CPP Optimzing
- 性能调优的必要性(思考启示)
- 可观测性
- 性能基准
- 性能可比较
- 性能热点分析
- 性能优化案例
- 优化代码案例
- 影响性能的案例
- 关于优化的其他思考
- 性能优化最佳实践
- Memory Benchmark
- More
- Refer
“Premature optimization is the root of all evil” — Donald Knuth
“Data dominates. If you’ve chosen the right data structures and organized things well, the algorithms will almost always be self-evident. Data structures, not algorithms, are central to programming.” — Rob Pike’s 5 Rules of Programming
性能调优的必要性(思考启示)
- “这儿一纳秒,那儿一纳秒”。指令的处理速度惊人,浪费的指令积累也越快。
- 性能问题的本质,是系统资源(CPU,内存,I/O)已经达到瓶颈。
- 海恩法则:每一起严重事故的背后,必然有29次轻微事故和300起未遂先兆,以及1000起事故隐患。因此,规避问题与寻找根因并重。

可观测性
灵魂拷问:为什么在客户端看到的延迟是 100ms,而server端处理只用了 20ms,其他的 80ms 哪儿去了?
实际处理耗时 = 计算 + 调度 + 网络
- 底层支持。Linux跟踪技术
- 对应的工具。Brendan Gregg的Linux性能工具图谱
性能基准
前提假设(理想情况):
- Only one CPU, no NUMA
- Only ALU/FPU Operations (not involve memory, due to cache miss)
- Only in L1 cache
数据指标:
| Operation | CPU clocks cycles |
|---|---|
| ADD/MOV/OR/… | 1 |
| FADD/FSUB | 2-5 |
| MUL/IMUL | 1-7 |
| FMUL | 2-5 |
| DIV/IDIV | 12-44 |
| FDIV | 37-39 |
| L1/L2/L3 | 4/12/44 |
| LOCK CMPXCHG (CAS) | 15-30 |
| C/C++ Function Calls | 25-250 |
| Allocations | 200-500 |
| Kernel Calls | 1000-1500 |
| C++ Exceptions | 5000 |
| Thread Context Switches | 10000 |
A CPU with a clock speed of 2.4 GHz executes 2.4 billion cycles per second. Sometimes, multiple instructions are completed in a single clock cycle; in other cases, one instruction might be handled over multiple clock cycles.
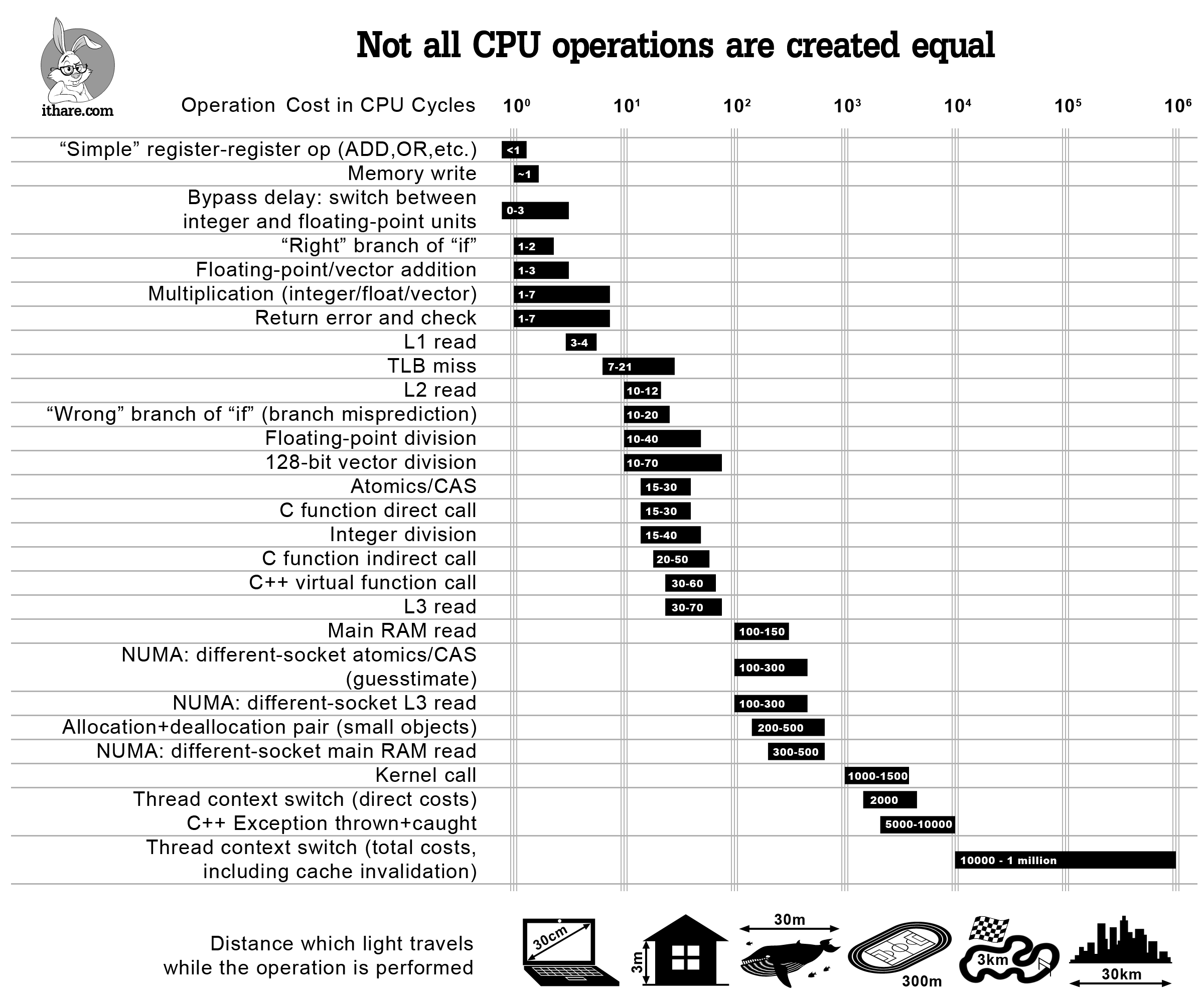
refer: Operation Costs in CPU Clock Cycles
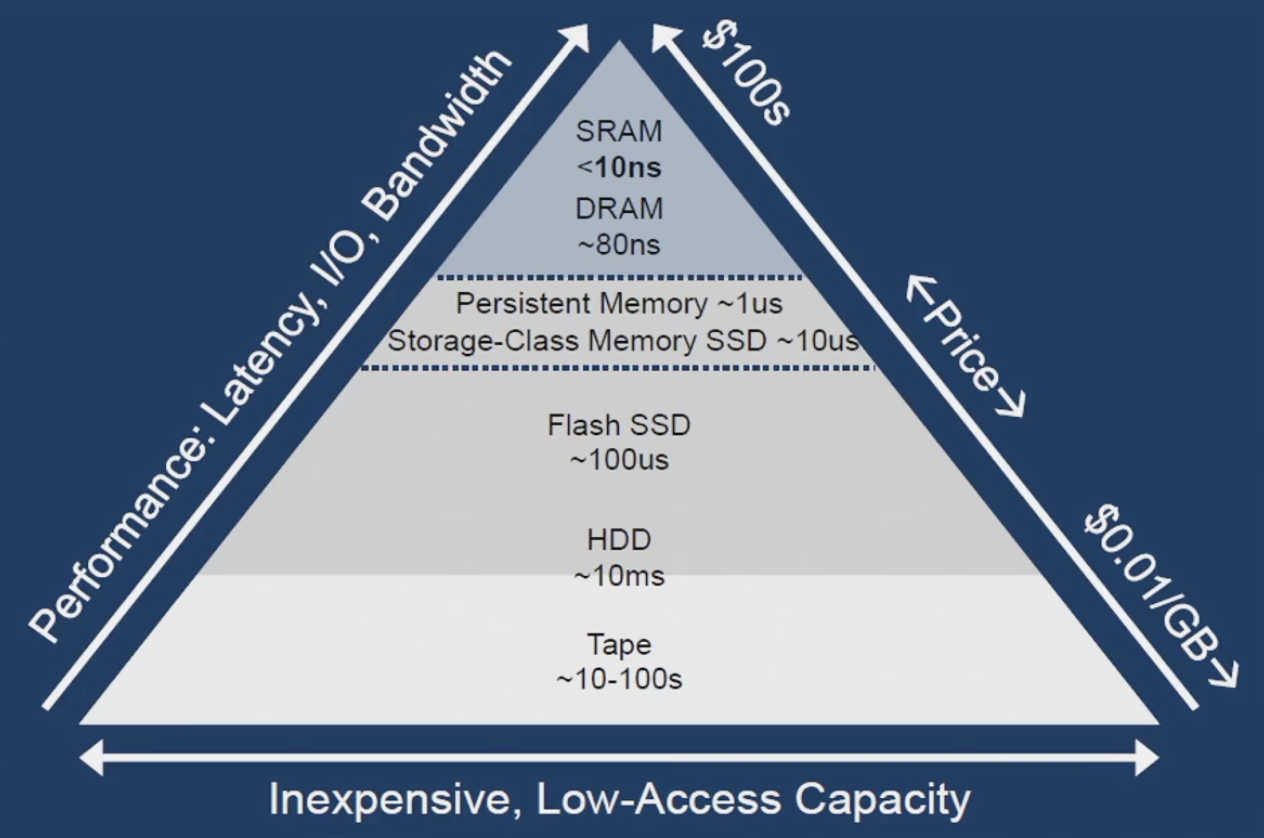
存储延迟级别:
性能可比较
例子1: 比较不同查找实现的执行效率。
static void VectorFind(benchmark::State& state) {
int max = 10000;
std::string last_v = std::to_string(max - 1);
std::vector<std::string> vec;
for (int i = 0; i != max; ++i) {
vec.push_back(std::to_string(i));
}
// Code inside this loop is measured repeatedly
for (auto _ : state) {
std::find(vec.begin(), vec.end(), last_v);
}
}
// Register the function as a benchmark
BENCHMARK(VectorFind);
static void SetFind(benchmark::State& state) {
int max = 10000;
std::string last_v = std::to_string(max - 1);
std::set<std::string> set;
for (int i = 0; i != max; ++i) {
set.insert(std::to_string(i));
}
for (auto _ : state) {
set.find(last_v);
}
}
BENCHMARK(SetFind);
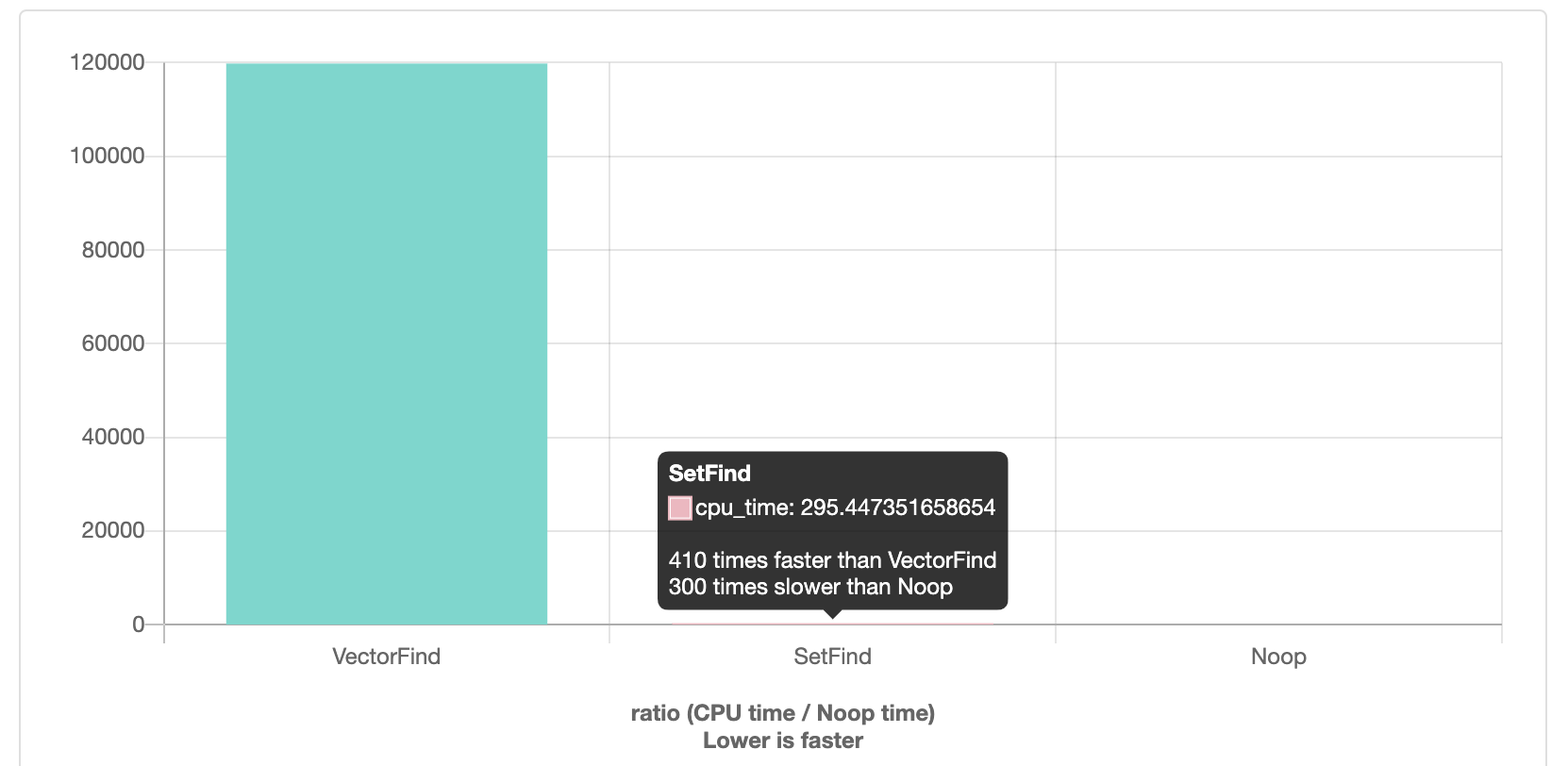
例子2:循环展开优化(Loop unwinding),使用循环展开减少分支预测的错误次数,从而提高程序执行的速度。但是代码中进行循环展开会导致代码膨胀以及可读性的下降,通常情况使用编译器优化即可。
static void test1(benchmark::State& state) {
int sum = 0;
for (auto _ : state) {
sum += 2;
benchmark::DoNotOptimize(sum);
}
}
BENCHMARK(test1);
static void test2(benchmark::State& state) {
int sum = 0;
for (auto _ : state) {
sum += 1;
sum += 1;
benchmark::DoNotOptimize(sum);
}
}
BENCHMARK(test2);
static void test3(benchmark::State& state) {
int sum = 0;
int sum1 = 0, sum2 = 0;
for (auto _ : state) {
sum1 += 1;
sum2 += 1;
benchmark::DoNotOptimize(sum1);
benchmark::DoNotOptimize(sum2);
}
sum = sum1 + sum2;
}
BENCHMARK(test3);
选择合适的Benchmarking 工具,提供标准的量化比较。其他情况测试
$ ./celero_benchmark
Celero
Timer resolution: 0.001000 us
| Group | Experiment | Prob. Space | Samples | Iterations | Baseline | us/Iteration | Iterations/sec | RAM (bytes) |
| :---: | :-----------: | :---------: | :-----: | :--------: | :------: | :----------: | :------------: | :---------: |
| find | vector | Null | 1 | 1 | 1.00000 | 172.00000 | 5813.95 | 51277824 |
| find | pb_repeated | Null | 1 | 1 | 73.59302 | 12658.00000 | 79.00 | 51777536 |
| find | set | Null | 10 | 20 | 0.00058 | 0.10000 | 10000000.00 | 51777536 |
| find | unordered_set | Null | 10 | 20 | 0.00029 | 0.05000 | 20000000.00 | 51777536 |
| find | flat_set | Null | 10 | 20 | 0.00058 | 0.10000 | 10000000.00 | 51777536 |
Completed in 00:00:00.028138
性能热点分析
正常情况:
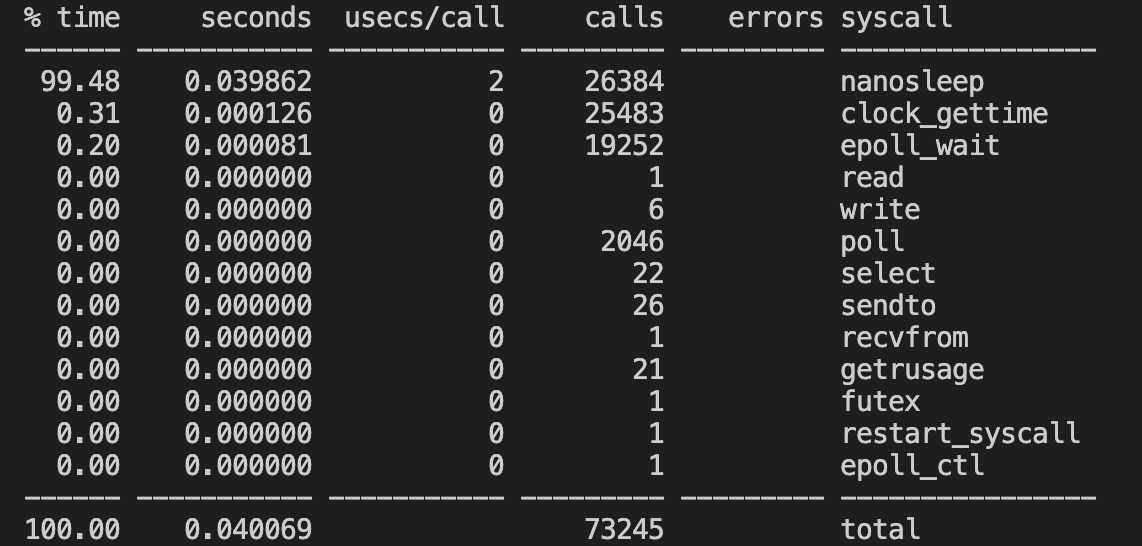
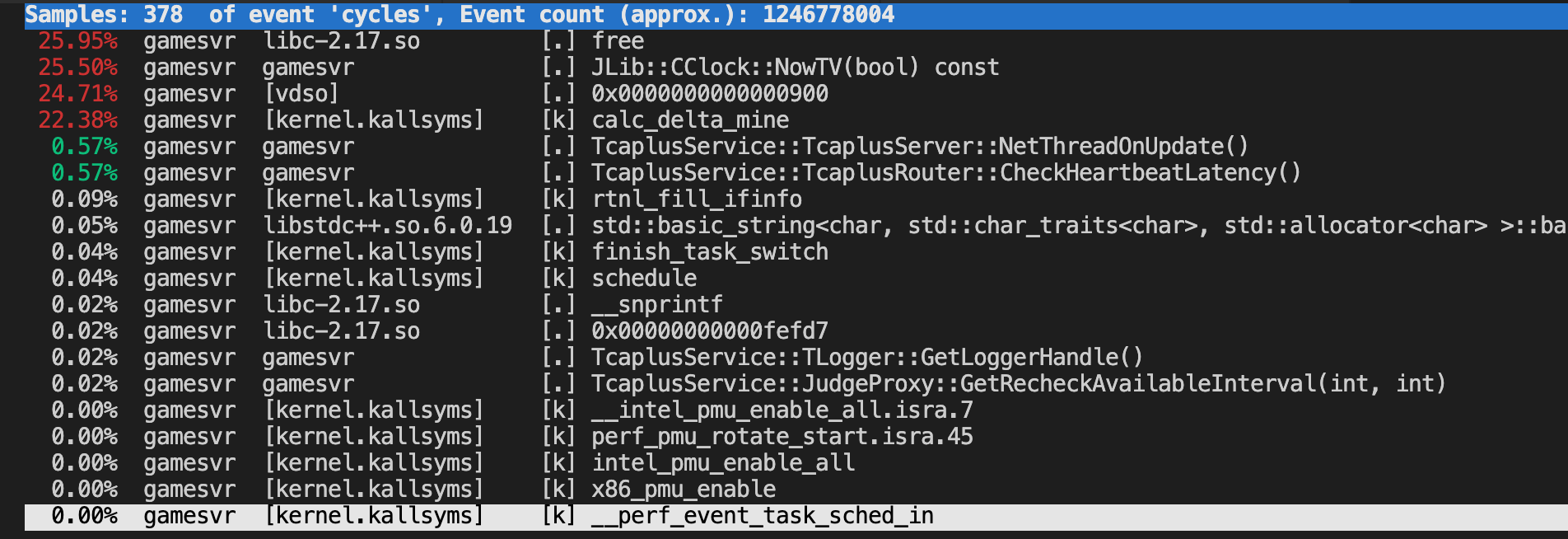
异常情况:(模拟I/O异常)
# spawn 1 workers spinning on sync()
# spawn 1 workers spinning on write()/unlink()
$ stress -i 1 --hdd 1 --timeout 600
stress: info: [15180] dispatching hogs: 0 cpu, 1 io, 0 vm, 1 hdd
stress: info: [15180] successful run completed in 601s
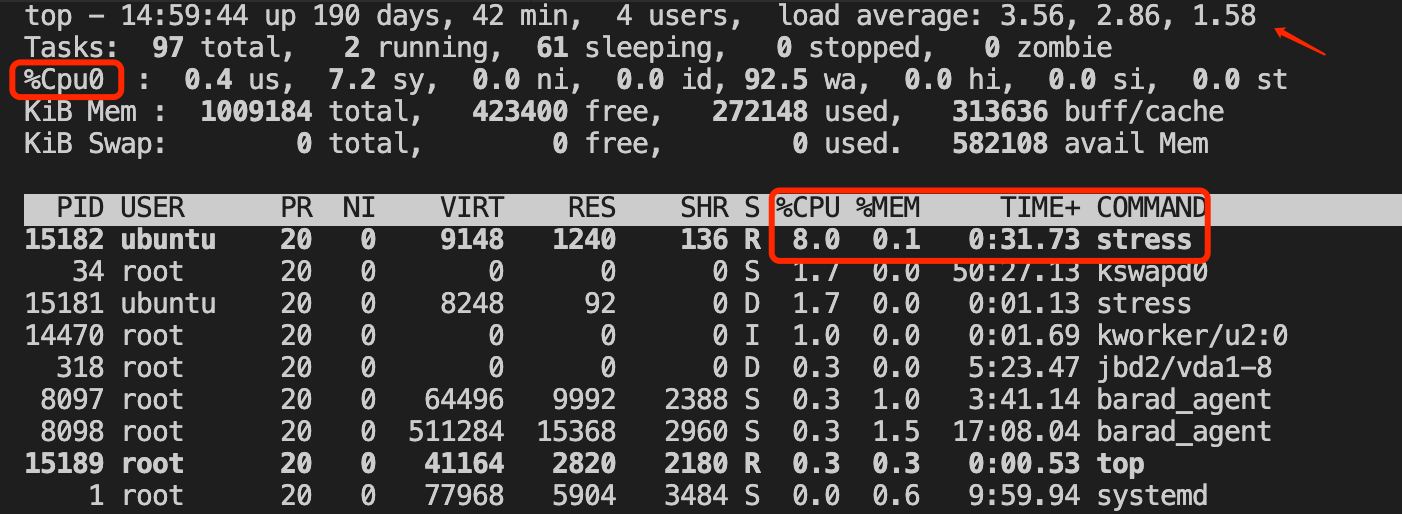
使用iostat查看磁盘使用情况:

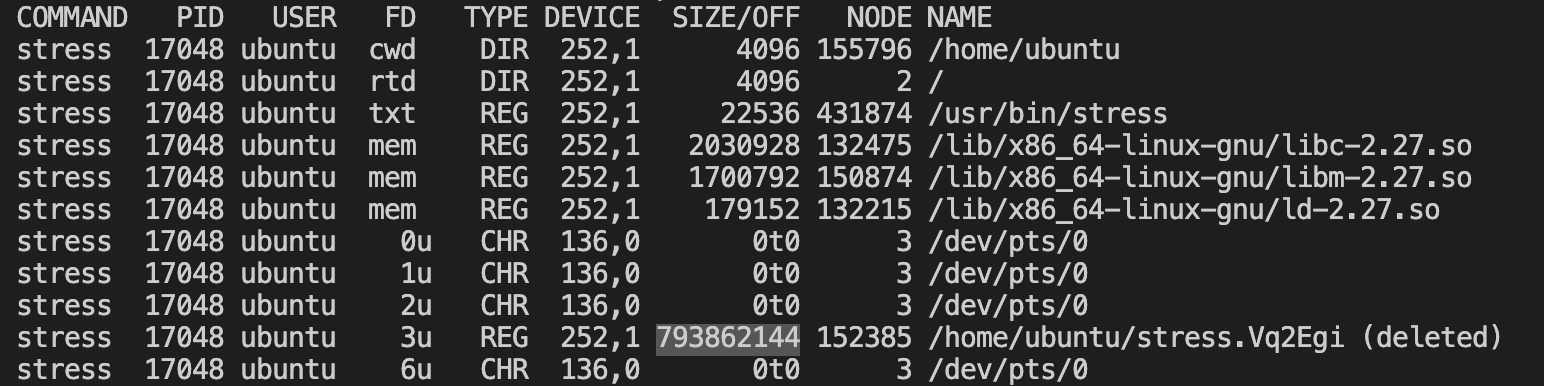
使用lsof查看进程操作的fd情况:
使用strace查看进程执行情况:
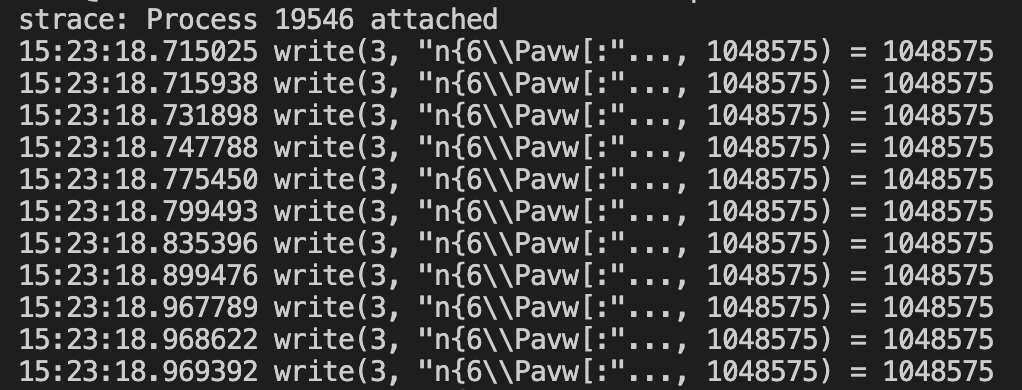
再使用perf分析更详细的调用情况:
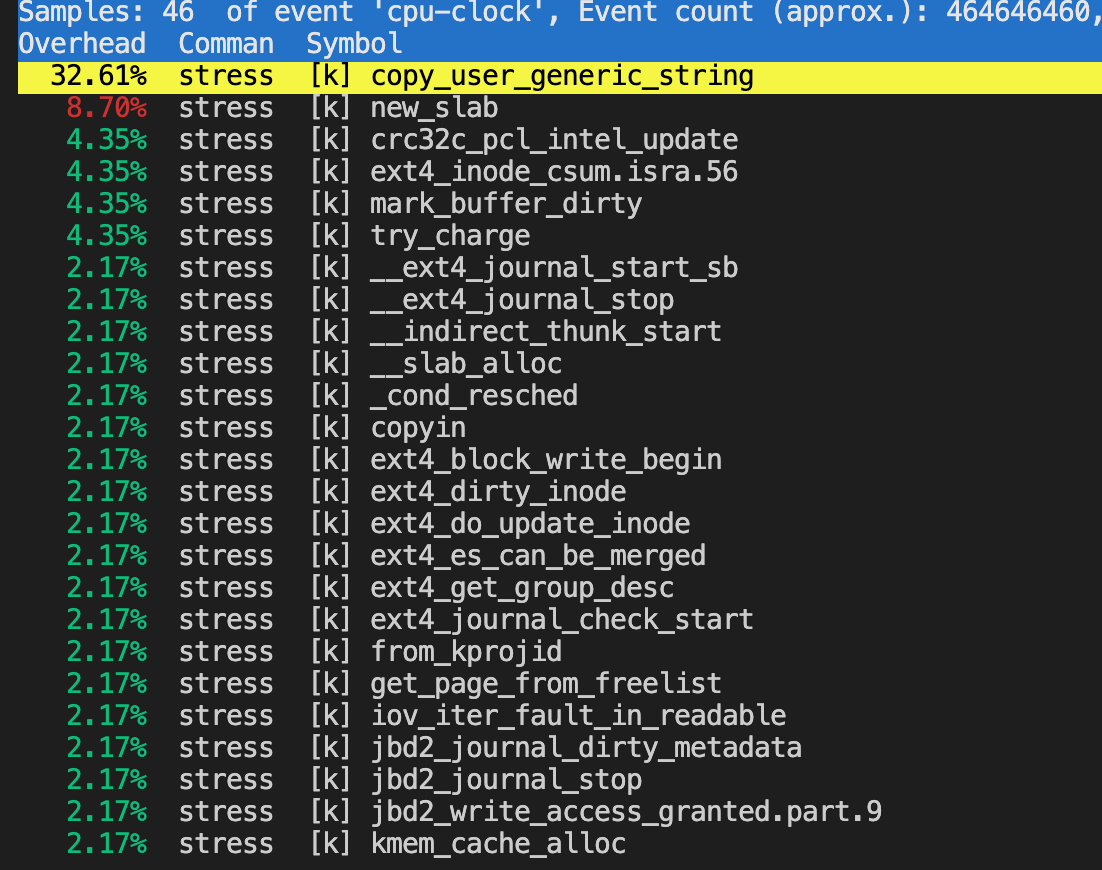
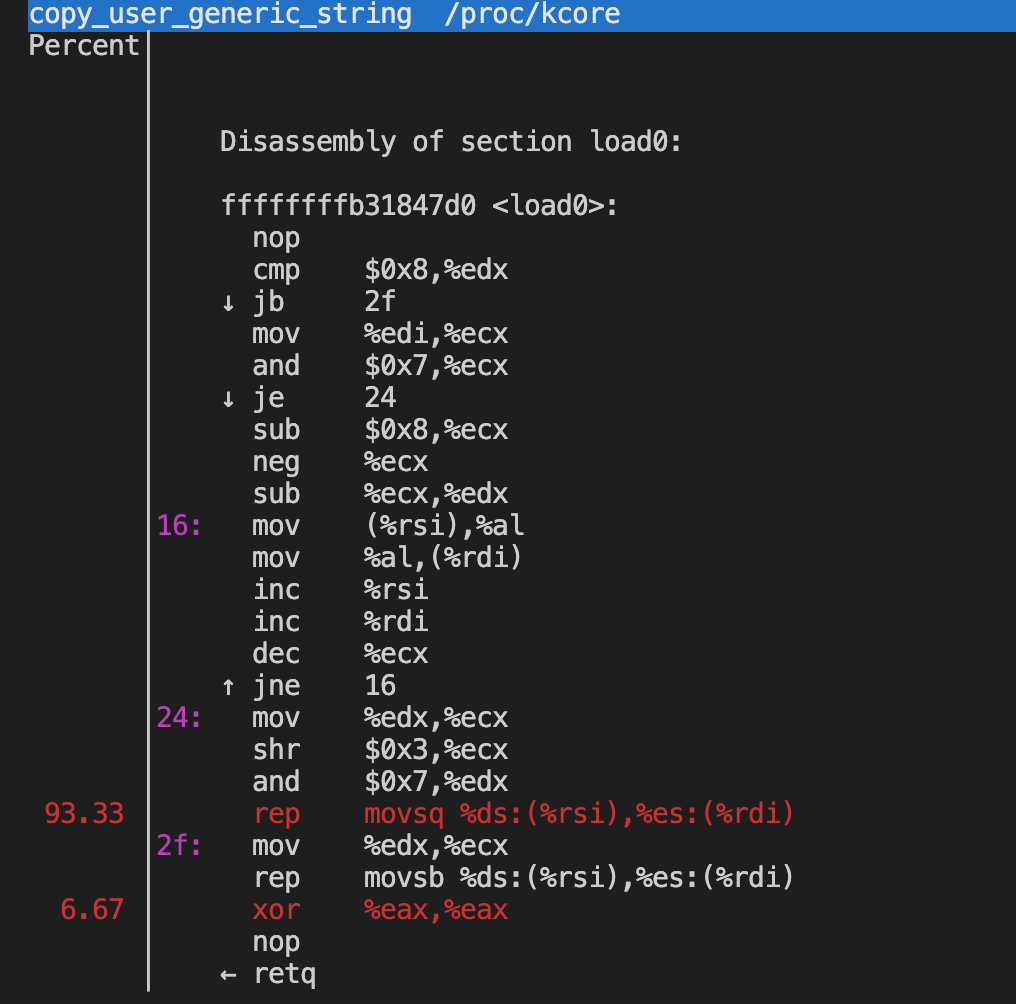
- 通过
