Linux Performance 诊断
高性能常见方法
- 合理的架构
- 合理的数据结构
- 合理的算法
- 组件的优化 (比如, gettimeofday, string_veiw, Log)
- 全静态编译 (相比动态编译会有几个点的提高)
- 减少系统调用
- 内存池优化 (tcmalloc优化)
- Zero Copy (sendfile)
可观测性
灵魂拷问:为什么在客户端看到的延迟是100ms,而server端处理只用了50ms,中间这50ms去哪里了?
根本原因在于,一次请求的时间可以分为业务可见的部分和业务不可见的部分。比如,本地一次加密耗时1ms,但调用一次服务做一次加密耗时10ms,这9ms到哪里去了?
- 计算。比如,序列化,上游其实不会关心请求的序列化和反序列化,以及从用户态拷贝到内核态,这些都被归类到计算里,而这些延迟一般都会被业务侧忽略掉,认为处理时间仅仅只有包括自己的业务逻辑。
- 调度。比如,要异步发送一个东西,数据写入后,如果机器负载非常高,可能需要等待100ms再发送,这是上游可能已经认为超时了。
- 网络。出现超时后,网络永远是第一个排查项,是不是挂了,是不是变慢了。
可观测性,主要是为了解决以上问题。即,把上游看不到的地方做可视化处理,把所有需要观测的地方进行事件收集,并做集中展示。通常,这种方案对CPU的开销约为 8% - 10%,一般在开发阶段开启优化,或者按需开启。
性能指标
- 吞吐
- 延时
从应用角度看,需要做到:高并发,低延时。 从资源角度看,需要关心:资源使用率,饱和度。
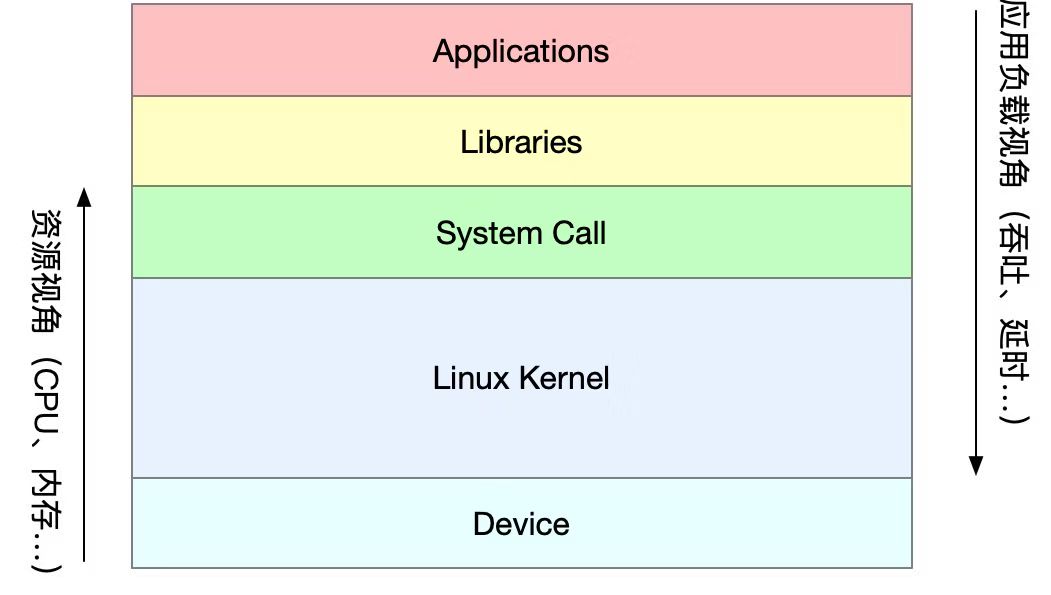
随着应用负载的增加,系统资源的使用也会升高,甚至达到极限。而性能问题的本质,就是系统资源已经达到瓶颈,导致请求处理不过来。性能分析就是找出应用或系统的瓶颈,并设法去避免或者缓解它们,从而更高效地利用系统资源处理更多的请求。
Brendan Gregg描述的 Linux性能工具图谱,可以帮助我们在发现Linux出现性能问题后,应该用什么工具来定位和分析(更多:Linux Performance)。
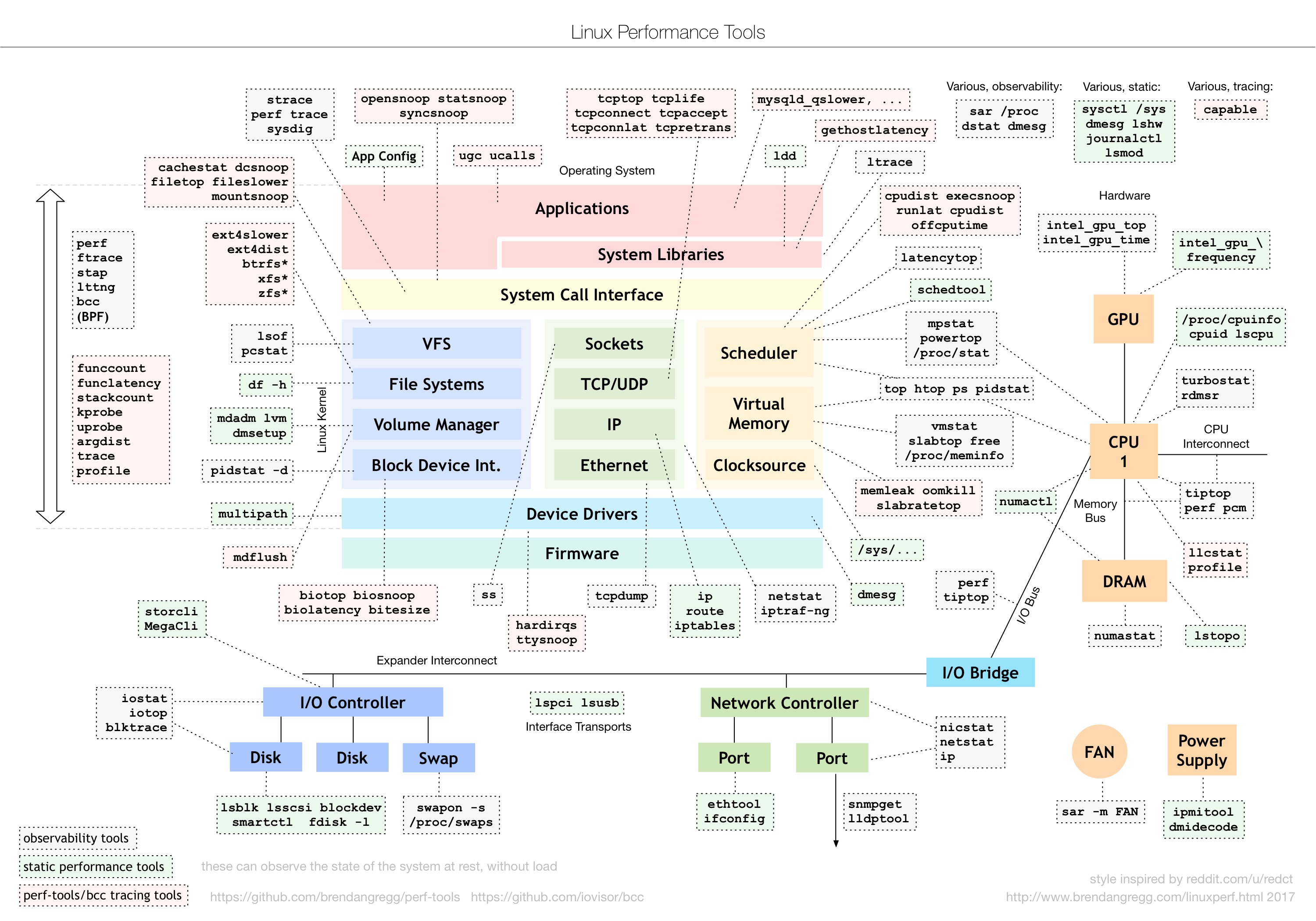
以下是一张总的Linux性能优化的思维导图,包括:
- CPU
- 内存
- 网络
- 磁盘IO
- 文件系统
- Linux内核
- 应用程序
- 架构设计
- 性能监控
- 性能测试
CPU相关
通过cat /proc/cpuinfo可以看到cpu的相关信息。
- CPU:独立的中央处理单元,体现在主板上是有多个CPU的
槽位。 - CPU cores:在每一个CPU上,都可能有多个核(core),每一个核中都有独立的一套ALU,FPU,Cache等组件,所以这个概念也被称作
物理核。 - processor:这个主要得益于超线程(HTT)技术,可以让一个物理核模拟出多个
逻辑核,即processor。 - 超线程(Hyper-threading),是一种用于提升CPU计算并行度的处理器技术,用一个物理核模拟两个逻辑核。 这两个逻辑核拥有自己的中断、状态,但是共用物理核的计算资源。超线程技术旨在提高CPU计算资源的使用率,从而提高计算并行度。超线程技术基于这样一个现实,那就是大多数程序运行时,CPU资源并没有得到充分的利用。比如CPU缓存未命中、分支预测错误或者等待数据时,CPU中的计算资源其实是闲置的。超线程技术,可以通过硬件指令,将这些闲置的CPU资源,调度给其他的指令,从而整体上提高CPU的资源利用率。有研究表明,超线程依赖于操作系统对CPU的调度。但是如果应用程序开启了CPU绑定功能,则有可能破坏这种调度的完整性,反而带来性能损失。
Refer:
When is hyper-threading performance not worth the hassle
平均负载
每当系统变慢时,可以通过top或者uptime命令来了解系统的负载情况。
平均负载:是指单位时间内,系统处于可运行状态和不可中断状态的平均进程数,也就是平均活跃进程数(实际上是,活跃进程数的指数衰减平均值),它和CPU使用率并没有直接关系。因此,最理想的是,每个CPU上都刚好运行着一个进程,这样每个CPU都得到了充分利用。
例如,当平均负载为2时。 在只有2个CPU的系统上,意味着所有的CPU都刚好被完全占用。 在4个CPU的系统上,意味着CPU有50%的空闲。 在只有1个CPU的系统上,意味着一半的进程竞争不到CPU。
可运行状态的进程:是指正在使用CPU或者正在等待CPU的进程,用ps命令看到处于R状态的进程。
不可中断的进程:是指正处于内核态关键流程中的进程,并且这些流程是不可打断的,比如最常见的是等待硬件设备的I/O响应。用ps命令看到处于D状态的进程。
比如,当一个进程向磁盘读写数据时,为了保护数据的一致性,在得到磁盘回复前,它是不能被其他进程或者中断打断的,这个时候的进程就处于不可中断状态。如果此时的进程被打断了,就容易出现磁盘数据与进程数据不一致的问题。所以,不可中断状态实际上是系统对进程和硬件设备的一种保护机制。
