复杂,如果你没有这方面的经验的话,建议尽量使用平台推荐的二进制包的安装方式。由于其依赖较多,使用它的编译命令行也较为复杂。正式项目中绝对是需要使用项目管理软件的(如 cmake)。此处,给出手工编译的典型命令行,仅供尝试编译上面的例子作参考。
- Windows MSVC:
cl /EHsc /std:c++17 test.cpp cpprest.lib zlib.lib libeay32.lib ssleay32.lib winhttp.lib httpapi.lib bcrypt.lib crypt32.lib advapi32.lib gdi32.lib user32.lib
- Linux GCC:
g++ -std=c++17 -pthread test.cpp -lcpprest -lcrypto -lssl -lboost_thread -lboost_chrono -lboost_system
- macOS Clang:
clang++ -std=c++17 test.cpp -lcpprest -lcrypto -lssl -lboost_thread-mt -lboost_chrono-mt
tcpdump
- tcpdump/wireshark 抓包及分析(2019)
- tcpdump: An Incomplete Guide
- [译] 使用 Linux tracepoint、perf 和 eBPF 跟踪数据包 (2017)
文档
开源
- An elegant and efficient C++ basic library for Linux, Windows and Mac
- My small collection of C++ utilities
文章
汇编
https://godbolt.org/
C++好书荐读
入门介绍
- Bjarne Stroustrup, A Tour of C++, 2nd ed. Addison-Wesley, 2018(推荐指数:★★★★★)
中文版:王刚译,《C++ 语言导学》(第二版)。机械工业出版社,2019
这是唯一一本较为浅显的全面介绍现代 C++ 的入门书。书虽然较薄,但 C++ 之父的功力在那里,时有精妙之论。书的覆盖面很广,介绍了 C++ 的基本功能和惯用法。这本书的讲授方式,也体现了他的透过高层抽象来教授 C++ 的理念。
最佳实践
- Scott Meyers, Effective C++: 55 Specific Ways to Improve Your Programs and Designs, 3rd ed. Addison-Wesley, 2005(推荐指数:★★★★)
中文版:侯捷译《Effective C++ 中文版》(第三版)。电子工业出版社,2011
- Scott Meyers, Effective STL: 50 Specific Ways to Improve Your Use of the Standard Template Library. Addison-Wesley, 2001(推荐指数:★★★★)
中文版:潘爱民、陈铭、邹开红译《Effective STL 中文版》。清华大学出版社,2006
- Scott Meyers, Effective Modern C++: 42 Specific Ways to Improve Your Use of C++11 and C++14. O’Reilly, 2014(推荐指数:★★★★★)
中文版:高博译《Effective Modern C++ 中文版》。中国电力出版社,2018
C++ 的大牛中有三人尤其让我觉得高山仰止,Scott Meyers 就是其中之一——Bjarne 让人感觉是睿智,而 Scott Meyers、Andrei Alexandrescu 和 Herb Sutter 则会让人感觉智商被碾压。Scott 对 C++ 语言的理解无疑是非常深入的,并以良好的文笔写出了好几代的 C++ 最佳实践。
深入学习
- Herb Sutter, Exceptional C++: 47 Engineering Puzzles, Programming Problems, and Solutions. Addison-Wesley, 1999(推荐指数:★★★★)
中文版:卓小涛译《Exceptional C++ 中文版》。中国电力出版社,2003
- Herb Sutter and Andrei Alexandrescu, C++ Coding Standards: 101 Rules, Guidelines, and Best Practices. Addison-Wesley, 2004(推荐指数:★★★★)
中文版:刘基诚译《C++ 编程规范:101 条规则准则与最佳实践》。人民邮电出版社,2006
- 侯捷,《STL 源码剖析》。华中科技大学出版社,2002(推荐指数:★★★★)
高级专题
- Alexander A. Stepanov and Daniel E. Rose, From Mathematics to Generic Programming. Addison-Wesley, 2014(推荐指数:★★★★★)
中文版:爱飞翔译《数学与泛型编程:高效编程的奥秘》。机械工业出版社,2017
- Andrei Alexandrescu, Modern C++ Design: Generic Programming and Design Patterns Applied. Addison-Wesley, 2001(推荐指数:★★★★)
中文版:侯捷、於春景译《C++ 设计新思维》。华中科技大学出版社,2003
-
Anthony Williams, C++ Concurrency in Action, 2nd ed. Manning, 2019(推荐指数:★★★★)
-
Ivan Čukić, Functional Programming in C++. Manning, 2019(推荐指数:★★★★)
参考书
- Bjarne Stroustrup, The C++ Programming Language, 4th ed. Addison-Wesley, 2013(推荐指数:★★★★)
中文版:王刚、杨巨峰译《C++ 程序设计语言》。机械工业出版社, 2016
没什么可多说的,C++ 之父亲自执笔写的 C++ 语言。主要遗憾是没有覆盖 C++14/17 的内容。中文版分为两卷出版,内容实在是有点多了。不过,如果你没有看过之前的版本,并且对 C++ 已经有一定经验的话,这个新版还是会让你觉得,姜还是老的辣!