top或者uptime命令查看系统的负载情况。在实际生产环境中,通常当平均负载高于CPU数量70%的时候,就需要排查负载高的问题了。其中,CPU密集型和I/O密集型的服务,CPU负载和CPU使用率可能不一样。
平均负载,是指单位时间内,处于可运行状态(R)和不可中断状态(D)的进程数。所以,它不仅包括了正在使用CPU的进程,还包括等待CPU和等待I/O的进程。
CPU使用率,是单位时间内CPU使用情况的统计,以百分比的方式展示。CPU使用率 = 1 - 空闲时间/总CPU时间
- 使用内存池减少内存的动态分配,以及禁止Swap。如果必须开启Swap,则降低 swappiness(
/proc/sys/vm/swappiness)的值,减少内存回收时Swap的使用倾向。另外,可以使用/dev/shm共享内存改善程序的处理性能(例如,配置系统)。
32位系统的内核空间占用1G,位于最高处,剩下的3G是用户空间;而64位系统的内核空间和用户空间都是128T,分别占据整个内存空间的最高和最低处,剩下的中间部分是未定义的。
- 磁盘I/O的IOPS和吞吐量。换用性能更好的磁盘,比如,用SSD替代HDD。在顺序读比较多的场景中,可以增大磁盘的预读数据。用追加写代替随机写,减少寻址开销,加快I/O写的速度。借助缓存I/O,充分利用系统缓存,降低实际I/O的次数。使用
fio(Flexible I/O Tester),通过设置跳过缓存,I/O模式等来测试磁盘的IOPS,吞吐量,以及响应时间等核心指标。通常针对不同I/O大小(512B至1MB)分别在随机读,顺序读,随机写,顺序写等各种场景下的性能情况。
| 存储类型 | 单盘最大 IOPS(4KB随机读写) | 单盘最大吞吐量(MB/s) |
|---|---|---|
| SSD (SATA -> PCIe -> NVMe,命令队列数量和深度不同) | 2w - 100w | 260 - 4000 |
| HDD | 55 - 180 | 60 - 150 |
fio的测试方法:
# 随机读
fio -name=randread -direct=1 -iodepth=64 -rw=randread -ioengine=libaio -bs=4k -size=1G -numjobs=1 -runtime=1000 -group_reporting -filename=/dev/sdb
# 随机写
fio -name=randwrite -direct=1 -iodepth=64 -rw=randwrite -ioengine=libaio -bs=4k -size=1G -numjobs=1 -runtime=1000 -group_reporting -filename=/dev/sdb
# 顺序读
fio -name=read -direct=1 -iodepth=64 -rw=read -ioengine=libaio -bs=4k -size=1G -numjobs=1 -runtime=1000 -group_reporting -filename=/dev/sdb
# 顺序写
fio -name=write -direct=1 -iodepth=64 -rw=write -ioengine=libaio -bs=4k -size=1G -numjobs=1 -runtime=1000 -group_reporting -filename=/dev/sdb
对于性能指标,最大 IOPS 在 4KiB IO 大小下可得出测试结果,最大吞吐量在 256KiB IO 大小下可得出测试结果。具体测试方法请参见:如何衡量云硬盘的性能。
-
网络I/O模型优化(I/O多路复用),Linux 3.9以上使用
SO_REUSEPORT选项监听相同端口的多进程模型。 C10K -> C1000K,硬件的支持(万兆网卡,多队列网卡,CPU绑定)-> C10M,跳过内核协议栈的冗长路径,把网络包直接送到要处理的应用程序那里去。DPDK,是用户态网络的标准,它跳过内核协议栈,直接由用户态进程通过轮询的方式来处理网络接收。 -
更多可以参考:服务器常用性能瓶颈定位
More:
- Introduction to DPDK: Architecture and Principles
- The Secret To 10 Million Concurrent Connections -The Kernel Is The Problem, Not The Solution
性能优化案例
编译期计算
使用enum hack
#include <iostream>
template<int a, int b>
struct Add {
enum {
result = a + b
};
};
int main()
{
std::cout << Add<1, 2>::result << std::endl;
}
使用C++11的constexpr
#include <iostream>
template<typename T1, typename T2>
constexpr int add(T1 a, T2 b)
{
return a + b;
}
int main()
{
std::cout << add(1, 2) << std::endl;
}
数据对齐
配合现代编译器和CPU架构,可以让程序获得更好的性能。例如,CPU访问32位宽度的数据总线,就会期待数据是按照32位对齐,即4字节。这样CPU读取4字节的数据只需要对总线访问一次,但是如果要访问的数据并没有按照4字节对齐,那么CPU需要访问数据总线两次,运算速度自然就慢了。除了CPU之外,还有其他硬件也需要数据对齐,比如通过DMA访问硬盘,就要求内存必须是4K对齐的。
C++11之前的方法:使用offsetof宏获取member的偏移量,从而获取指定类型的对齐字节长度。
#include <iostream>
#define ALIGNOF(type, result) do {\
struct alignof_trick{ char c; type member; }; \
result = offsetof(alignof_trick, member); \
} while (0);
typedef void (*f)();
int main()
{
int len = 0;
ALIGNOF(char, len);
std::cout << len << std::endl; // 1
ALIGNOF(int, len);
std::cout << len << std::endl; // 4
ALIGNOF(short, len);
std::cout << len << std::endl; // 2
ALIGNOF(float, len);
std::cout << len << std::endl; // 4
ALIGNOF(double, len);
std::cout << len << std::endl; // 8
ALIGNOF(long long, len);
std::cout << len << std::endl; // 8
ALIGNOF(f, len);
std::cout << len << std::endl; // 8
}
更好的方法:
#include <iostream>
template<typename T>
struct alignof_trick
{
char c;
T member;
};
#define ALIGNOF(type) offsetof(alignof_trick<type>, member)
typedef void (*f)();
int main()
{
std::cout << ALIGNOF(char) << std::endl; // 1
std::cout << ALIGNOF(int) << std::endl; // 4
std::cout << ALIGNOF(short) << std::endl; // 2
std::cout << ALIGNOF(float) << std::endl; // 4
std::cout << ALIGNOF(double) << std::endl; // 8
std::cout << ALIGNOF(long long) << std::endl; // 8
std::cout << ALIGNOF(f) << std::endl; // 8
}
使用编译器的扩展功能:
#include <iostream>
// GCC
#define ALIGNOF(type) __alignof__(type)
typedef void (*f)();
int main()
{
std::cout << ALIGNOF(char) << std::endl; // 1
std::cout << ALIGNOF(int) << std::endl; // 4
std::cout << ALIGNOF(short) << std::endl; // 2
std::cout << ALIGNOF(float) << std::endl; // 4
std::cout << ALIGNOF(double) << std::endl; // 8
std::cout << ALIGNOF(long long) << std::endl; // 8
std::cout << ALIGNOF(f) << std::endl; // 8
}
设置数据对齐。
#include <iostream>
// GCC
#define ALIGNOF(type) __alignof__(type)
#define ALIGNAS(len) __attribute__((aligned(len)))
int main()
{
short x1;
ALIGNAS(8) short x2;
std::cout << ALIGNOF(x1) << std::endl; // 2
std::cout << ALIGNOF(x2) << std::endl; // 8
}
由于不同的编译器需要采用不同的扩展功能来控制类型的对齐字节长度,对可移植性不太友好,因此,C++11标准中新增了alignof和alignas两个关键字。