平均负载多少时合理
可以通过top或者从文件/proc/cpuinfo中获取cpu的信息。在实际生产环境中,当平均负载高于CPU数量70%(并不绝对)的时候,就应该排查负载高的问题了。
grep 'model name' /proc/cpuinfo | wc -l
平均负载与CPU使用率
平均负载,是指单位时间内,处于可运行状态和不可中断状态的进程数。所以,它不仅包括了正在使用CPU的进程,还包括等待CPU和等待I/O的进程。
CPU使用率,是单位时间内CPU繁忙情况的统计,和平均负载并不一定完全对应。比如:
- CPU密集型进程。使用大量CPU会导致平均负载升高,此时两者是一致的。
- I/O密集型进程。等待I/O也会导致平均负载升高,但CPU使用率不一定很高。
- 大量等待CPU的进程调度,也会导致平均负载升高,此时的CPU使用率也会比较高。
上下文切换
- 使用
vmstat来查询系统总体上的上下文切换情况。 - 使用
pidstat -wt来查询每个进程的上下文切换情况。 - 使用
sysbench来模拟系统多线程调度切换的情况。 - 上下文切换频率是多少次才算正常?这个数值取决于系统本身的CPU性能。如果系统的上下文切换次数比较稳定,从数百到一万以内,都应该算是正常的。但当超过一万次,或者出现数量级的增长时,就可能出现了性能问题。
CPU上下文
Linux是一个多任务操作系统,它支持远大于CPU数量的任务同时运行。当然这些任务实际上并不是真正的在同时运行,而是因为系统在很短的时间内,将CPU轮流分配给它们,造成多任务同时运行的错觉。而在每个任务运行前,CPU都需要知道任务从哪里加载,又从哪里开始运行,需要系统事先帮它设置好CPU寄存器和程序计数器。以上都是CPU在运行任何任务前,必须的依赖环境,因此被叫做CPU上下文。
- CPU寄存器:CPU内置的容量小,但速度极快的内存。
- 程序计数器:用来存储CPU正在执行的指令位置,或者即将执行的下一条指令位置。
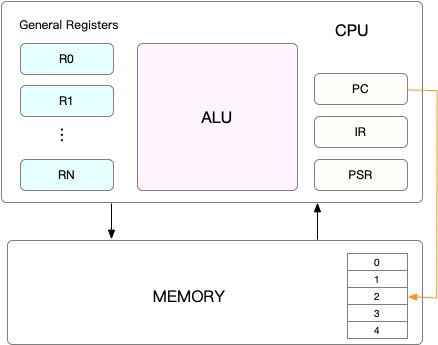
CPU上下文切换
CPU上下文切换,就是把前一个任务的CPU上下文保存起来,然后加载新任务的上下文到这些寄存器和程序计数器,最后再跳转到程序计数器所指的新位置运行新的任务。而这些保存下来的上下文,会存储在系统内核中,并在任务重新调度执行时再次加载进来。这样就能保证任务原来的状态不受影响,让任务看起来还是连续运行的。
根据任务的不同,CPU的上下文切换可以分为几个不同的场景:
- 进程上下文切换
- Linux按照特权等级,把进程的运行空间分为内核空间和用户空间,分别对应CPU特权等级的Ring 0和Ring 3。
- 内核空间(Ring 0),具有最高权限,可以直接访问所有资源。
- 用户空间(Ring 3),只能访问受限资源,不能直接访问内存等硬件设备,必须通过系统调用陷入到内核中,才能访问这些特权资源。
- 进程既可以在用户空间运行,又可以在内核空间中运行。进程再用户空间运行时,被称为进程的用户态,而陷入内核空间时,被称为进程的内核态。从用户态到内核态的转变,需要通过系统调用来完成。
- 系统调用的过程中,会发生CPU上下文的切换。CPU寄存器里原来是用户态的指令,需要先保存起来,接着为了执行内核态代码,CPU寄存器需要更新为内核态指令,最后才是调到内核态运行内核任务。而系统调用结束后,CPU寄存器需要恢复原来保存的用户态,然后再切换到用户空间,继续运行进程。所以,一次系统调用的过程,发生了2次CPU上下文切换。
- 进程上下文切换和系统调用的区别?
- 进程上下文切换,是指从一个进程切换到另一个进程运行。而系统调用过程中,一直是同一个进程在运行。
- 进程是由内核来管理和调度的,进程的切换只能发生在内核态。所以,进程的上下文切换不仅包括了虚拟内存,栈,全局变量等用户空间的资源,还包括内核堆栈,寄存器等内核空间的状态。因此,进程的上下文切换比系统调用时多了一步,在保存当前进程的内核状态和CPU寄存器之前,需要先把该进程的虚拟内存,栈等保存下来。而加载了下一进程的内核态后,还需要刷新进程的虚拟内存和用户栈。
- 根据Tsuna’s blog - How long does it take to make a context switch?的测试报告,每次上下文切换都需要几十纳秒到数微秒的CPU时间。在进程上下文切换次数较多的情况下,这个开销还是很大的,很容易导致CPU将大量时间耗费在寄存器,内核栈以及虚拟内存等资源的保存和恢复上,进而大大缩短了真正运行进程的时间。这个也是导致平均负载升高的一个重要因素。
- Linux通过TLB(Translation Lookaside Buffer)来管理虚拟内存到物理内存的映射关系。当虚拟内存更新后,TLB也需要刷新,内存的访问也会随之变慢。特别是在多处理器系统上,缓存是被多个处理器共享的,刷新缓存不仅会影响当前处理器的进程,还会影响共享缓存的其他处理器的进程。
- 什么时候会切换进程上下文?