- Nicolai M. Josuttis, The C++ Standard Library: A Tutorial and Reference, 2nd ed. Addison-Wesley, 2012(推荐指数:★★★★)
Nicolai 写的这本经典书被人称为既完备又通俗易懂,也是殊为不易。从 C++11 的角度,这本书堪称完美。当然,超过一千页的大部头,要看完也是颇为不容易了。
C++ 的设计哲学
- Bjarne Stroustrup, The Design and Evolution of C++. Addison-Wesley, 1994(推荐指数:★★★)
中文版:裘宗燕译《C++ 语言的设计与演化》。科学出版社, 2002
这本书不是给所有的 C++ 开发者准备的。它讨论的是为什么 C++ 会成为今天(1994 年)这个样子。如果你对 C++ 的设计思想感兴趣,那这本书会比较有用些。如果你对历史不感兴趣,那这本书不看也不会有很大问题。
- Bruce Eckel, Thinking in C++, Vol. 1: Introduction to Standard C++, 2nd ed. Prentice-Hall, 2000 / Bruce Eckel and Chuck Allison, Thinking in C++, Vol. 2: Practical Programming. Pearson, 2003
中文版:刘宗田等译《C++ 编程思想》。机械工业出版社,2011
非 C++ 的经典书目
- W. Richard Stevens, TCP/IP Illustrated Volume 1: The Protocols. Addison-Wesley, 1994
- Gary R. Wright and W. Richard Stevens, TCP/IP Illustrated Volume 2: The Implementation. Addison-Wesley, 1995
- W. Richard Stevens, TCP/IP Illustrated Volume 3: TCP for Transactions, HTTP, NNTP and the Unix Domain Protocols. Addison-Wesley 1996
不是所有的书都是越新越好,《TCP/IP 详解》就是其中一例。W. Richard Stevens 写的卷一比后人补写的卷一第二版评价更高,就是其中一例。关于 TCP/IP 的编程,这恐怕是难以超越的经典了。不管你使用什么语言开发,如果你的工作牵涉到网络协议的话,这套书恐怕都值得一读——尤其是卷一。
- W. Richard Stevens and Stephen A. Rago, Advanced Programming in the UNIX Environment, 3rd, ed… Addison-Wesley, 2013
中文版: 戚正伟、张亚英、尤晋元译《UNIX 环境高级编程》。人民邮电出版社,2014
从事 C/C++ 编程应当对操作系统有深入的了解,而这本书就是讨论 Unix 环境下的编程的。鉴于 Windows 下都有了 Unix 的编程环境,Unix 恐怕是开发人员必学的一课了。这本书是经典,而它的第三版至少没有损坏前两版的名声。
- Erich Gamma, Richard Helm, Ralph Johson, John Vlissides, and Grady Booch, Design Patterns: Elements of Reusable Object-Oriented Software. Addison-Wesley, 1994
中文版:李英军、马晓星、蔡敏、刘建中等译《设计模式》。机械工业出版社,2000
经典就是经典,没什么可多说的。提示:如果你感觉这本书很枯燥、没用,那就等你有了更多的项目经验再回过头来看一下,也许就有了不同的体验。
- Eric S. Raymond, The Art of UNIX Programming. Addison-Wesley, 2003
中文版:姜宏、何源、蔡晓骏译《UNIX 编程艺术》。电子工业出版社,2006
抱歉,这仍然是一本 Unix 相关的经典。如果你对 Unix 设计哲学有兴趣的话,那这本书仍然无可替代。如果你愿意看英文的话,这本书的英文一直是有在线免费版本的。