#include <iostream>
// GCC
#define ALIGNOF(type) alignof(type)
#define ALIGNAS(len) alignas(len)
int main()
{
short x1;
std::cout << ALIGNOF(short) << std::endl; // 2
std::cout << ALIGNOF(decltype(x1)) << std::endl; // 2
ALIGNAS(8) short x2;
std::cout << ALIGNOF(decltype(x2)) << std::endl; // 2 TODO
}
也提供了一些模板方法:例如,std::alignment_of
#include <iostream>
int main()
{
std::cout << std::alignment_of<int>::value << std::endl; // 4
std::cout << std::alignment_of<int>() << std::endl; // 4
}
性能测试对比:(10000000 * 10000 B = 100 GB)
| Case | Time (s) | Memory bandwidth (GB) |
|---|---|---|
| 1字节对齐 (memcpy) | 9.32968 | 10.7 |
| 32字节对齐 (memcpy) | 8.15827 | 12.3 |
| 1字节对齐 (rep movsb) | 2.45423 | 40.7 |
| 32字节对齐 (rep movsb) | 1.27497 | 78.4 |
REP MOVSD/MOVSQ is the universal solution that works relatively well on all Intel processors for large memory blocks of at least 4KB (no ERMSB required) if the destination is aligned by at least 64 bytes. REP MOVSD/MOVSQ works even better on newer processors, starting from Skylake. And, for Ice Lake or newer microarchitectures, it works perfectly for even very small strings of at least 64 bytes. refer: https://stackoverflow.com/questions/43343231/enhanced-rep-movsb-for-memcpy
- https://stackoverflow.com/questions/43343231/enhanced-rep-movsb-for-memcpy
- https://groups.google.com/g/gnu.gcc.help/c/-Bmlm_EG_fE
- https://www-ssl.intel.com/content/www/us/en/architecture-and-technology/64-ia-32-architectures-optimization-manual.html
- https://en.cppreference.com/w/cpp/memory/align
使用 tinymembench 测试内存的性能:
$ lscpu
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 1
On-line CPU(s) list: 0
Thread(s) per core: 1
Core(s) per socket: 1
Socket(s): 1
NUMA node(s): 1
Vendor ID: GenuineIntel
CPU family: 6
Model: 63
Model name: Intel(R) Xeon(R) CPU E5-26xx v3
Stepping: 2
CPU MHz: 2394.446
BogoMIPS: 4788.89
Hypervisor vendor: KVM
Virtualization type: full
L1d cache: 32K
L1i cache: 32K
L2 cache: 4096K
NUMA node0 CPU(s): 0
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ss ht syscall nx lm constant_tsc rep_good nopl cpuid pni pclmulqdq ssse3 fma cx16 pcid sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand hypervisor lahf_lm abm pti bmi1 avx2 bmi2 xsaveopt
$ ./tinymembench
tinymembench v0.4.9 (simple benchmark for memory throughput and latency)
==========================================================================
== Memory bandwidth tests ==
== ==
== Note 1: 1MB = 1000000 bytes ==
== Note 2: Results for 'copy' tests show how many bytes can be ==
== copied per second (adding together read and writen ==
== bytes would have provided twice higher numbers) ==
== Note 3: 2-pass copy means that we are using a small temporary buffer ==
== to first fetch data into it, and only then write it to the ==
== destination (source -> L1 cache, L1 cache -> destination) ==
== Note 4: If sample standard deviation exceeds 0.1%, it is shown in ==
== brackets ==
==========================================================================
C copy backwards : 4867.4 MB/s (2.8%)
C copy backwards (32 byte blocks) : 4834.6 MB/s (1.9%)
C copy backwards (64 byte blocks) : 4876.6 MB/s (1.2%)
C copy : 4832.9 MB/s (1.7%)
C copy prefetched (32 bytes step) : 4581.1 MB/s (1.8%)
C copy prefetched (64 bytes step) : 4522.8 MB/s (2.9%)
C 2-pass copy : 4372.2 MB/s (1.5%)
C 2-pass copy prefetched (32 bytes step) : 4465.1 MB/s (2.2%)
C 2-pass copy prefetched (64 bytes step) : 4431.3 MB/s (2.1%)
C fill : 8415.8 MB/s (3.1%)
C fill (shuffle within 16 byte blocks) : 8432.8 MB/s (3.2%)
C fill (shuffle within 32 byte blocks) : 8460.3 MB/s (3.4%)
C fill (shuffle within 64 byte blocks) : 8452.6 MB/s (2.9%)
---
standard memcpy : 9922.0 MB/s (3.0%)
standard memset : 8481.7 MB/s (5.3%)
---
MOVSB copy : 4314.7 MB/s (1.2%)
MOVSD copy : 4443.8 MB/s (1.0%)
SSE2 copy : 4783.6 MB/s (2.0%)
SSE2 nontemporal copy : 10040.4 MB/s (4.7%)
SSE2 copy prefetched (32 bytes step) : 4631.6 MB/s (1.7%)
SSE2 copy prefetched (64 bytes step) : 4610.8 MB/s (3.3%)
SSE2 nontemporal copy prefetched (32 bytes step) : 9247.9 MB/s (2.4%)
SSE2 nontemporal copy prefetched (64 bytes step) : 9515.9 MB/s (3.4%)
SSE2 2-pass copy : 4538.2 MB/s (1.6%)
SSE2 2-pass copy prefetched (32 bytes step) : 4361.0 MB/s (2.0%)
SSE2 2-pass copy prefetched (64 bytes step) : 4341.9 MB/s (2.3%)
SSE2 2-pass nontemporal copy : 3177.7 MB/s (1.9%)