- 只有在进程调度的时候,才需要进程切换上下文。
- Linux为每个CPU都维护了一个就绪队列,将活跃进程(正在运行和正在等待CPU的进程),按照优先级和等待CPU的时间排序,然后选择最需要CPU的进程运行。
- 进程调度的场景:
- 进程执行完终止了,它之前使用的CPU会释放出来,这个时候再从就绪队列里,拿一个新的进程来运行。
- 为了保证所有进程可以得到公平调度,CPU时间被划分为一段段的时间片,这些时间片再被轮流分配给各个进程。当某个进程的时间片耗尽了,就会被系统挂起,切换到其他正在等待CPU的进程运行。
- 进程在系统资源不足(比如,内存不足)时,要等到资源满足后才可以运行,这个时候进程也会被挂起,并由系统调度其他进程运行。
- 当进程通过睡眠函数sleep这样的方法将自己主动挂起时,自然也会重新调度。
- 当有优先级更高的进程运行时,为了保证高优先级进程的运行,当前进程会被挂起,由高优先级的进程来运行。
- 发生硬件中断时,CPU上的进程会被中断挂起,转而执行内核中的中断服务程序。

- 线程上下文切换
- 线程是调度的基本单位,而进程则是资源拥有的基本单位。
- 内核中的任务调度,实际上的调度对象是线程。
- 进程只是给线程提供了虚拟内存,全局变量等资源。
- 当进程只有一个线程时,可以认为进程就等于线程。
- 当进程拥有多个线程时,这些线程会共享相同的虚拟内存和全局变量等资源,这些资源在线程上下文切换时是不需要修改的。
- 线程也有自己的私有数据,比如栈和寄存器等,这些在线程上下文切换时也是需要保持的。
- 线程的上下文切换分为两种情况:
- 若前后两个线程属于不同进程,此时,因为资源不共享,所以切换过程就跟进程上下文切换是一样的。
- 若前后两个线程属于相同进程,此时,因为虚拟内存是共享的,所以在切换时,虚拟内存这些资源就保持不动,只需要切换线程的私有数据,寄存器等不共享的数据。
- 同进程内的线程切换,要比多进程间的切换消耗更少的资源。
- 中断上下文切换
- 为了快速响应硬件的事件,中断处理会打断进程的正常调度和执行,转而调用中断处理程序,响应设备事件。
- 在打断其他进程时,就需要将进程当前的状态保存下来,这样在中断结束后,进程仍然可以从原来的状态恢复运行。
- 与进程上下文切换不同,中断上下文切换并不涉及到进程的用户态。即,中断过程打断了一个正处在用户态的进程,也不需要保存和恢复这个进程的虚拟内存,全局变量等用户态资源。
- 中断上下文,其实只包括内核态中断服务程序执行所必需的状态,包括CPU寄存器,内核堆栈,硬件中断参数等。
- 对同一个CPU来说,中断处理比进程拥有更高的优先级,所以中断上下文切换并不会与进程上下文切换同时发生。
- 由于中断会打断正常进程的调度和执行,所以大部分中断处理程序都短小精悍,以便尽可能快的执行结束。
CPU使用率
- CPU使用率,是单位时间内CPU使用情况的统计,以百分比的方式展示。
- 总体CPU使用率
- 逻辑上:CPU使用率 = 1 - 空闲时间/总CPU时间
- 实际计算(/proc/stat):平均CPU使用率 = 1 - (空闲时间_tend - 空闲时间_tbeg)/(总CPU时间_tend - 总CPU时间_tbeg)
- 单进程CPU使用率
- /proc/$pid/stat (计算方法类似)
- 性能分析工具给出的都是间隔一段时间的平均CPU使用率。注意,使用不同工具对比CPU使用率结果可能不一样,比如,top默认使用3秒间隔,而ps使用却是进程的整个生命周期。
- 相关工具:
- top/ps/pidstat
- 总体CPU使用率
节拍率CONFIG_HZ(内核选项)。为了维护CPU时间,Linux通过事先定义的节拍率(内核中表示为HZ),触发时间中断,并使用全局变量Jiffies记录开机以来的节拍数。每发生一次时间中断,Jiffies的值就加1。节拍率HZ是内核的可配选项,可以设置为100,250,1000等,不同的系统可能设置不同数值。
# 通过内核选项查看节拍率的配置值,代表每秒钟触发250次时间中断
$grep "CONFIG_HZ=" /boot/config-$(uname -r)
CONFIG_HZ=250
节拍率USER_HZ(用户空间),它固定为100(即,1/100秒),用户空间程序并不需要关心内核中HZ被设置成了多少,因为它看到的总是固定值USER_HZ。/proc/stat提供了关于系统的CPU和任务统计信息。- man proc
- 第一列是CPU编号。而第一行没有编号的cpu表示是所有cpu的累加。其他列则表示不同场景下cpu的累加节拍数,它的单位是USER_HZ(即,1/100秒,10ms)
- 每一列的含义:
user(缩写为us),代表用户态CPU时间。注意,它不包括nice时间,但包括了guest时间。nice(缩写为ni),代表低优先级用户态CPU时间。也就是进程的nice值被调整为1-19之间时的CPU时间。(nice可取值范围是-20到19,数值越大,优先级反而越低)。system(缩写为sys),代表内核态CPU时间。idle(缩写为id),代表CPU空闲时间。注意,它不包括等待I/O的时间(iowait)。iowait(缩写为wa),代表等待I/O的CPU时间。irq(缩写为hi),代表处理硬中断的CPU时间。softirq(缩写为si),代表处理软中断的CPU时间。steal(缩写为st),代表当系统运行在虚拟机中的时候,被其他虚拟机占用的CPU时间。guest(缩写为guest),代表通过虚拟化运行其他操作系统的时间,也就是运行虚拟机的CPU时间。
$cat /proc/stat | grep ^cpu
cpu 578330344 13474169 274296516 29468768395 1704635 1707 8800004 559876 0 0
cpu0 76800541 3786 41365936 3662395305 1410425 514 1247852 153728 0 0
cpu1 73694193 810 36164076 3677516853 46311 1192 2354244 148069 0 0
cpu2 71767326 802 33430992 3688209240 40770 0 860220 43860 0 0
cpu3 71783262 568 32693404 3690062413 41661 0 875085 42675 0 0
cpu4 71347242 617 32365060 3691242578 39912 0 854235 42197 0 0
cpu5 71362048 566 32447788 3691034602 38925 0 893029 42947 0 0
cpu6 71066492 748 32433314 3691442169 38796 0 855324 42912 0 0
cpu7 70509238 13466270 33395943 3676865232 47833 0 860013 43484 0 0
中断
- 为什么要有中断?举个生活的例子,送快递,通过电话的方式。
- 中断是一种异步的事件处理机制,可以提高系统的并发处理能力。
- 由于中断处理程序会打断其他进程的运行,所以,为了减少对正常运行调度的影响,中断处理程序就需要尽可能快地运行。
- 中断可能会丢失。例子,多个人送快递,第二个人的电话可能占线。
- 为了解决中断处理程序执行过长和中断丢失的问题,Linux将中断处理过程分成了两个阶段:
上半部和下半部。- 上半部用来快速处理中断。它在中断禁止模式下运行,主要处理跟硬件紧密相关的,或时间敏感的工作。
- 下半部用来延迟处理上半部未完成的工作,通常以内核线程的方式运行。
- 例子:取快递。上半部是接电话告诉配送员在哪里见面然后就可以挂电话了;下半部是取快递的动作。
- 上半部,直接处理硬件请求,也就是
硬中断,特点是执行快。 - 下半部,是由内核触发,也就是
软中断(softirq),特点是延迟执行。 - 实际上,上半部会打断CPU正在执行的任务,然后立即执行中断处理程序。而下半部以内核线程的方式执行,并且每个CPU都对应一个软中断内核线程,名字为
ksoftirqd/CPU编号,比如,0号CPU对应的软中断内核线程的名字就是ksoftirqd/0。 - 一些内核自定义的事件也属于软中断,比如,内核调度和RCU锁(Read-Copy Update)。
查看软中断
/proc/softirqs提供了软中断的运行情况。可以看到各种类型软中断在不同CPU上的累积运行次数。- 软中断,包括了10个类别:
NET_RX,网络接收中断NET_TX,网络发送中断TIMER,定时中断SCHED,内核调度RCU,RCU锁
- 正常情况,同一种中断在不同CPU上的累积次数应该相差不大。
$ cat /proc/softirqs
CPU0 CPU1 CPU2 CPU3 CPU4 CPU5 CPU6 CPU7
HI: 0 0 0 0 0 0 0 0
TIMER: 713323306 597120381 575130430 543948933 542820584 527320354 551004569 529250593
NET_TX: 3942016 2162 9436 8941 9259 9053 9259 9201
NET_RX: 3544603084 3397281158 702109101 680604389 682339441 658940411 701453549 697373610
BLOCK: 0 0 0 0 0 0 0 0
BLOCK_IOPOLL: 0 0 0 0 0 0 0 0
TASKLET: 104 93 1 0 0 0 0 0
SCHED: 334322040 201626971 182193519 166406020 158340210 155001620 162949961 160917624
HRTIMER: 3770790 3067883 3294058 2814030 3082644 5280147 2529713 2751330
RCU: 505317878 414070615 405384406 383304364 379485156 369748897 386444807 374074340
如何查看中断次数的变化速率?