- Pete McBreen, Software Craftsmanship: The New Imperative. Addison-Wesley, 2001
中文版:熊节译《软件工艺》。人民邮电出版社,2004
这本书讲的是软件开发的过程,强调的是软件开发中人的作用。相比其他的推荐书,这本要“软”不少。但不等于这本书不重要。如果你之前只关注纯技术问题的话,那现在是时间关注一下软件开发中人的问题了。
- Paul Graham, Hackers & Painters: Big Ideas From The Computer Age. O’Reilly, 2008
中文版:阮一峰译《黑客与画家》。人民邮电出版社,2011
这本讲的是一个更玄的问题:黑客是如何工作的。作者 Paul Graham 也是一名计算机界的大神了,用 Lisp 写出了被 Yahoo! 收购的网上商店,然后又从事风险投资,创办了著名的孵化器公司 Y Combinator。这本书是他的一本文集,讨论了黑客——即优秀程序员——的爱好、动机、工作方法等等。你可以从中学习一下,一个优秀的程序员是如何工作的,包括为什么脚本语言比静态类型语言受欢迎。
- Robert C. Martin, Clean Code: A Handbook of Agile Software Craftsmanship. Prentice Hall, 2008
中文版:韩磊译《代码整洁之道》。人民邮电出版社,2010
Bob 大叔的书如果你之前没看过的话,这本是必看的。这本也是语言无关的,讲述的是如何写出干净的代码。有些建议初看也许有点出乎意料,但细想之下又符合常理。推荐。
其他
别忘了下面这两个重要的免费网站:
-
C++ Reference:https://en.cppreference.com
-
C++ Core Guidelines:https://isocpp.github.io/CppCoreGuidelines/CppCoreGuidelines
一万小时定律
在大部分的领域里,从普通人变为专家需要投入至少约一万小时的时间。如果按每天工作八个小时、一周工作五天计算,那么成为一个领域的专家至少需要五年。如果投入时间不那么多,或者问题领域更复杂,“十年磨一剑”也是件很自然的事。注意这是个约数,也只是必要条件,而非充分条件。时间少了,肯定完全没有希望;大于等于一万小时,也不能保证你一定成为专家。即使天才也需要勤学苦练。而如果天资真的不足,那估计投入再多也不会有啥效果。如果你看得更仔细一点,你在了解一万小时定律时,应该会注意到不是随便练习一万小时就有用的。你需要的是刻意的练习。换句话说,练习是为了磨练你的思维(或肌肉,或其他需要训练的部分),而不能只是枯燥的练习而已。
目标和计划,并每天坚持。比如:
- 每天阅读一篇英语的编程文章
- 每天看一条英文的 C++ Core Guideline
- 每天看 5 页 C++ 之父的 The C++ Programming Language(或其他的英文编程书籍)
- 每天在 Stack Overflow 上看 3 个问答
- xxx
程序员该有的三大美德
Larry Wall 认为程序员该有的三大美德:懒惰,急切,傲慢(laziness, impatience, hubris;初次阐释于 Programming Perl 第二版)。翻译出完整的原文:
- 懒惰
使得你花费极大努力来减少总体能量开销的品质。懒惰使你去写能让别人觉得有用、并减少繁杂工作的程序;你也会用文档描述你的程序,免得你不得不去回答别人的问题。因此,这是程序员的第一大美德。
- 急切
当计算机不能满足你的需求时你所感到的愤怒。这使得你写的程序不仅满足自己的需求,还能预期其他需求。至少努力去这么做。因此,这是程序员的第二大美德。
- 傲慢
老天都受不了你的极度骄傲。这种品质使得你写程序(和维护程序)时不允许别人有机会来说三道四。因此这是程序员的第三大美德。
专栏
Refer
- https://www.learncpp.com/
- https://zhjwpku.com/assets/pdf/books/C++.Primer.5th.Edition_2013.pdf
- What are Aggregates and PODs and how/why are they special?