SSE2 fill : 8482.4 MB/s (3.2%)
SSE2 nontemporal fill : 16543.7 MB/s (0.8%)
#include <iostream>
#include <memory>
#include <chrono>
static inline void *__movsb(void *d, const void *s, size_t n)
{
asm volatile ("rep movsb"
: "=D" (d),
"=S" (s),
"=c" (n)
: "0" (d),
"1" (s),
"2" (n)
: "memory");
return d;
}
int main(int argc, char *argv[])
{
constexpr int align_size = 32;
constexpr int alloc_size = 10001;
constexpr int buff_size = align_size + alloc_size;
char dst[buff_size] = {0};
char src[buff_size] = {0};
void *dst_ori_ptr = dst;
void *src_ori_ptr = src;
size_t dst_size = sizeof(dst);
size_t src_size = sizeof(src);
char *dst_ptr = static_cast<char *>(std::align(align_size, alloc_size, dst_ori_ptr, dst_size));
char *src_ptr = static_cast<char *>(std::align(align_size, alloc_size, src_ori_ptr, src_size));
if (argc == 2 && argv[1][0] == '1') {
++dst_ptr;
++src_ptr;
}
auto beg = std::chrono::high_resolution_clock::now();
for (int i = 0; i < 10000000; ++i) {
__movsb(dst_ptr, src_ptr, alloc_size - 1);
}
auto end = std::chrono::high_resolution_clock::now();
std::chrono::duration<double> diff = end - beg;
std::cout << "elapsed time: " << diff.count() << std::endl;
}
数字类型转换
问题:C++ performance challenge: integer to std::string conversion
- Before C++11:
std::stringstream,sprintf - After C++11:
std::to_string(C++11),std::to_chars(C++17),std::format(C++20),fmtlib
其中,std::format目前还没有编译器支持,此处使用fmtlib代替。
- https://en.cppreference.com/w/cpp/compiler_support
- https://stackoverflow.com/questions/65083544/format-no-such-file-or-directory
// {fmt} is an open-source formatting library providing a fast and safe alternative to C stdio and C++ iostreams.
// Format string syntax similar to Python's format.
// https://github.com/fmtlib/fmt
// https://gcc.godbolt.org/z/rz6fncKn7
#include <vector>
#include <fmt/ranges.h>
int main() {
std::string s1 = fmt::format("The answer is {}.", 42); // s1 == "The answer is 42."
std::string s2 = fmt::format("I'd rather be {1} than {0}.", "right", "happy"); // s2 == "I'd rather be happy than right."
std::vector<int> v = {1, 2, 3};
fmt::print("{}\n", v); // {1, 2, 3}
}
fmtlib的benchmark数据:
| Library | Method | Run Time, s |
|---|---|---|
| libc | printf | 1.04 |
| libc++ | std::ostream | 3.05 |
| fmt 6.1.1 | fmt::print | 0.75 (35% faster than printf) |
| Boost Format 1.67 | boost::format | 7.24 |
| Folly Format | folly::format | 2.23 |
其他测试对比:dtoa Benchmark
This benchmark evaluates the performance of conversion from double precision IEEE-754 floating point (double) to ASCII string. The function prototype is:
void dtoa(double value, char* buffer);
RandomDigit: Generates 1000 random double values, filtered out +/-inf and nan. Then convert them to limited precision (1 to 17 decimal digits in significand). Finally convert these numbers into ASCII. Each digit group is run for 100 times. The minimum time duration is measured for 10 trials.
| Function | Time (ns) | Speedup |
|---|---|---|
| ostringstream | 1,187.735 | 0.75x |
| ostrstream | 1,048.512 | 0.85x |
| sprint | 887.735 | 1.00x |
| fpconv | 119.024 | 7.46x |
| grisu2 | 101.082 | 8.78x |
| doubleconv (Google) | 84.359 | 10.52x |
| milo (Tencent) | 64.100 | 13.85x |
| ryu | 43.541 | 20.39x |
| fmt | 40.712 | 21.81x |
| null | 1.200 | 739.78x |
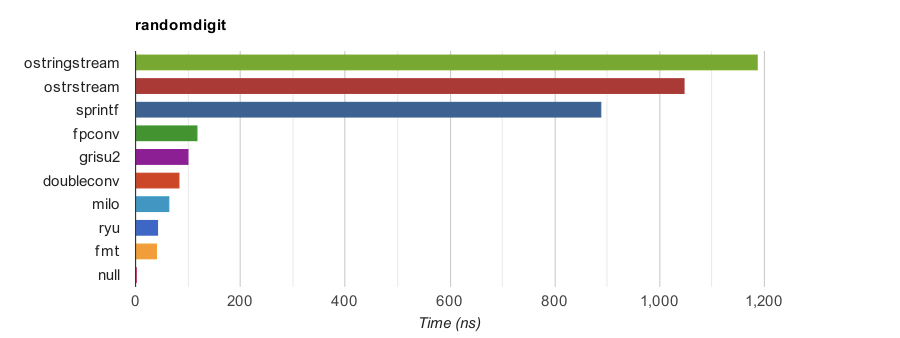
Note that the null implementation does nothing. It measures the overheads of looping and function call.
Why fast dtoa() functions is needed? They are a very common operations in writing data in text format. The standard way of sprintf(), std::stringstream, often provides poor performance. The author of this benchmark would optimize the sprintf implementation in RapidJSON. https://github.com/fmtlib/dtoa-benchmark/blob/master/src/milo/dtoa_milo.h
代码分析:
snprintf或者to_chars都需要调用者预先分配内存,如果需要将转换后的结果存储在std::string,还要多一次的拷贝。而fmt由内部实现内存分配管理,可以直接获取std::string的结果,不需要额外的拷贝,同时,实现上通过循环展开,查表,流水线友好(指令集并行),以及减少对除法指令运算等实现性能上的优化。
例如,如果转换的数字小于10000,正常展开需要每次计算%10或/10获取每一位数字,需要计算4次除法。而查表的方法,只需要计算一次%100和/100,然后通过查表得到结果,需要执行1次除法,减少了执行除法运算的次数。
// 1. std::to_chars
std::array<char, std::numeric_limits<int>::digits10 + 2> buffer;
auto result = std::to_chars(buffer.data(),
buffer.data() + buffer.size(), number);
if (result.ec == std::errc()) {
std::string result(buffer.data(), result.ptr); // copy the data into string
// use result ...
} else {
// handle the error ...