# 从高亮部分可以直观看出哪些内容变化的更快
watch -d cat /proc/softirqs
查看内核线程
内核线程的名字外面都有中括号,说明ps命令无法获取它们的命令行参数。
$ ps aux|grep softirq
root 3 0.0 0.0 0 0 ? S May15 2:56 [ksoftirqd/0]
root 29 0.0 0.0 0 0 ? S May15 2:08 [ksoftirqd/1]
root 34 0.0 0.0 0 0 ? S May15 0:39 [ksoftirqd/2]
root 39 0.0 0.0 0 0 ? S May15 0:36 [ksoftirqd/3]
root 44 0.0 0.0 0 0 ? S May15 0:33 [ksoftirqd/4]
root 49 0.0 0.0 0 0 ? S May15 0:37 [ksoftirqd/5]
root 54 0.0 0.0 0 0 ? S May15 0:36 [ksoftirqd/6]
root 59 0.0 0.0 0 0 ? S May15 0:34 [ksoftirqd/7]
查看硬中断
/proc/interrupts提供了硬中断的运行情况。
$ cat /proc/interrupts
CPU0 CPU1 CPU2 CPU3 CPU4 CPU5 CPU6 CPU7
0: 33 0 0 0 0 0 0 0 IO-APIC-edge timer
1: 10 0 0 0 0 0 0 0 IO-APIC-edge i8042
4: 325 0 0 0 0 0 0 0 IO-APIC-edge serial
8: 1 0 0 0 0 0 0 0 IO-APIC-edge rtc0
9: 0 0 0 0 0 0 0 0 IO-APIC-fasteoi acpi
10: 0 0 0 0 0 0 0 0 IO-APIC-fasteoi virtio3
40: 0 0 0 0 0 0 0 0 PCI-MSI-edge virtio1-config
41: 16669006 0 0 0 0 0 0 0 PCI-MSI-edge virtio1-requests
42: 0 0 0 0 0 0 0 0 PCI-MSI-edge virtio2-config
43: 59166530 0 0 0 0 0 0 0 PCI-MSI-edge virtio2-requests
44: 0 0 0 0 0 0 0 0 PCI-MSI-edge virtio0-config
45: 6689988 0 0 0 0 0 0 0 PCI-MSI-edge virtio0-input.0
46: 0 0 0 0 0 0 0 0 PCI-MSI-edge virtio0-output.0
47: 2093616484 0 0 0 0 0 0 0 PCI-MSI-edge peth1-TxRx-0
48: 5 2045859720 0 0 0 0 0 0 PCI-MSI-edge peth1-TxRx-1
49: 81 0 0 0 0 0 0 0 PCI-MSI-edge peth1
NMI: 0 0 0 0 0 0 0 0 Non-maskable interrupts
LOC: 2936184495 965056330 1641503935 1442909354 1106218217 1180680219 1110309682 1158481374 Local timer interrupts
SPU: 0 0 0 0 0 0 0 0 Spurious interrupts
PMI: 0 0 0 0 0 0 0 0 Performance monitoring interrupts
IWI: 53775871 47387196 47737572 44243915 43451907 44050411 44488100 44338708 IRQ work interrupts
RTR: 0 0 0 0 0 0 0 0 APIC ICR read retries
RES: 1198594562 964481221 966552350 902484234 871559958 863341236 864670220 858000383 Rescheduling interrupts
CAL: 4294967071 4438 430547422 419910155 438252892 417825974 443016275 448064960 Function call interrupts
TLB: 1206563963 65932469 1378887038 1028081848 891541016 853171175 829911769 751250837 TLB shootdowns
TRM: 0 0 0 0 0 0 0 0 Thermal event interrupts
THR: 0 0 0 0 0 0 0 0 Threshold APIC interrupts
MCE: 0 0 0 0 0 0 0 0 Machine check exceptions
MCP: 65623 65623 65623 65623 65623 65623 65623 65623 Machine check polls
ERR: 0
MIS: 0
内存相关
- 物理内存:只有内核才可以直接访问物理内存。
- 虚拟内存:内核给每个进程都提供了一个独立的虚拟地址空间,并且这个地址空间是连续的。
- 虚拟地址空间的内部又分成:
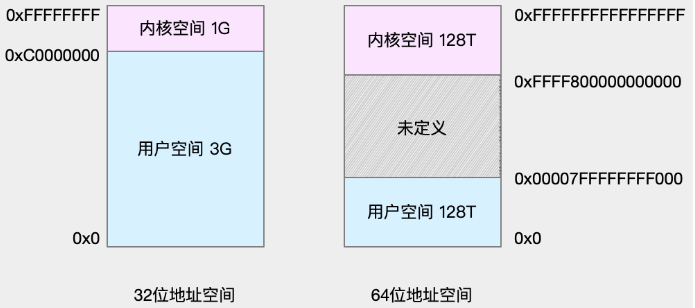
内核空间和用户空间两部分 - 不同字长(单个CPU指令可以处理数据的最大长度)的处理器,地址空间的范围不同。32位系统的内核空间占用1G,位于最高处,剩下的3G是用户空间;而64位系统的内核空间和用户空间都是128T,分别占据整个内存空间的最高和最低处,剩下的中间部分是未定义的。
- 虚拟地址空间的内部又分成:
- 对普通进程而言,能看到的其实是内核提供的
虚拟内存,这些虚拟内存还需要通过页表,由系统映射为物理内存。 - 当通过
malloc()申请虚拟内存后,系统并不会立即为其分配物理内存,而是在首次访问时,才通过缺页异常陷入内核中分配内存。 - 为了协调CPU和磁盘的性能差异,Linux会使用Cache和Buffer,分别把文件和磁盘读写的数据缓存到内存中。
- 对于应用程序来说,动态内存的分配和回收,是既核心又复杂的一个逻辑功能模块,管理内存的过程中,很容易发生各种各样的“事故”。
- 没正确回收分配后的内存,导致
内存泄露 - 访问的是已分配内存
边界外的地址,导致程序异常退出。
- 没正确回收分配后的内存,导致
如何查看内存的使用情况?(数值都默认以字节为单位)
# free
total used free shared buffers cached
Mem: 1017796 819720 198076 16784 46240 468880
-/+ buffers/cache: 304600 713196
Swap: 0 0 0
- VIRT,进程虚拟内存的大小,虚拟内存并不会全部分配物理内存
- RES,常驻内存的大小,是进程实际使用的物理内存大小,但不包括Swap和共享内存
- SHR,共享内存大小,比如,与其他进程共同使用的共享内存,加载的动态链接库以及程序的代码段等
- %MEM,进程使用物理内存占系统总内存的百分比
可以使用pmap -xp $pid分析下进程的内存分布,更详细的信息可以通过cat /proc/$pid/smaps (since Linux 2.6.14)来查看每个进程的内存消耗情况。
补充:
- man - proc
- man - pmap
- man - top
- What is RSS and VSZ in Linux memory management
- RSS and PSS, Clean vs Dirty, Private vs Shared
- Need explanation on Resident Set Size/Virtual Size
- How does x86 paging work?