}
// 2. fmtlib
auto f = fmt::format_int(42);
// f.data() is the data, f.size() is the size
几种实现方案的测试对比:运行期计算,编译期计算,查表等方案。
#include <stdio.h>
#include <iostream>
#include <string>
#include <sstream>
#include <charconv>
#include <chrono>
// https://en.cppreference.com/w/cpp/compiler_support
// there are currently no compilers that support: Text formatting (P0645R10, std::format)
// #include <format>
// https://github.com/fmtlib/fmt
#define FMT_HEADER_ONLY
#include <fmt/core.h>
const int MAXCNT = 10000;
const int LEN = 8;
class ScopedTimer {
public:
ScopedTimer(const char* name): m_name(name), m_beg(std::chrono::high_resolution_clock::now()) { }
~ScopedTimer() {
auto end = std::chrono::high_resolution_clock::now();
auto dur = std::chrono::duration_cast<std::chrono::nanoseconds>(end - m_beg);
std::cout << m_name << " : " << dur.count() << " ns\n";
}
private:
const char* m_name;
std::chrono::time_point<std::chrono::high_resolution_clock> m_beg;
};
void sprintf_string()
{
ScopedTimer timer("sprintf_string");
for (auto i = 0; i < MAXCNT; ++i) {
thread_local char buf[LEN] = {0};
sprintf(buf, "%d", i);
thread_local std::string str;
str = buf;
}
}
void ss_string()
{
ScopedTimer timer("ss_string");
for (auto i = 0; i < MAXCNT; ++i) {
thread_local std::stringstream ss;
ss.clear();
ss << i;
thread_local std::string str;
str = ss.str();
}
}
void to_string()
{
ScopedTimer timer("to_string");
for (auto i = 0; i < MAXCNT; ++i) {
thread_local std::string str;
str = std::to_string(i);
}
}
void fmt_string()
{
ScopedTimer timer("fmt_string");
for (auto i = 0; i < MAXCNT; ++i) {
thread_local std::string str;
str = fmt::format("{}", i);
}
}
void fmt_int_string()
{
ScopedTimer timer("fmt_int_string");
for (auto i = 0; i < MAXCNT; ++i) {
auto fi = fmt::format_int(i);
// fi.data() is the data, fi.size() is the size
thread_local std::string str;
str = fi.data();
}
}
#if 0
void std_fmt_string()
{
ScopedTimer timer("std_fmt_string");
for (auto i = 0; i < MAXCNT; ++i) {
thread_local std::string str;
str = std::format("{}", i);
}
}
#endif
void tc_string()
{
ScopedTimer timer("tc_string");
for (auto i = 0; i < MAXCNT; ++i) {
thread_local char buf[LEN] = {0};
auto result = std::to_chars(buf, buf + LEN, i); // ignore err
thread_local std::string str;
str = std::string(buf, result.ptr);
}
}
char* uint2str(uint32_t n, char *buf)
{
static const char tbl[200] = {
'0','0','0','1','0','2','0','3','0','4','0','5','0','6','0','7','0','8','0','9',
'1','0','1','1','1','2','1','3','1','4','1','5','1','6','1','7','1','8','1','9',
'2','0','2','1','2','2','2','3','2','4','2','5','2','6','2','7','2','8','2','9',
'3','0','3','1','3','2','3','3','3','4','3','5','3','6','3','7','3','8','3','9',
'4','0','4','1','4','2','4','3','4','4','4','5','4','6','4','7','4','8','4','9',
'5','0','5','1','5','2','5','3','5','4','5','5','5','6','5','7','5','8','5','9',
'6','0','6','1','6','2','6','3','6','4','6','5','6','6','6','7','6','8','6','9',
'7','0','7','1','7','2','7','3','7','4','7','5','7','6','7','7','7','8','7','9',
'8','0','8','1','8','2','8','3','8','4','8','5','8','6','8','7','8','8','8','9',
'9','0','9','1','9','2','9','3','9','4','9','5','9','6','9','7','9','8','9','9'
};
char *p = buf;
if (n < 10000) {
uint32_t a = (n / 100) << 1;
uint32_t b = (n % 100) << 1;
if (n >= 1000) { *p++ = tbl[a]; }
if (n >= 100) { *p++ = tbl[a + 1]; }
if (n >= 10) { *p++ = tbl[b]; }
*p++ = tbl[b + 1];
}
else if (n < 100000000) {
uint32_t w = (n / 10000);
uint32_t x = (n % 10000);
uint32_t a = (w / 100) << 1;
uint32_t b = (w % 100) << 1;
uint32_t c = (x / 100) << 1;
uint32_t d = (x % 100) << 1;
if (n >= 10000000) { *p++ = tbl[a]; }
if (n >= 1000000) { *p++ = tbl[a + 1]; }
if (n >= 100000) { *p++ = tbl[b]; }
*p++ = tbl[b + 1];
*p++ = tbl[c];
*p++ = tbl[c + 1];
*p++ = tbl[d];
*p++ = tbl[d + 1];
}
else {
uint32_t m = n / 100000000;
n %= 100000000;
if (m >= 10) {
uint32_t a = m << 1;
*p++ = tbl[a];
*p++ = tbl[a + 1];
}
else {
*p++ = '0' + (char)m;
}
uint32_t w = (n / 10000);
uint32_t x = (n % 10000);
uint32_t a = (w / 100) << 1;
uint32_t b = (w % 100) << 1;
uint32_t c = (x / 100) << 1;
uint32_t d = (x % 100) << 1;
*p++ = tbl[a];
*p++ = tbl[a + 1];
*p++ = tbl[b];
*p++ = tbl[b + 1];
*p++ = tbl[c];
*p++ = tbl[c + 1];
*p++ = tbl[d];
*p++ = tbl[d + 1];
}
return p;
}
void table_string()
{
ScopedTimer timer("table_string");
for (auto i = 0; i < MAXCNT; ++i) {
thread_local char buf[16];
char *p = uint2str(i, buf);
thread_local std::string str;
str.assign(buf, p - buf);
}
}
void compilea_string()
{
#define STR(x) #x
#define TOSTRING(x) STR(x)
ScopedTimer timer("compilea_string");
for (auto i = 0; i < MAXCNT; ++i) {
thread_local std::string str;
str = TOSTRING(10000);
}
#undef TOSTRING
#undef STR
}
namespace detail
{
template<uint8_t... digits> struct positive_to_chars {
static const char value[];
static constexpr size_t size = sizeof...(digits);
};
template<uint8_t... digits> const char positive_to_chars<digits...>::value[] = {('0' + digits)..., 0};
template<uint8_t... digits> struct negative_to_chars {
static const char value[];
};
template<uint8_t... digits> const char negative_to_chars<digits...>::value[] = {'-', ('0' + digits)..., 0};
template<bool neg, uint8_t... digits>
struct to_chars : positive_to_chars<digits...> {};
template<uint8_t... digits>
struct to_chars<true, digits...> : negative_to_chars<digits...> {};
// 对 num 每位进行展开,例如,num = 123 则展开为 explode<neg, 0, 1, 2, 3>
template<bool neg, uintmax_t rem, uint8_t... digits>
struct explode : explode<neg, rem / 10, rem % 10, digits...> {};
// 展开终止
template<bool neg, uint8_t... digits>
struct explode<neg, 0, digits...> : to_chars<neg, digits...> {};
template<typename T>
constexpr uintmax_t cabs(T num) {
return (num < 0) ? -num : num;
}
}
template<typename T, T num>
struct string_from : ::detail::explode<num < 0, ::detail::cabs(num)> {};
void compileb_string()
{
ScopedTimer timer("compileb_string");
for (auto i = 0; i < MAXCNT; ++i) {
thread_local std::string str;
str = string_from<unsigned, 10000>::value;
}
}
int main()
{
sprintf_string();
ss_string();
to_string();
fmt_string();
fmt_int_string();
//std_fmt_string();
tc_string();
table_string();
compilea_string();
compileb_string();
}
测试结果:
| Method | Time (ns) | Speedup |
|---|---|---|
| std::stringstream | 8389529 | 1x |
| sprintf | 1609070 | 4.2x |
| std::to_string(C++11) | 195945 | 41.8x |
| std::to_chars(C++17) | 238524 | 34.1x |
| fmt::format | 355638 | 22.5x |
| fmt::format_int | 256275 | 31.7x |
| std::format(C++20) | N/A | N/A |
| table_string | 182740 | 44.9x |
| compilea_string | 144676 | 56.9x |
| compileb_string | 133585 | 61.8x |
更详细的测试结果:
- A collection of formatting benchmarks
- Converting a hundred million integers to strings per second
- Facebook Tech Talk by Andrei Alexandrescu: Three Optimization Tips For C++
分支预测(Branching)

GCC内置宏__builtin_expect提供了分支预测(Branch predictor)的能力,从而有助于CPU执行Instruction pipelining优化,其中,exp 为 integral expressions,__builtin_expect 为 true 的默认概率为 90%(依赖 -O2,而 -O0 不会优化)。
long __builtin_expect (long exp, long c) long __builtin_expect_with_probability(long exp, long c, double probability)
四阶段的 Instruction pipeline(fetch, decode, execute and write-back),其中,每个彩色格子表示相互独立的指令。
Four stages pipeline: fetch, decode, execute and write-back. The top gray box is the list of instructions waiting to be executed, the bottom gray box is the list of instructions that have had their execution completed, and the middle white box is the pipeline.
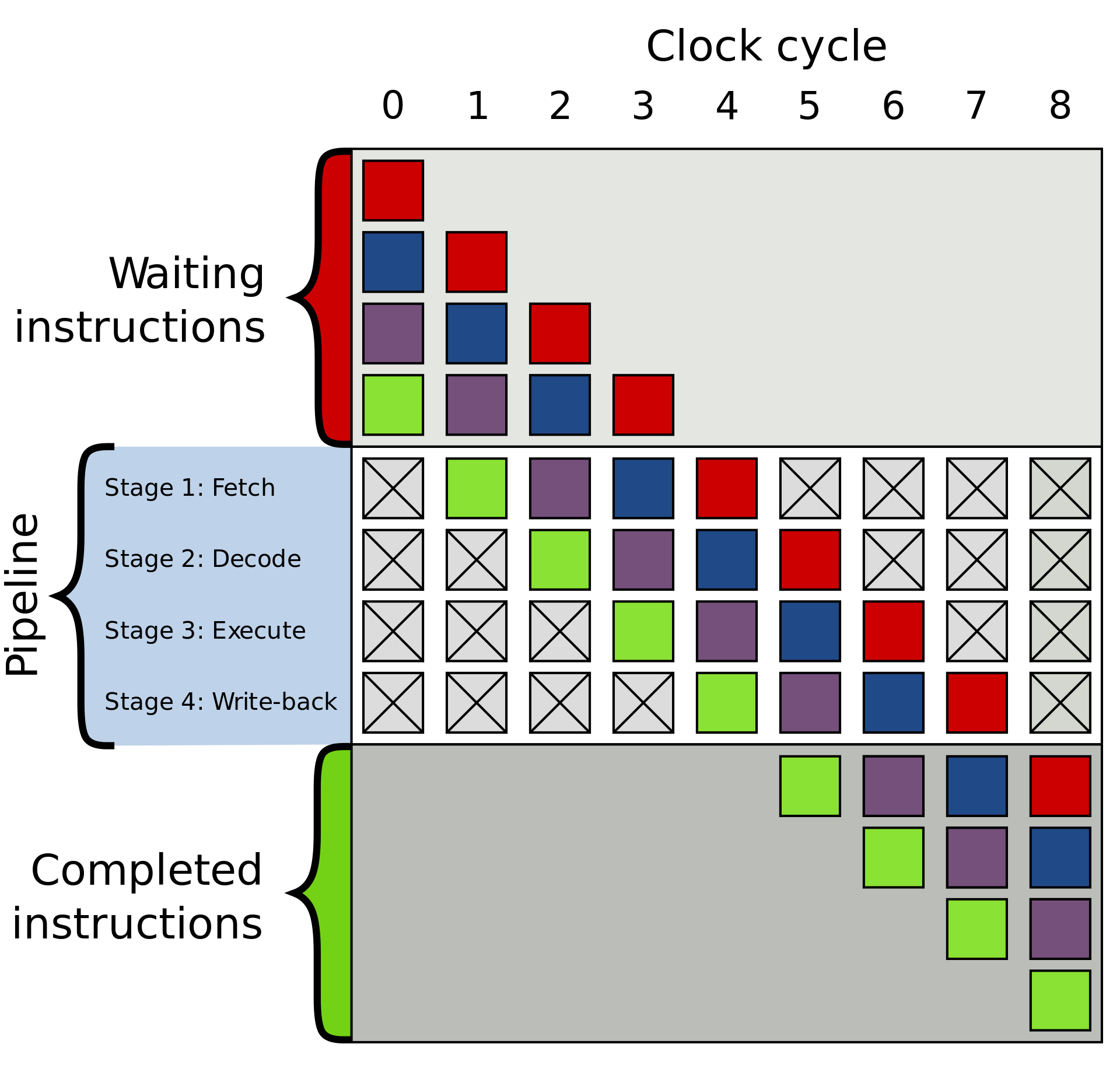
C++20支持了C++ attribute: likely, unlikely 分支预测的属性设置,帮助编译器实现优化。
if (a > b) [[likely]] {
do_something();
} else {
do_other();
}
switch (x) {
case 1:
f();
break;
case 2:
[[likely]] g();
break;
default:
h();
}
例如:
// long __builtin_expect (long exp, long c)
// we do not expect to call foo, since we expect x to be zero
if (__builtin_expect (x, 0)) {
foo();
}
if (__builtin_expect (ptr != NULL, 1)) {
foo (*ptr);
}
为了方便使用,Linux内核代码(include/linux/compiler.h)定义了两个接口。
// expect x is true
# define likely(x) __builtin_expect(!!(x), 1)
// expect x is false
# define unlikely(x) __builtin_expect(!!(x), 0)
解释:Why use !!(x) ? If foo is not of type bool, then !!foo will be. So !!foo can be 1 or 0.
对比测试:环境 x86-64 gcc 8.4.0,使用 O2 编译,查看两种汇编实现。
程序1:
#include <cstdio>
#include <iostream>
#include <unistd.h>
#include <ctime>
__attribute__ ((noinline)) int func(int a)
{
if (a) {
usleep(1000); // 1ms
} else {
a = time(NULL);
}
return 0;
}
int main()
{
auto a = std::rand();
func(a);
return 0;
}
0000000000000710 <main>:
710: 55 push %rbp
711: 53 push %rbx
712: bb e8 03 00 00 mov $0x3e8,%ebx
717: 48 83 ec 08 sub $0x8,%rsp
71b: e8 90 ff ff ff callq 6b0 <rand@plt>
720: 89 c5 mov %eax,%ebp
722: 66 0f 1f 44 00 00 nopw 0x0(%rax,%rax,1)
728: 89 ef mov %ebp,%edi
72a: e8 31 01 00 00 callq 860 <_Z4funci>
72f: 83 eb 01 sub $0x1,%ebx
732: 75 f4 jne 728 <main+0x18>
734: 48 83 c4 08 add $0x8,%rsp
738: 31 c0 xor %eax,%eax
73a: 5b pop %rbx
73b: 5d pop %rbp
73c: c3 retq
73d: 0f 1f 00 nopl (%rax)
0000000000000860 <_Z4funci>:
860: 48 83 ec 08 sub $0x8,%rsp
864: 85 ff test %edi,%edi
866: 74 18 je 880 <_Z4funci+0x20>
868: bf e8 03 00 00 mov $0x3e8,%edi
86d: e8 6e fe ff ff callq 6e0 <usleep@plt>
872: 31 c0 xor %eax,%eax
874: 48 83 c4 08 add $0x8,%rsp
878: c3 retq
879: 0f 1f 80 00 00 00 00 nopl 0x0(%rax)
880: 31 ff xor %edi,%edi
882: e8 49 fe ff ff callq 6d0 <time@plt>
887: 31 c0 xor %eax,%eax
889: 48 83 c4 08 add $0x8,%rsp
88d: c3 retq
88e: 66 90 xchg %ax,%ax
程序2:
#define LIKELY(x) __builtin_expect(!!(x), 1)
#define UNLIKELY(x) __builtin_expect(!!(x), 0)
__attribute__ ((noinline)) int func(int a)
{
if (UNLIKELY(a)) {
usleep(1000); // 1ms
} else {
a = time(NULL);
}
return 0;
}
0000000000000850 <_Z4funci>:
850: 48 83 ec 08 sub $0x8,%rsp
854: 85 ff test %edi,%edi
856: 75 18 jne 870 <_Z4funci+0x20>
858: 31 ff xor %edi,%edi
85a: e8 71 fe ff ff callq 6d0 <time@plt>
85f: 31 c0 xor %eax,%eax
861: 48 83 c4 08 add $0x8,%rsp
865: c3 retq
866: 66 2e 0f 1f 84 00 00 nopw %cs:0x0(%rax,%rax,1)
86d: 00 00 00
870: bf e8 03 00 00 mov $0x3e8,%edi
875: e8 66 fe ff ff callq 6e0 <usleep@plt>
87a: eb e3 jmp 85f <_Z4funci+0xf>
87c: 0f 1f 40 00 nopl 0x0(%rax)
/* builtin_expect_test.c */
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
#include <string.h>
#define BSIZE 1000000
#ifndef BINCR
#define BINCR 1
#endif
#if defined(EXPECT_RESULT) && defined(DONT_EXPECT)
#error "Specifying both EXPECT_RESULT and DONT_EXPECT makes no sense"
#endif
/* We add some seemingly unneeded complexity to the code, simply to
make the opimizer's task tricky enough that it won't optimize away
the effect of __builtin_expect(). In this particular program, all
of the following are needed:
* Calling an *non-inline* function inside the loop in main().