- Memory usage of current process in C
内存映射
每个进程都有一个这么大的地址空间,所有进程的虚拟内存加起来,要比实际的物理内存大得多。所以,并不是所有的虚拟内存都会分配物理内存,只有实际使用的虚拟内存才分配物理内存,并且分配后的物理内存,是通过内存映射来管理的。
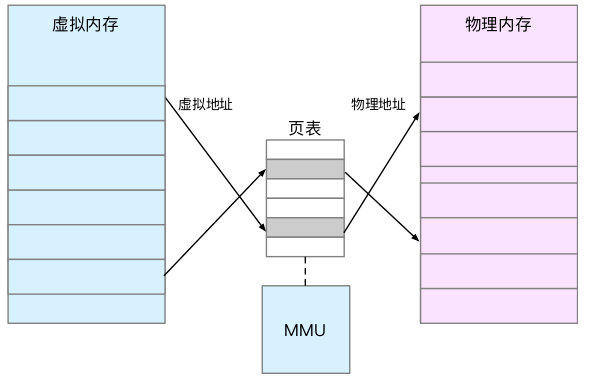
- 内存映射,就是将虚拟内存地址映射到物理内存地址。为了完成内存映射,内核为每个进程都维护了一张页表,记录虚拟地址与物理地址的映射关系。
- 页表,实际上存储在CPU的内存管理单元MMU中,正常情况下,处理器就可以直接通过硬件找出要访问的内存。
- 当进程访问的虚拟地址在页表中查不到时,会产生一个缺页异常,进入内核空间分配物理内存,更新进程页表,最后再返回用户空间,恢复进程的运行。
- TLB(Translation Lookaside Buffer, 转译后备缓冲器)会影响CPU的内存访问性能。TLB其实是MMU中页表的高速缓存,由于进程的虚拟地址空间是独立的,而TLB的访问速度又比MMU快得多。所以,通过减少进程的上下文切换,减少TLB的刷新次数,可以提高TLB缓存的使用率,进而提高CPU的内存访问性能。
- MMU并不以字节为单位来管理内存,而是规定了一个内存映射的最小单位是页,通常是4 KB大小。这样,每一次内存映射,都需要关联4 KB或4 KB整数倍的内存空间。
问题:页的大小只有4 KB。导致一个问题是,整个页表会变得非常大。例如,32位系统就需要100多万个页表项(4GB/4KB),才可以实现整个地址空间的映射。
为了解决页表项过多的问题,Linux提供了两种机制,多级页表和大页。多级页表,把内存分成区块来管理,将原来的映射关系改成区块索引和区块内的偏移。由于虚拟内存空间通常只用了很少一部分,多级页表就只保存这些使用中的区块,这样就可以大大地减少页表的项数。
Linux用的正是四级页表来管理内存:
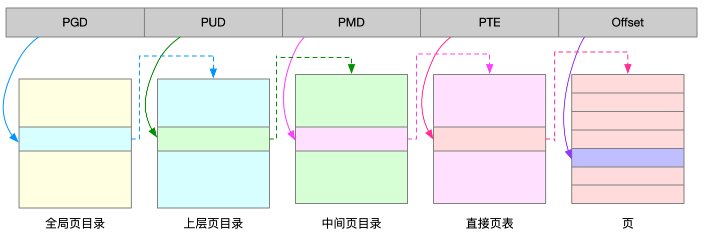
虚拟内存空间分布
以32位系统为例。
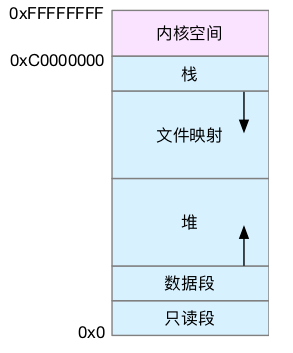
用户空间内存,从低到高分别是五种不同的内存段:
- 只读段,包括代码和常量等
- 数据段,包括全局变量等
- 堆,包括动态分配的内存,从低地址开始向上增长
- 文件映射段,包括动态库,共享内存等,从高地址开始向下增长
- 栈,包括局部变量和函数调用的上下文等。栈的大小是固定的,一般是8MB
内存分配与回收
malloc是C标准库提供的内存分配函数,对应到系统调用上,有两种实现方式:brk()和mmap()
- 对小块内存(小于128K),C标准库使用
brk()来分配,通过移动堆顶的位置来分配内存,这些内存释放后并不会立刻归还系统,而是被缓存起来,这样就可以重复使用。 - 对大块内存(大于128KB),直接使用内存映射
mmap()来分配,在文件映射段找一块空闲内存分配出去。
优缺点:
brk(),使用缓存可以减少缺页异常的发生,提高内存访问效率。但是,由于这些内存没有归还系统,在内存工作繁忙时,频繁的内存分配和释放会造成内存碎片。
mmap(),分配的内存,会在释放时直接归还系统,所以每次mmap都会发生缺页异常。在内存工作繁忙时,频繁的内存分配就会导致大量的缺页异常,使内核的管理负担增大。这也是malloc只对大块内存使用mmap的原因。
- 当这两种调用发生后,其实并没有真正分配内存,而是在首次访问时才分配(通过缺页异常进入内核中,再由内核来分配内存)。
- Linux使用伙伴系统来管理内存分配。伙伴系统也以页为单位来管理内存,并且会通过相邻页的合并,减少内存碎片化(比如,brk方式造成的内存碎片)。
- 实际系统运行中,会存在大量比页更小的对象,如果为它们分配单独的页,就太浪费内存了。所以:
- 在用户空间,malloc通过brk()分配的内存,在释放时并不立即归还系统,而是缓存起来重复利用。
- 在内核空间,Linux通过
slab分配器来管理小内存。
- 在应用程序用完内存后,需要调用
free()或unmap()来释放不用的内存,否则会造成内存泄露,耗尽系统内存。 - 系统回收内存的机制:
- 回收缓存,比如,使用
LRU(Least Recently Used)算法,回收最近使用最少的内存页面 - 回收不常访问的内存,把不常用的内存通过交换分区(Swap)直接写到磁盘中
- 杀死进程,内存紧张时系统还会通过
OOM(Out of Memory),直接杀掉占用大量内存的进程
- 回收缓存,比如,使用
缓存命中率
Buffer和Cache的设计目的,是为了提升系统的I/O性能。它们利用内存,充当起慢速磁盘与快速CPU之间的桥梁,可以加速I/O的访问速度。Buffer和Cache分别缓存的是对磁盘和文件系统的读写数据。- 写。可以优化磁盘和文件的写入,应用程序可以在数据真正落盘前,返回去做其他工作。
- 读。可以提高那些频繁访问数据的读取速度,降低频繁I/O对磁盘的压力。
- 使用dd测试读写文件,用vmstat查看,
Buffer是对磁盘数据的缓存,而Cache是文件数据的缓存,它们既会用在读请求中,也会用在写请求中。
Q: 如何衡量缓存使用的好坏? A: 缓存的命中率。是指直接通过缓存获取数据的请求次数,占所有数据请求次数的百分比。命中率越高,表示使用缓存带来的收益越高,应用程序的性能也就越好。
Q: 如何查看缓存的命中率? A: 使用cachestat和cachetop。其中,cachestat提供了整个系统缓存的读写命中情况,cachetop提供了每个进程的缓存命中情况。(这两个工具都是bcc软件包的一部分,它们基于Linux内核的eBPF, extended Berkeley Packet Filters机制,来跟踪内核中管理的缓存,并输出缓存的使用和命中情况)。注意,如果是CentOS环境,bcc-tools需要内核版本至少4.1。
Q: 如何指定文件的缓存大小? A: 指定文件在内存中的缓存大小,可以使用pcstat这个工具,来查看文件在内存中的缓存大小和缓存比例。
$ pcstat /bin/ls
+---------+----------------+------------+-----------+---------+
| Name | Size (bytes) | Pages | Cached | Percent |
|---------+----------------+------------+-----------+---------|
| /bin/ls | 133792 | 33 | 0 | 000.000 |
+---------+----------------+------------+-----------+---------+
内存泄露
- 应用程序可以访问的用户内存空间,由
只读段,数据段,堆,栈以及文件映射等组成。其中,堆和内存映射,需要应用程序来动态管理内存段,必须小心处理。- malloc()和free()通常并不是成对出现,而是需要在每个异常处理路径和成功路径上都释放内存
- 在多线程程序中,一个线程中分配的内存,可能会在另一个线程中访问和释放
- 更复杂的是,在第三方的库函数中,隐式分配的内存可能需要应用程序显式释放
- 内存泄露的危害非常大,这些忘记释放的内存,不仅应用程序自己不能访问,系统也不能把它们再次分配给其他应用。内存泄露不断累积,甚至会耗尽系统内存。
- 虽然,系统可以通过
OOM(Out of Memory)机制杀死进程,但进程在OOM前,可能已经引发了一连串的反应,导致严重的性能问题。比如:- 其他需要内存的进程,可能无法分配新的内存
- 内存不足,会触发系统的缓存回收,以及SWAP机制,从而进一步导致I/O的性能问题
- Linux下使用memleak,valgrind工具检查内存泄露
SWAP机制
- 除了缓存和缓冲区,通过内存映射获取的文件映射页,也是一种常见的
文件页。 - 大部分
文件页都可以直接回收,以后需要时,再从磁盘重新读取就可以了。而那些被应用程序修改过,并且暂时还没有写入磁盘的数据(即,脏页),就得先写入磁盘,然后才能进行内存释放。这些脏页一般通过两种方式写入磁盘。- 在应用程序中,通过系统调用
fsync,把脏页同步到磁盘中 - 交给系统,由内核线程
pdflush负责这些脏页的刷新
- 在应用程序中,通过系统调用
- SWAP机制:Linux通过SWAP,把不常访问的内存(即,匿名页)先写到磁盘中,然后释放掉这些内存,给其他更需要的进程使用。再次访问这些内存时,重新从磁盘读入内存就可以了。
SWAP原理:就是把一块磁盘空间或者一个本地文件,当成内存来使用。它包括换出和换入两个过程。 换出:把进程暂时不用的内存数据存储到磁盘中,并释放这些数据占用的内存。 换入:在进程再次访问这些内存的时候,把它们从磁盘读到内存中来。
例子:电脑休眠功能。也是基于SWAP。休眠时,把系统的内存存入磁盘,这样等到再次开机时,只要从磁盘中加载内存就可以,这样省去了很多应用程序的初始化过程,加速了开机速度。
Q: SWAP是为了回收内存,那么Linux到底在什么时候需要回收内存?
A:
- 直接内存回收。有新的大块内存分配请求,但是剩余内存不足,这个时候系统就需要回收一部分内存,进而尽可能地满足新内存请求。
- 除了方式1,还有一个专门的内核线程用来定期回收内存,也就是
kswapd0。为了衡量内存的使用情况,kswapd0定义了三个内存阈值(watermark,也称为水位),分别是:页最小阈值(pages_min),页低阈值(pages_low)和页高阈值(pages_high)。剩余内存,则使用pages_free表示。
kswapd0定期扫描内存的使用情况,并根据剩余内存落在这三个阈值的空间位置,进行内存的回收操作。
| 阈值范围 | 说明 |
|---|---|
| pages_free < pages_min | 进程可用内存都耗尽了,只有内核才可以分配内存 |
| pages_min < pages_free < pages_low | 内存压力比较大,pages_free不多了。这时kswapd0会执行内存回收,直到pages_free大于pages_high |
| pages_low < pages_free < pages_high | 内存有一定压力,但还可以满足新内存请求 |
| pages_free > pages_high | pages_free比较多,没有内存压力 |
可以看到,一旦pages_free小于pages_low,就会触发内存的回收。这个pages_low可以通过内核选项/proc/sys/vm/min_free_kbytes来间接设置。min_free_kbytes设置了pages_min,其他两个阈值,都是根据pages_min计算生成的,计算方法如下:
pages_low = pages_min * 5 / 4
pages_high = pages_min * 3 / 2
Q: 很多情况下,发现SWAP升高,可是在分析系统的内存使用时,却很可能发现系统剩余内存还多着呢,为什么剩余内存很多的情况下,也会发生SWAP?
A: 这是处理器的NUMA (Non-Uniform Memory Access)架构导致的。在NUMA架构下,多个处理器被划分到不同的Node下,且每个Node都拥有自己的本地内存空间。当本地内存不足时,默认既可以从其他Node寻找空闲内存,也可以从本地内存回收。可以设置/proc/sys/vm/zone_reclaim_mode来调整NUMA本地内存的回收策略。
$ numactl --hardware
available: 1 nodes (0)
node 0 cpus: 0 1
node 0 size: 7977 MB
node 0 free: 4416 MB
...
$ cat /proc/zoneinfo
...
Node 0, zone Normal
pages free 227894
min 14896
low 18620
high 22344
...
nr_free_pages 227894
nr_zone_inactive_anon 11082
nr_zone_active_anon 14024
nr_zone_inactive_file 539024
nr_zone_active_file 923986
...
Q: 内存回收包括文件页和匿名页,对文件页的回收,就是直接回收缓存或者把脏页写回磁盘后再回收;对匿名页的回收,就是通过SWAP机制,把它们写入磁盘后再释放内存。既然有两种不同的内存回收机制,在实际回收内存时,该先回收哪一种?
A: Linux提供了一个/proc/sys/vm/swappiness选项,取值0 - 100(表示调整SWAP积极程度的权重),用来调整使用SWAP的积极程度。
| swappiness程度 | 说明 |
|---|---|
| 数值越大 | 越积极使用SWAP,即更倾向于回收匿名页 |
| 数值越小 | 越消极使用SWAP,即更倾向于回收文件页 |
Q: SWAP如何开启?
A: 通过free命令可以查看SWAP是否开启。如果Swap的大小都是0,说明机器没有配置SWAP。
$ free
total used free shared buff/cache available
Mem: 8169348 331668 6715972 696 1121708 7522896
Swap: 0 0 0
开启SWAP的方法:Linux本身支持两种类型的SWAP,即SWAP分区和SWAP文件。以SWAP文件为例,配置开启SWAP:
# 创建 Swap 文件,这里配置SWAP文件的大小为8GB
$ fallocate -l 8G /mnt/swapfile
# 修改权限只有根用户可以访问
$ chmod 600 /mnt/swapfile
# 配置 Swap 文件
$ mkswap /mnt/swapfile
# 开启 Swap
$ swapon /mnt/swapfile
再次用free命令查看,确认SWAP配置成功。
$ free
total used free shared buff/cache available
Mem: 8169348 331668 6715972 696 1121708 7522896
Swap: 8388604 0 8388604
如果需要关闭SWAP,执行下面命令:
$ swapoff -a
实际上,关闭SWAP后再重新打开,也是一种常用的SWAP空间清理方法:
$ swapoff -a && swapon -a
Q: SWAP换出的是哪些进程的内存?