* Looping over an array in main() (rather than checking a
single variable).
* Dynamically allocating the array with calloc(), rather than
declaring an array and initializing with memset().
* Acting on two different variables (m1, m2) in each branch
of the 'if' statement in main() (if the two branches after
the 'if' execute the same code, gcc is clever enough to
recognize this and optimize the 'if' away).
* Printing the resulting values of the variables modified in
the loop (otherwise gcc may optimize away the entire loop
inside main()).
Compile with at least -O2 (on x86) to see a difference in
performance due to __builtin_expect().
*/
static __attribute__ ((noinline)) int
f(int a)
{
return a;
}
int
main(int argc, char *argv[])
{
int *p;
int j, k, m1, m2, nloops;
if (argc != 2 || strcmp(argv[1], "--help") == 0) {
fprintf(stderr, "Usage: %s num-loops\n", argv[0]);
exit(EXIT_FAILURE);
}
m1 = m2 = 0;
nloops = atoi(argv[1]);
/* calloc() allocates an array and zeros its contents */
p = calloc(BSIZE, sizeof(int));
if (p == NULL) {
perror("calloc");
exit(EXIT_FAILURE);
}
#if defined(BREAK_STEP) && BREAK_STEP > 0
/* This provides us with a way to inject some values into the
array that differ from our expected test value, in order
to get an idea of how how much the __builtin_expect()
optimization is negatively affected by unexpected values. */
for (k = 0, j = 0; j < BSIZE; j += BREAK_STEP) {
p[j] += BINCR;
k++;
}
printf("Adjusted %d items by %d\n", k, BINCR);
#endif
for (j = 0; j < nloops; j++) {
for (k = 0; k < BSIZE; k++) {
#ifdef DONT_EXPECT
if (p[k]) {
#else
if (__builtin_expect(p[k], EXPECT_RESULT)) {
#endif
m1 = f(++m1);
} else {
m2 = f(++m2);
}
}
}
printf("%d, %d\n", m1, m2);
exit(EXIT_SUCCESS);
}
GCC官方文档 给出了使用__builtin_expect()的相关建议:
In general, you should prefer to use actual profile feedback for this (-fprofile-arcs), as programmers are notoriously bad at predicting how their programs actually perform. However, there are applications in which this data is hard to collect.
That’s good concise advice. To put things another way, the only time you should use
__builtin_expect()is when you can’t use compiler-assisted runtime optimization and you are certain that your predicted code path is very (very) likely to be the one that will be taken.
通过选项让编译器帮助实现优化:
Building the programming now involves two steps: a profiling phase and an optimized compile.
-fprofile-generate Enable options usually used for instrumenting application to produce profile useful for later recompilation with profile feedback based optimization. You must use -fprofile-generate both when compiling and when linking your program. To optimize the program based on the collected profile information, use -fprofile-use. Enable profile feedback-directed optimizations, and the following optimizations, many of which are generally profitable only with profile feedback available:
-fbranch-probabilities -fprofile-values
-funroll-loops -fpeel-loops -ftracer -fvpt
-finline-functions -fipa-cp -fipa-cp-clone -fipa-bit-cp
-fpredictive-commoning -fsplit-loops -funswitch-loops
-fgcse-after-reload -ftree-loop-vectorize -ftree-slp-vectorize
-fvect-cost-model=dynamic -ftree-loop-distribute-patterns
-fprofile-reorder-functions
# profiling phase
g++ -O2 -fprofile-generate a.cc -o a.prof
# optimized compile
g++ -O2 -fprofile-use a.cc -o a.opt
More:
- How much do __builtin_expect(), likely(), and unlikely() improve performance?
- What is the advantage of GCC’s __builtin_expect in if else statements?
- https://gcc.gnu.org/onlinedocs/gcc-10.1.0/gcc/Instrumentation-Options.html
- https://gcc.gnu.org/onlinedocs/gcc-10.1.0/gcc/Optimize-Options.html#Optimize-Options
系统调用优化
在Linux中发起一次系统调用是比较昂贵的操作(参考上文需要 1500 CPU clocks cycles),而一般游戏后台服务需要频繁地获取系统时间,通常情况下,gettimeofday的执行性能可以达到每秒上百万次,但是如果想获得更高的性能,就必须对现有的系统调用进行优化。在2.6的内核里面,实现了一种vsyscall的机制,允许应用程序不需要进入内核就可以获得内核的数据(比如系统时间),但是这种机制只有在x86_64的Linux下才受到支持(On some architectures, an implementation of gettimeofday() is provided in the vdso(7)),因此,需要一种通用的优化方案。
Linux支持的时钟设备包括六种:
- RTC(Real-time Clock)
- PIT(Programmable Interval Timer)
- TSC(Time Stamp Counter)
- APIC Local Timer
- HPET(High Precision Event Timer)
- PMTIMER(Power Management Timer)
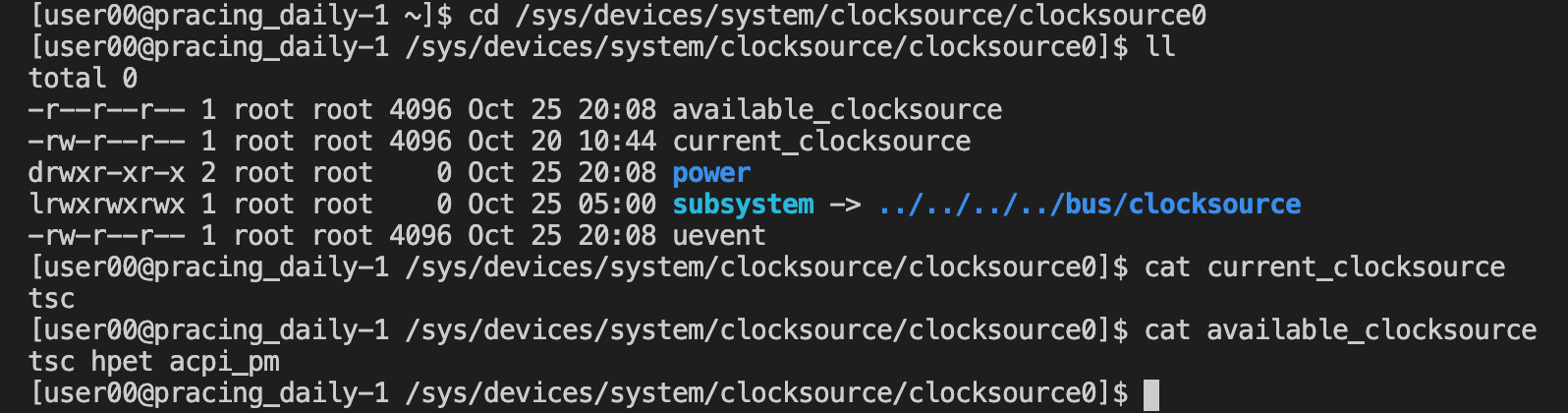
问题程序:
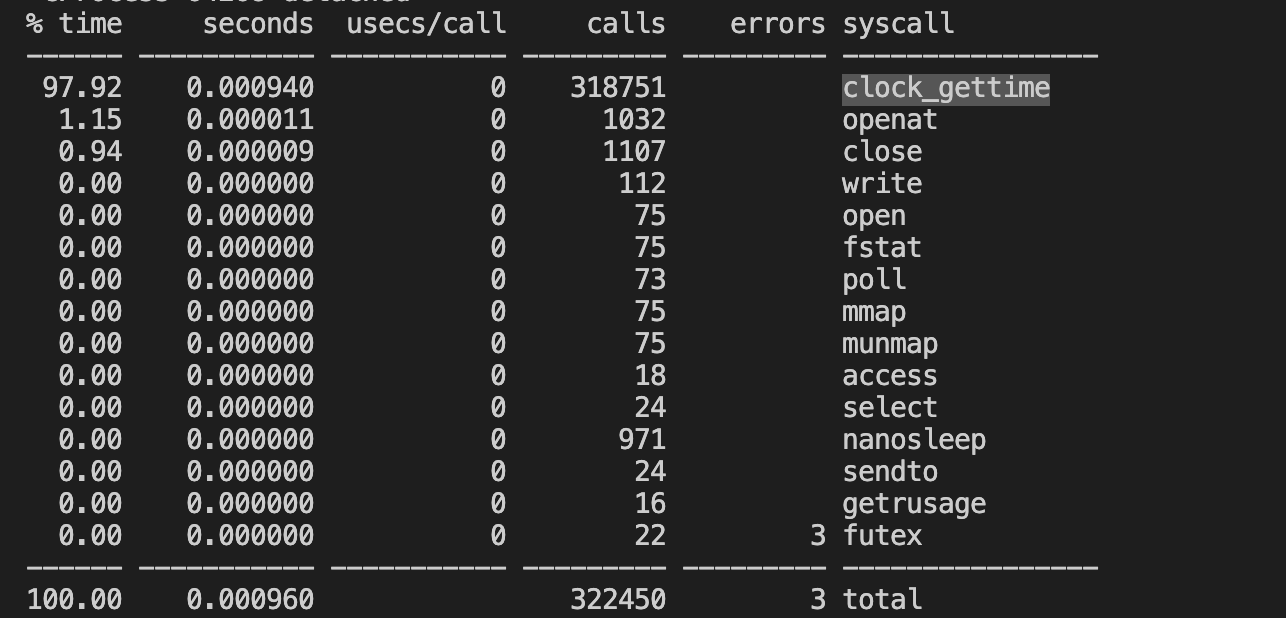
优化方案:
对于gettimeofday的操作可以分解为三步:1. 取得墙上时间xtime,2. 访问时间设备,取得上次时间中断到当前的时间偏移,3. 根据这个时间偏移计算出当前的精确时间。可见,gettimeofday的精度和性能由具体的时间设备所决定。优化思路,在用户态下对gettimeofday进行优化,在满足精度的情况下,减少调用频率。通过使用rdtsc(Read Time-Stamp Counter)指令访问TSC寄存器(Time Stamp Counter)可以获得两次调用的时延。

Description:
Reads the current value of the processor’s time-stamp counter (a 64-bit MSR) into the EDX:EAX registers. The EDX register is loaded with the high-order 32 bits of the MSR and the EAX register is loaded with the low-order 32 bits. On processors that support the Intel 64 architecture, the high-order 32 bits of each of RAX and RDX are cleared.
The processor monotonically increments the time-stamp counter MSR every clock cycle and resets it to 0 whenever the processor is reset.
refer: https://www.intel.com/content/dam/www/public/us/en/documents/manuals/64-ia-32-architectures-software-developer-vol-2b-manual.pdf
下面的宏定义用于读取TSC的值:
#ifdef __x86_64__
#define RDTSC() ({ unsigned int tickl, tickh; __asm__ __volatile__("rdtsc":"=a"(tickl),"=d"(tickh)); ((unsigned long long)tickh << 32)|tickl; })
#else
#define RDTSC() ({ unsigned long long tick; __asm__ __volatile__( "rdtsc" : "=A"(tick)); tick; })
#endif
32位和64位的区别:
The a and d registers. This class is used for instructions that return double word(2 * 32) results in the ax:dx register pair. Single word values will be allocated either in ax or dx. For example on i386 the following implements rdtsc:
unsigned long long rdtsc (void)
{
unsigned long long tick;
__asm__ __volatile__("rdtsc":"=A"(tick));
return tick;
}
This is not correct on x86-64 as it would allocate tick in either ax or dx. You have to use the following variant instead:
unsigned long long rdtsc (void)
{
unsigned int tickl, tickh;
__asm__ __volatile__("rdtsc":"=a"(tickl),"=d"(tickh));
return ((unsigned long long)tickh << 32)|tickl;
}
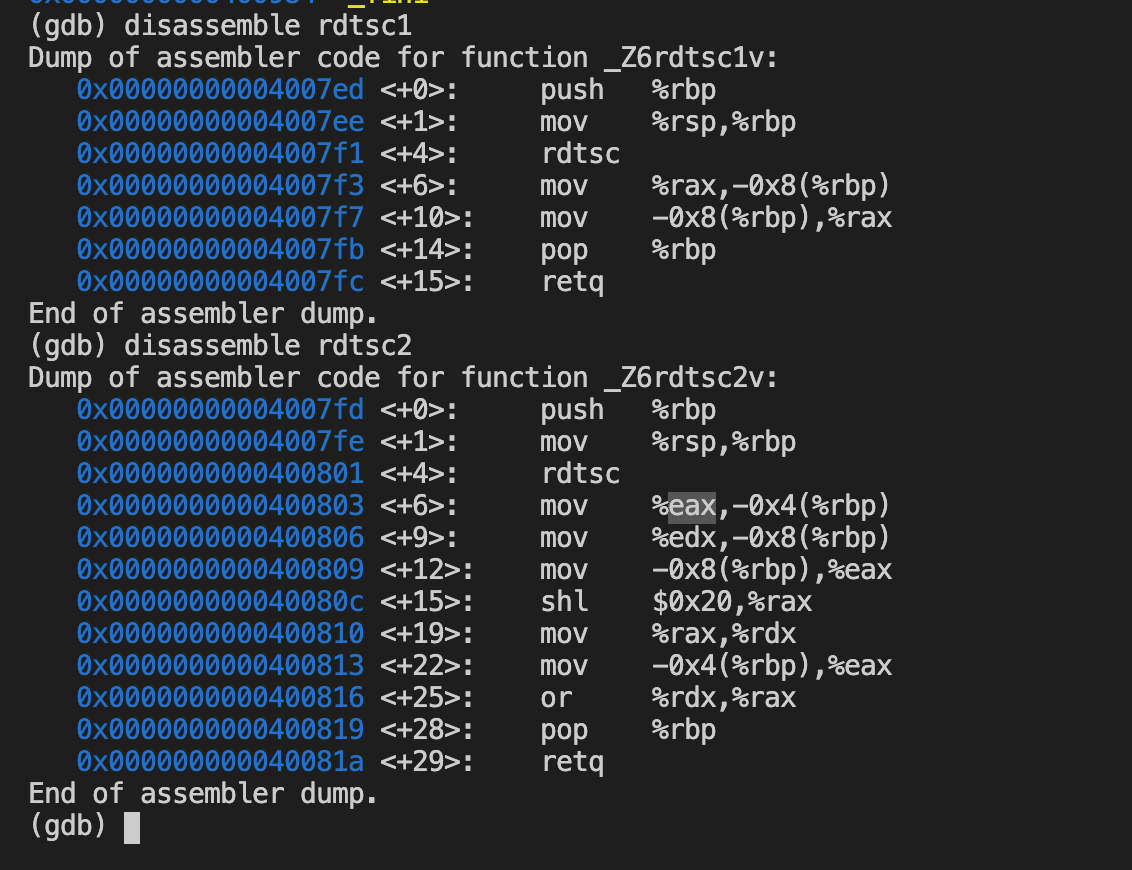
TSC是一个64位的寄存器,相当与一个计数器(It counts the number of CPU cycles since its reset),但我们所需要的是时间,而不是计数。由于TSC的值是每个CPU时钟周期增加1,所以只要知道了CPU的时间频率,就可以将这个值换算成时间。因为对精度的要求并不是很高(微秒级),我们只需要获得以兆为单位的大约值就可以了。下面的函数获得CPU的频率:
static inline int getcpuspeed_mhz(unsigned int wait_us)
{
uint64_t tsc1, tsc2;
struct timespec t;
t.tv_sec = 0;
t.tv_nsec = wait_us * 1000;
tsc1 = RDTSC();
// If sleep failed, result is unexpected, the caller should retry
if (nanosleep(&t, NULL)) {
return -1;
}
tsc2 = RDTSC();
return (tsc2 - tsc1) / (wait_us);
}
CPU频率和TSC的换算公式如下:知道了TSC的偏移和CPU频率,就可以获得时间偏移了。
cpu_speed_mhz = tsc_offset / time_offset_us
对于 Windows 比较简单,直接提供了对应的指令__rdtsc。
// rdtsc.cpp
// processor: x86, x64
#include <stdio.h>
#include <intrin.h>
#pragma intrinsic(__rdtsc)
int main()
{
unsigned __int64 i;
i = __rdtsc();
printf_s("%I64d ticks\n", i);
}
测试程序:
#include <cstdio>
#include <time.h>
#include <sys/time.h>
#include <ctime>
#include <chrono>
int main()
{
struct timespec tp;
struct timeval tv;
int i = 0;
int j = 0;
for (i = 0; i < 1000000; ++i)
{
// vdso
gettimeofday(&tv, NULL);
j += tv.tv_usec % 2;
// https://linux.die.net/man/3/clock_gettime
// vdso
//clock_gettime(CLOCK_REALTIME, &tp);
//clock_gettime(CLOCK_MONOTONIC, &tp);
//clock_gettime(CLOCK_REALTIME_COARSE, &tp);
//clock_gettime(CLOCK_MONOTONIC_COARSE, &tp);
// syscall
//clock_gettime(CLOCK_THREAD_CPUTIME_ID, &tp);
//clock_gettime(CLOCK_PROCESS_CPUTIME_ID, &tp);
// vdso
//auto t = std::time(0);
//printf("%u\n", t);
// syscall
//auto t = std::chrono::system_clock::now().time_since_epoch() / std::chrono::seconds(1);
//std::chrono::system_clock::now();
std::chrono::steady_clock::now();
j += tp.tv_sec % 2;
}
return 0;
}
系统调用优化,通过vsyscall和vdso(virtual dynamic shared object)两种机制用来加速系统调用的处理。
vsyscall或virtual system call是第一种也是最古老的一种用于加快系统调用的机制。vsyscall的工作原则其实十分简单。Linux 内核在用户空间映射一个包含一些变量及一些系统调用的实现的内存页。因此, 这些系统调用将在用户空间下执行,这意味着将不发生上下文切换。
vsyscallis an obsolete concept and replaced by thevDSOorvirtual dynamic shared object. The main difference between thevsyscallandvDSOmechanisms is thatvDSOmaps memory pages into each process in a shared object form, butvsyscallis static in memory and has the same address every time. For the x86_64 architecture it is calledlinux-vdso.so.1. All userspace applications linked with this shared library via theglibc.
$ cat /proc/1/maps | grep vsyscall
ffffffffff600000-ffffffffff601000 r-xp 00000000 00:00 0 [vsyscall]
$ ldd /bin/uname
linux-vdso.so.1 => (0x00007ffdbabc5000)
/$LIB/libonion.so => /lib64/libonion.so (0x00007f846a10c000)
libc.so.6 => /lib64/libc.so.6 (0x00007f8469c25000)
libdl.so.2 => /lib64/libdl.so.2 (0x00007f8469a21000)
/lib64/ld-linux-x86-64.so.2 (0x00007f8469ff3000)
$ sudo cat /proc/1/maps | grep vdso
7fff93f0a000-7fff93f0c000 r-xp 00000000 00:00 0 [vdso]
有些情况可能不支持vdso:
- 有些时钟源,可能不支持vdso。例如,Two frequently used system calls are ~77% slower on AWS EC2
The two system calls listed cannot use the vDSO as they normally would on any other system. This is because the virtualized clock source on xen (and some kvm configurations) do not support reading the time in userland via the vDSO.
-
有些系统调用的参数选项,可能不支持vdso,比如
clock_gettime的第一个参数。当为CLOCK_REALTIME,CLOCK_MONOTONIC,CLOCK_REALTIME_COARSE,CLOCK_MONOTONIC_COARSE时会使用vdso,而其他选项时则不会。具体参数可见man 2 clock_gettime -
gcc 4.8版本在调用std::chrono::system_clock::now会bypass vdso走system call,优化方法:升级到gcc 7或者改换其他用法。bug参考可见:Bug 59177 - steady_clock::now() and system_clock::now do not use the vdso (and are therefore very slow)
编译器优化
-pg
在 GCC 编译器中,-pg 选项用于启用生成的可执行文件的 gprof 性能分析。当使用 -pg 选项编译和链接程序时,编译器会在程序的每个函数入口和出口处插入额外的代码。这些插入的代码用于收集函数调用的计数和执行时间信息。
当程序运行完成后,它会生成一个名为 gmon.out 的分析数据文件。然后,可以使用 gprof 工具分析此文件以获取程序的性能概况。这有助于识别程序中的瓶颈和优化代码。
要使用 -pg 选项,请在编译和链接时都加上 -pg,例如:
gcc -pg -o my_program my_program.c
然后运行程序:
./my_program
这将生成 gmon.out 文件。接下来,使用 gprof 分析性能数据:
gprof my_program gmon.out > analysis.txt
现在,可以查看 analysis.txt 文件以获取程序的性能概况。
优化代码案例
字节序反转
因为 ntohl 不支持 64位,而 be64toh 支持 64位。
// htonl, htons, ntohl, ntohs - convert values between host and network byte order
#include <arpa/inet.h>
uint32_t htonl(uint32_t hostlong);
uint16_t htons(uint16_t hostshort);
uint32_t ntohl(uint32_t netlong);
uint16_t ntohs(uint16_t netshort);
// htobe16, htole16, be16toh, le16toh, htobe32, htole32, be32toh, le32toh, htobe64, htole64, be64toh, le64toh - convert values between host and big-/little-endian byte order
#define _BSD_SOURCE /* See feature_test_macros(7) */
#include <endian.h>
uint16_t htobe16(uint16_t host_16bits);
uint16_t htole16(uint16_t host_16bits);
uint16_t be16toh(uint16_t big_endian_16bits);
uint16_t le16toh(uint16_t little_endian_16bits);
uint32_t htobe32(uint32_t host_32bits);
uint32_t htole32(uint32_t host_32bits);
uint32_t be32toh(uint32_t big_endian_32bits);
uint32_t le32toh(uint32_t little_endian_32bits);
uint64_t htobe64(uint64_t host_64bits);
uint64_t htole64(uint64_t host_64bits);
uint64_t be64toh(uint64_t big_endian_64bits);
uint64_t le64toh(uint64_t little_endian_64bits);
下面的 ByteOrderSwap64 是造轮子的实现方式。
inline uint64 ByteOrderSwap64(uint64 x)
{
return ((((x)&0xff00000000000000ull) >> 56) | (((x)&0x00ff000000000000ull) >> 40) | (((x)&0x0000ff0000000000ull) >> 24) |
(((x)&0x000000ff00000000ull) >> 8) | (((x)&0x00000000ff000000ull) << 8) | (((x)&0x0000000000ff0000ull) << 24) |
(((x)&0x000000000000ff00ull) << 40) | (((x)&0x00000000000000ffull) << 56));
}
#if !defined(__BYTE_ORDER) || !defined(__BIG_ENDIAN) || !defined(__LITTLE_ENDIAN)
# error "No define __BYTE_ORDER or __BIG_ENDIAN or __LITTLE_ENDIAN"
#endif
#if __BYTE_ORDER == __BIG_ENDIAN
# define ntoh64(x) (x)
# define hton64(x) (x)
#elif __BYTE_ORDER == __LITTLE_ENDIAN
# define ntoh64(x) ByteOrderSwap64(x)
# define hton64(x) ByteOrderSwap64(x)
#else
# error "__BYTE_ORDER != __BIG_ENDIAN && __BYTE_ORDER != __LITTLE_ENDIAN"
#endif
这段代码定义了一个名为 ByteOrderSwap64 的内联函数,用于将一个 64 位无符号整数(uint64 类型)的字节顺序进行反转。这个函数在处理不同字节序的数据时非常有用,例如在网络编程或文件 I/O 中,不同系统可能使用不同的字节序来表示数据。通过使用这个函数,我们可以确保数据在不同系统之间正确地传输和解析。
影响性能的案例
C++ Exceptions
These days, C++ exceptions are said to be zero-cost until thrown. Whether it is really zero – is still not 100% clear (IMO it is even unclear whether such a question can be asked at all), but it is certainly very close.
However, these “zero-cost until thrown” implementations come at the cost of a huge pile of work which needs to be done whenever an exception is thrown. Everybody agrees that the cost of exception thrown is huge, however (as usual) experimental data is scarce. Still, an experiment by [Ongaro] gives us a ballpark number of around 5000 CPU cycles (sic!). Moreover, in more complicated cases, I would expect it to take even more.