A: 通过proc文件系统来查看进程SWAP换出的虚拟内存大小。它保存在/proc/pid/status中的VmSwap中。
# 按 VmSwap 使用量对进程排序,输出进程名称、进程 ID 以及 SWAP 用量
$ for file in /proc/*/status ; do awk '/VmSwap|Name|^Pid/ {printf $2 " " $3} END{ print ""}' $file; done | sort -k 3 -n -r | head
dockerd 2226 10728 kB
docker-containe 2251 8516 kB
snapd 936 4020 kB
networkd-dispat 911 836 kB
polkitd 1004 44 kB
或者:
# apt install smem
# smem --sort swap
Q: 通常降低SWAP的使用,可以提高系统的整体性能,需要怎么做呢?
A: 几种常见的降低方法:
- 禁止SWAP。现在服务器的内存足够大,所以除非有必要,禁用SWAP就可以了。随着云计算的普及,大部分云平台中的虚拟机都默认禁止SWAP。
- 如果实在需要用到SWAP,可以尝试降低swappiness的值,减少内存回收时SWAP的使用倾向。
- 响应延迟敏感的应用,如果它们可能在开启SWAP的服务器中运行,可以用库函数mlock()或者mlockall()锁定内存,阻止它们的内存换出。
测试:当开启SWAP时,通过dd命令和sar命令查看SWAP指标的变化情况
模拟大文件的读取:
# 写入空设备,实际上只有磁盘的读请求
$ dd if=/dev/sda1 of=/dev/null bs=1G count=2048
在其他终端运行sar命令,查看内存各个指标的变化情况:
# 间隔 1 秒输出一组数据
# -r 表示显示内存使用情况,-S 表示显示 Swap 使用情况
$ sar -r -S 1
04:39:56 kbmemfree kbavail kbmemused %memused kbbuffers kbcached kbcommit %commit kbactive kbinact kbdirty
04:39:57 6249676 6839824 1919632 23.50 740512 67316 1691736 10.22 815156 841868 4
04:39:56 kbswpfree kbswpused %swpused kbswpcad %swpcad
04:39:57 8388604 0 0.00 0 0.00
04:39:57 kbmemfree kbavail kbmemused %memused kbbuffers kbcached kbcommit %commit kbactive kbinact kbdirty
04:39:58 6184472 6807064 1984836 24.30 772768 67380 1691736 10.22 847932 874224 20
04:39:57 kbswpfree kbswpused %swpused kbswpcad %swpcad
04:39:58 8388604 0 0.00 0 0.00
…
04:44:06 kbmemfree kbavail kbmemused %memused kbbuffers kbcached kbcommit %commit kbactive kbinact kbdirty
04:44:07 152780 6525716 8016528 98.13 6530440 51316 1691736 10.22 867124 6869332 0
04:44:06 kbswpfree kbswpused %swpused kbswpcad %swpcad
04:44:07 8384508 4096 0.05 52 1.27
通过/proc/zoneinfo观察剩余内存,内存阈值,以及匿名页和文件页的使用情况:
# -d 表示高亮变化的字段
# -A 表示仅显示 Normal 行以及之后的 15 行输出
$ watch -d grep -A 15 'Normal' /proc/zoneinfo
Node 0, zone Normal
pages free 21328
min 14896
low 18620
high 22344
spanned 1835008
present 1835008
managed 1796710
protection: (0, 0, 0, 0, 0)
nr_free_pages 21328
nr_zone_inactive_anon 79776
nr_zone_active_anon 206854
nr_zone_inactive_file 918561
nr_zone_active_file 496695
nr_zone_unevictable 2251
nr_zone_write_pending 0
可以发现,系统回收内存时,有时候会回收更多的文件页,有时候又回收更多的匿名页。通过/proc/sys/vm/swappiness选项设置内存回收的倾向。
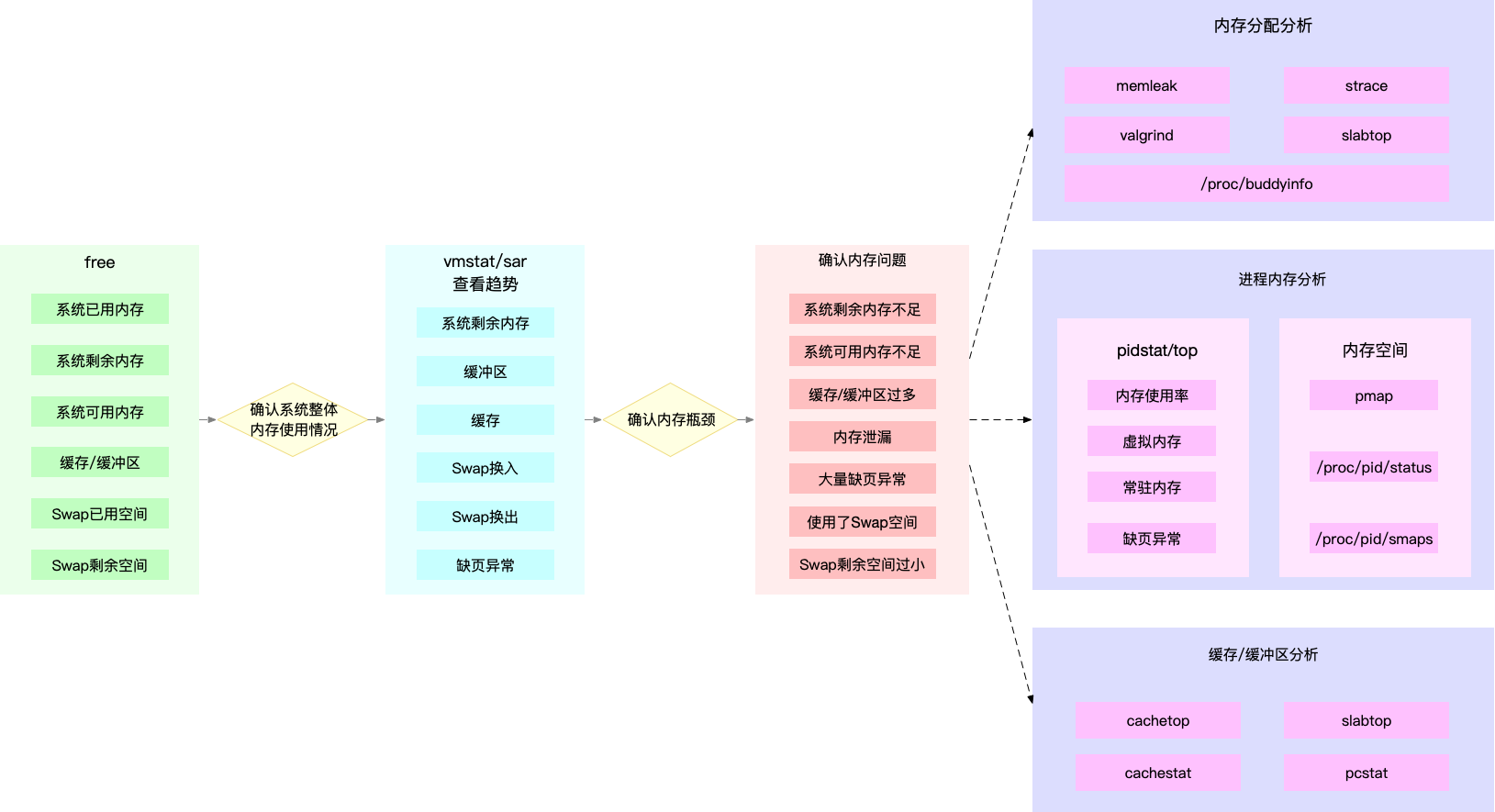
性能工具
- free
最常用的内存工具,可以查看系统的整体内存,和SWAP使用情况。
- vmstat
可以动态查看内存变化,还可以区分缓存和缓冲区,SWAP换入和换出的内存大小。
- cachestat
查看整个系统缓存的读写命中情况。
- cachetop
查看每个进程缓存的读写命中情况。
- memleak
检查内存泄露。
- sar
检查缓冲区,SWAP的使用情况。
- proc
/proc/zoneinfo
查看内存阈。
/proc/meminfo
# grep 表示只保留包含 active 的指标(忽略大小写)
# sort 表示按照字母顺序排序
$ cat /proc/meminfo | grep -i active | sort
Active(anon): 167976 kB
Active(file): 971488 kB
Active: 1139464 kB
Inactive(anon): 720 kB
Inactive(file): 2109536 kB
Inactive: 2110256 kB
/proc/pid/smaps