在现代 C++ 编译器中,异常处理通常被称为“零开销,直到抛出异常”。这意味着在正常执行程序时,异常处理机制几乎不会对性能产生影响。虽然这里提到“零开销”这个说法可能并不是 100% 准确,但在没有抛出异常的情况下,异常处理对性能的影响确实非常小。
然而,这种“零开销,直到抛出异常”的实现方式在异常实际抛出时需要做大量的工作,这会导致性能开销变得很大。尽管关于异常抛出的具体开销的实验数据很少,但根据 Ongaro 的实验,抛出异常的开销大约为 5000 个 CPU 周期。在更复杂的情况下,这个开销可能会更大。
C++ 异常处理机制在没有抛出异常时对性能的影响非常小,但在异常实际发生时,处理异常可能会导致较大的性能开销。在设计程序时,可以将异常处理用于处理真正的异常情况,而不是作为常规的程序控制流程。
refer:
io_uring (异步 IO)
io_uring 不是线程安全的。
From Efficient IO with io_uring:

io_uring 作为 Linux 内核 v5.1 推出的新功能,一开始就被寄予厚望。在设计之初,开发者就希望 io_uring 至少有这些特质:
- 用法简单。一切用户层可见的接口都应以此为主要目标。
- 可扩展。虽然作者的背景主要是与存储相关的,但希望这套接口不仅仅是面向块设备能用。
- 功能丰富。Linux AIO 只满足了一部分应用程序的需要。不想再造一套只覆盖部分功能,或者需要应用重复造轮子(比如 IO 线程池)的接口。
- 高效。尽管存储 IO 大多都是基于块的,因而大小多在 512 或 4096 字节,但这些大小时候的效率还是对某些应用至关重要的。此外,一些请求甚至可能不携带数据有效载荷。新接口得在每次请求的开销上精打细算。
- 可伸缩。 尽管效率和低时延很重要,但在峰值端提供最佳性能也很关键。特别是在存储方面,我们一直在努力提供一个可扩展的基础设施。新接口应该允许我们将这种可扩展性一直暴露在应用程序中。
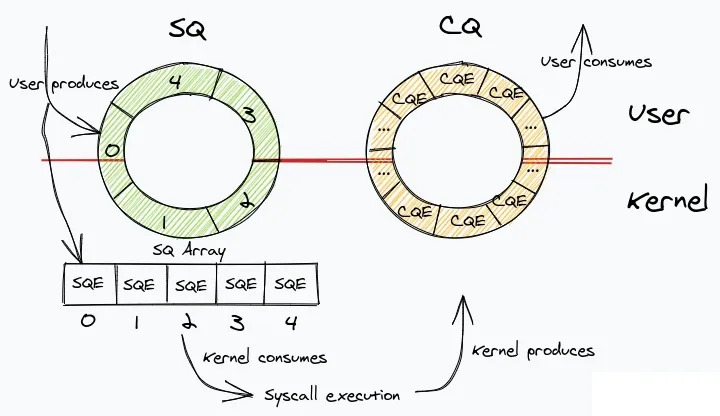
io_uring 正如名字中提到的 ring,其主要结构就是两个循环队列 Send Queue 和 Complete Queue。这两个队列由用户态和内核态共同管理。除此之外,还有一个用来保存 Send Queue Entry 的数组,即上图中的 SQ Array。SQ 中保存的都是 SQ Array 的小表,表示一个 SQ Entry。而 CQ 中直接保存的就是 CQ Entry。
应用和 io_uring 的交互流程如下:
- 获取一个 SQ Entry
- 向 SQ Entry 中填充所需的数据
- 提交 SQ Entry 到内核
- 等待内核执行对应操作
- 从 CQ 中取出 CQ Entry
这里 SQ 使用索引而不直接使用 SQ Entry 是考虑到应用可能会有批量提交,或者前后依赖(IOSQE_IO_LINK)的情况,在填写 SQE 后可能不会立即提交到内核,同时又为了避免产生一次 SQ Entry 的拷贝,所以避免应用在队列中直接拿到 SQ Entry,而是从一旁的数组中获取。
SQ Entry 作为保存提交操作的类型,其结构如下:
// tkernel4 version
/*
* IO submission data structure (Submission Queue Entry)
*/
struct io_uring_sqe {
__u8 opcode; /* type of operation for this sqe */
__u8 flags; /* IOSQE_ flags */
__u16 ioprio; /* ioprio for the request */
__s32 fd; /* file descriptor to do IO on */
__u64 off; /* offset into file */
__u64 addr; /* pointer to buffer or iovecs */
__u32 len; /* buffer size or number of iovecs */
union {
__kernel_rwf_t rw_flags;
__u32 fsync_flags;
__u16 poll_events;
__u32 sync_range_flags;
__u32 msg_flags;
__u32 timeout_flags;
};
__u64 user_data; /* data to be passed back at completion time */
union {
__u16 buf_index; /* index into fixed buffers, if used */
__u64 __pad2[3];
};
};
在最新的 kernel v5.18 中,opcode 已经多达 41 种,包括了磁盘,网络,事件循环,超时控制,文件系统五大方面,而且还在不断演进中。

CQ Entry 则相对简单,只有三个字段:
// tkernel4 version
/*
* IO completion data structure (Completion Queue Entry)
*/
struct io_uring_cqe {
__u64 user_data; /* sqe->data submission passed back */
__s32 res; /* result code for this event */
__u32 flags;
};

io_uring 原生提供了 3 个系统调用:
int io_uring_setup(unsigned entries, struct io_uring_params *params);
int io_uring_enter(unsigned int fd, unsigned int to_submit,
unsigned int min_complete, unsigned int flags,
sigset_t sig);
int io_uring_register(int fd, unsigned int opcode, const void *arg,
unsigned int nr_args);

-
io_uring_setup负责参数初始化,enteries表示 SQ 的大小,而 CQ 则默认是 SQ 的两倍大小。而 params 主要是为了传递 io_uring 的配置开关以及接收来自内核返回的用于初始化 io_uring 的参数。成功的话,返回值则是 io_uring 的文件描述符,否则返回 -1。初始化成功后,用户还需要根据内核返回的参数初始化 SQ/CQ/SQ Array 的内存空间。 -
io_uring_enter则是 io_uring 的核心操作入口,它同时肩负着提交任务和等待结果两种功能。fd 为 io_uring 对应的文件描述符。to_submit 则告诉内核有多达该数量的 sqe 准备好使用和提交,min_complete 要求内核等待该数量的请求完成。具有可用于提交和等待完成的单个调用意味着应用程序可以通过单个系统调用提交和等待请求完成。flags 包含修改调用行为的标志。 -
io_uring_register一般都用于一些高级功能。opcode 会指定对应的操作类型,比如 IORING_REGISTER_EVENTFD/IORING_UNREGISTER_EVENTFD:注册/解注册一个 eventfd,当 io_uring 产生完成时间时会通过这个 fd 通知应用。
但是系统调用都非常的精炼,直接使用起来都不太方便,比如还需要主动申请内存空间以及原子操作等。所以 io_uring 作者开发了相关的运行库 liburing,这个库将 io_uring 的系统调用进行封装,使用起来更加方便。这个 liburing 和 kernel 版本并不强绑定,建议使用尽可能高的 liburing 版本避免出现未修复的问题。
方案对比:
| 优点 | 缺点 | |
|---|---|---|
| IO 线程池 | 实现简单 | 线程过多,上下文切换频繁 |
| Linux AIO | 异步IO | 可扩展性差,仅允许 DirectIO |
| SPDK | 无系统调用 | 需要单独主动轮询,仅限于 nvme |
| io_uring | 允许不使用系统调用,可扩展性强 | 内核版本要求高 |
Linux AIO 的优势在于内核版本要求低,SPDK 则是性能高。这两个方案的缺点都在于有明显的限制条件:一个是仅允许 DirectIO,在读取未对齐的地址或者长度时会有读放大,而且也不支持内存文件系统;另一个则是仅限于 nvme,不支持 HDD 和内存文件系统,同时主动轮询的模式也不方便和当前基于 epoll 的事件循环相结合。
io_uring 虽然内核版本要求高,但是 kernel5.4 已经支持了 io_uring 的基本功能。io_uring 同时支持主动轮询和事件触发两种模式,可以很好地和框架结合在一起。甚至可以考虑在更高的内核版本下,将网络和定时器也交由 io_uring 管理,从而将基于 epoll 的事件轮询改为基于 io_uring 的主动轮询模式,这样延时可能会进一步降低。
refer:
关于优化的其他思考
性能和易用性(Trade-off)
例子:TDR (特指1.0版本) vs ProtocolBuffers
TDR 牺牲了易用性获取了高性能,而 ProtocolBuffers 通过部分性能开销换取了更好的易用性。
- 易用性
- TDR 使用
LV(Length + Value) 的编码方式,通过版本剪裁方式来解决版本兼容,但只支持单向的高版本兼容低版本数据 - ProtocolBuffers 使用
TLV(Tag + Length + Value) 的编码方式,支持前后双向兼容 - TDR 对字段顺序有要求,而 ProtocolBuffers 不需要
- TDR 使用
- 性能
- TDR 使用的编解码,不需要考虑 T 类型,故在效率和性能上,比 TLV 模式要高
- ProtocolBuffers 使用了整型数据压缩,有符号整型二次压缩 (base 128 varints 及 zigzag编码) 以尽可能节省流量,但是会引入额外的 msb(most significant bit) 计算开销
- TDR 的编码逻辑在 XML 协议确定后,一些计算可在编译期完成。而 ProtocolBuffers 需要在运行期根据 Descriptor 来确定
| 方案 | 消息的内存数据结构大小 | 序列化生成的网络消息大小 | 消息结构描述 |
|---|---|---|---|
| TDR | 1056 B | 984 B | 207 u/int32_t, 2 uint64_t, 1 float, 1 double, 1 char[33] |
| ProtocolBuffers | 动态分配 | 1290 B | 204 s/fixed32, 2 fixed64, 1 float, 1 double, 1 string(len:32) |
| 目标函数 | TDR(Avg 次/秒) | ProtocolBuffers(Avg 次/秒) | TDR 性能增量 |
|---|---|---|---|
| SerializeToArray(pack) | 574736 | 385613 | +49% |
| ParseFromArray(unpack) | 528372 | 107431 | +392% |
取长补短,TDR2.0 引入了 metalib/enabletlv, id 新属性决定是否采用 TLV 模式,且由调用者决定整型数据是否使用变长编码,对比 TDR1.0 性能测试,TDR2.0 性能下降 10%-20%
其他方面优化
程序1:
#include <cstdio>
int main()
{
printf("Hello world");
return 0;
}
g++ -Os example.cc
程序2:
section .data
some_string dq "Hello world"
some_string_size dq 11
section .text
global _start
_start:
; Print the string
mov rax, 1 ; sys_write
mov rdi, 1 ; param 1, stdout
mov rsi, some_string ; param 2
mov rdx, [some_string_size] ; param 3
syscall
; Exit the program
mov rax, 60 ; sys_exit
mov rdi, 0 ; param 1
syscall
nasm -f elf64 -o example.o example.asm ld -o example example.o strip example
对比:
| Program | Size | Size (stripped) |
|---|---|---|
| example (asm) | 984 B | 528 B |
| example (cc, -Os) | 8.2K | 6.0K |
使用nasm写汇编,手动构造ELF格式文件。不使用c库,系统调用使用syscall指令(x86-64):
- 入参:
- eax = 系统调用号,可以在 /usr/include/asm/unistd_64.h 文件中找到
- rdi, rsi, rdx, r10, r8, r9 分别为第 1 至 6 个参数
- 出参:
- rax = 返回值(如果失败,返回 -errno)
- rcx, r11 被破坏(它们分别被 syscall 指令用来保存返回地址和 rflags)
- 其他寄存器的值保留
更多:极客技术挑战赛实现一个世界上最小的程序来输出自身的MD5,其中,最小实现方案为299字节,实现代码。
优化策略:
- 预先计算中间状态,减少代码分支
- 避免 copy(修改
text段为可写) - 分支之间共用指令,代码共用
- 指令选择(早期x86的指令,使用的字节较少。例如:
lodsb只要一个字节,而mov al,[rsi]; inc rsi要多一些,可通过objdump -d比较) - 寄存器的选择(优先使用从32位时代沿袭下来的8个寄存器 (
rax, rbx, rcx, rdx, rsi, rdi, rbp, rsp),避免使用r8-r15。对于很多指令,使用r8-r15会多占一个字节) - 用最短的代码赋值小常量给寄存器
- 对0值,对寄存器异或自身:
xor eax, eax - 对非0值,例如,将常量1赋给
eax(方法1使用5个字节,而方法2只使用3个字节)
- 对0值,对寄存器异或自身:
方法1:
4000b0: b8 01 00 00 00 mov $0x1,%eax
方法2:8086 指令
4000b0: 6a 01 pushq $0x1
4000b2: 58 pop %rax
- 32位 or 64位寄存器(x86-64有一个特性,目标操作数是32位寄存器时,会同时清空对应64位寄存器的高32位。所以,
xor eax, eax等价xor rax, rax,mov eax, 1等价mov rax, 1)。使用32位寄存器通常可以省1个字节(r8-r15除外),但注意,在作为地址时,情况相反,64位少1个字节。 - 进程初始状态(简化OS的初始化操作)
- 使用16位地址(修改进程初始虚拟地址
/proc/sys/vm/mmap_min_addr) pext指令(位运算BMI 2指令)- 寻址优化
- 调用函数(call指令)
性能优化最佳实践
-
宏观上,合理的架构。例如,Google的GFS的实现中,为了保持系统简单,在一致性(C)和可用性中(A),GFS选择了可用性,而放宽了对一致性的要求。追加写入是GFS中主要的写操作,追加写只保证至少写入一次的语义,每一次写入都需要等待所有副本节点写入成功,如果在任意一个节点上失败,客户端都会得到写失败的通知,然后发起重试,GFS并不会对之前在部分节点上写入的脏数据做处理,而是直接暴漏给了应用程序,让应用程序完成去重和排序的工作。
-
微观上,合理的数据结构和算法。
-
基础组件的优化 (比如, gettimeofday, string_veiw, Log)
-
全静态编译 (相比动态编译会有几个点的提高)
-
减少系统调用(vDSO可以提升77%)
-
内存池优化 (tcmalloc)
-
Zero Copy (sendfile)
-
Pipeline 无锁编程介绍
-
利用新的硬件红利(NUMA架构的优化)
Memory Benchmark
- Testing Memory Allocators: ptmalloc2 vs tcmalloc vs hoard vs jemalloc While Trying to Simulate Real-World Loads
- Mimalloc-bench
More
Refer
- Linux Load Averages: Solving the Mystery,其中,译文可参考此文
- Computer performance
- Make a program run slowly
- Other Built-in Functions Provided by GCC
- Technical Report on C++ Performance
- Why does clang produce inefficient asm with -O0 (for this simple floating point sum)?
- Why does GCC generate 15-20% faster code if I optimize for size instead of speed?