# 使用 grep 查找 Pss 指标后,再用 awk 计算累加值
$ grep Pss /proc/[1-9]*/smaps | awk '{total+=$2}; END {printf "%d kB\n", total }'
391266 kB
| 内存指标 | 性能工具 |
|---|---|
| 系统已用,可用,剩余内存 | free, vmstat, sar, /proc/meminfo |
| 进程虚拟内存,常驻内存,共享内存 | ps, top |
| 进程内存分布 | pmap |
| 进程SWAP换出内存 | top, /proc/pid/status |
| 进程缺页异常 | ps, top |
| 系统换页情况 | sar |
| 缓存/缓冲区用量 | free, vmstat, sar, cachestat |
| 缓存/缓冲区命中率 | cachetop |
| SWAP已用空间和剩余空间 | free, sar |
| SWAP换入换出 | vmstat |
| 内存泄露检测 | memleak, valgrind |
| 指定文件的缓存大小 | pcstat |
性能调优
优化思路:
- 最好禁止SWAP。如果必须开启SWAP,则降低swappiness的值,减少内存回收时SWAP的使用倾向。
- 减少内存的动态分配。比如,使用内存池,大页(HugePage)等。
- 尽量使用缓存和缓冲区访问数据。比如,可以使用堆栈明确声明内存空间,来存储需要缓存的数据;或者使用Redis这类外部缓存组件,优化数据的访问。
- 使用cgroups等方式限制进程的内存使用情况。这样确保系统内存不会被异常进程耗尽。
- 通过
/proc/pid/oom_adj,调整核心应用的oom_score。这样可以保证即使内存紧张,核心应用也不会被OOM杀死。
I/O相关
- 磁盘为系统提供了最基本的持久化存储。
- 文件系统则在磁盘的基础上,提供了一个用来管理文件的树状结构。
文件系统工作原理
索引节点和目录项
- 文件系统,是对存储设备上的文件,进行组织管理的机制。组织方式不同,就会形成不同的文件系统。
- Linux中一切皆文件。不仅普通的文件和目录,就连块设备,套接字,管道等,也都要通过统一的文件系统来管理。
- 为了方便管理,Linux文件系统为每个文件都分配了两个数据结构,索引节点(inode)和目录项(directory entry),它们主要用来记录文件的元信息和目录结构。
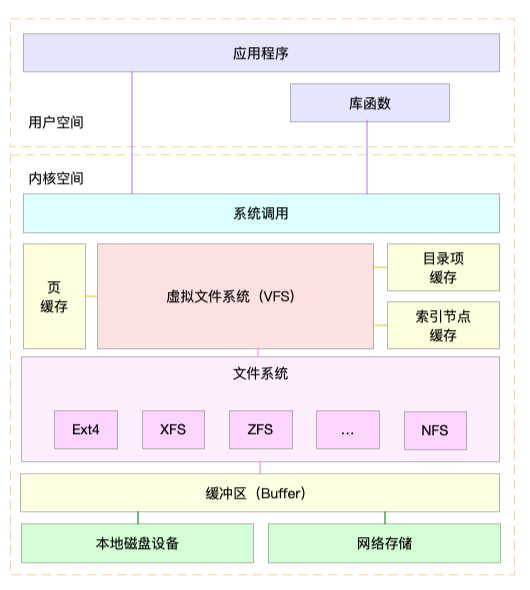
虚拟文件系统
为了支持不同的文件系统,Linux内核在用户进程和文件系统中间,又引入了一个抽象层,也就是虚拟文件系统VFS(Virtual File System)。VFS定义了一组所有文件系统都支持的数据结构和标准接口。这样,用户进程和内核中的其他子系统,只需要跟VFS提供的统一接口进行交互就可以了,而不需要再关心底层各种文件系统的实现细节。
VFS内部通过目录项,索引节点,逻辑块,以及超级块等数据结构来管理文件。
- 目录项。记录了文件的名字,以及文件与其他目录项之间的目录关系。
- 索引节点。记录了文件的元数据。
- 逻辑块。是由连续磁盘扇区构成的最小读写单元,用来存储文件数据。
- 超级块。用来记录文件系统整体的状态,如索引节点和逻辑块的使用情况。
文件系统I/O
int open(const char *pathname, int flags, mode_t mode);
ssize_t read(int fd, void *buf, size_t count);
ssize_t write(int fd, const void *buf, size_t count);
文件读写方式的各种差异,导致I/O的分类多种多样:
- 缓冲与非缓冲I/O
- 缓冲I/O,利用标准库缓存来加速文件的访问,而标准库内部再通过系统调用访问文件。比如,程序遇到换行符时才真正输出,而换行前的内容就是被标准库暂时缓存了起来
- 非缓冲I/O,直接通过系统调用访问文件
- 无论缓冲I/O还是非缓冲I/O,它们最终还是要经过系统调用来访问文件,而系统调用后,还会通过页缓存来减少磁盘I/O操作。
- 直接与非直接I/O
- 直接I/O,指跳过操作系统的页缓存,直接跟文件系统交互来访问文件。(指定O_DIRECT标志实现直接I/O,否则默认是非直接I/O)
- 非直接I/O,文件读写时,先要经过系统的页缓存,然后再由内核或额外的系统调用,真正写入磁盘
- 阻塞与非阻塞I/O
- 阻塞I/O,指应用程序执行I/O操作后,如果没有获得响应,就会阻塞当前线程,自然就不能执行其他任务 (指定O_NONBLOCK标志)
- 非阻塞I/O,指应用程序执行I/O操作后,不会阻塞当前的线程,可以继续执行其他任务,随后再通过轮询,获取调用的结果
- 同步与异步I/O
- 同步I/O,指应用程序执行I/O操作后,要一直等到整个I/O完成后,才能获得I/O响应
- 异步I/O,指应用程序执行I/O操作后,不用等待完成和完成后的响应,而是继续执行就可以。等到这次I/O完成后,响应会用事件通知的方式告诉应用程序
磁盘I/O工作原理
磁盘是可以持久化存储的设备。
- 根据存储介质的不同,常见磁盘可以分为两类:机械磁盘和固态磁盘。
- 机械磁盘。也称为硬盘驱动器(Hard Disk Driver, HDD)。机械磁盘主要由盘片和读写磁头组成,数据就存储在盘片的环状磁道中。在读写数据前,需要移动读写磁头,定位到数据所在的磁道,然后才能访问数据。
- 如果I/O请求刚好连续,那就不需要磁道寻址,自然可以获得最佳性能。(连续I/O的工作原理)
- 与之对应就是随机I/O,它需要不停地移动磁头来定位数据位置,所以读写速度就会比较慢。
- 机械磁盘的最小读写单位是扇区,一般大小为512字节。
- 固态磁盘(Solid State Disk, SSD)。由固态电子元器件组成。固态磁盘不需要磁道寻址,所以,不管是连续I/O还是随机I/O的性能,都比机械磁盘要好的多。但是,随机I/O会导致大量的垃圾回收,以及连续I/O可以通过预读的方式减少I/O请求次数,因此,优化I/O性能都会采用连续I/O。
- 固态磁盘的最小读写单位是页,一般大小为4KB,8KB等。
- 机械磁盘。也称为硬盘驱动器(Hard Disk Driver, HDD)。机械磁盘主要由盘片和读写磁头组成,数据就存储在盘片的环状磁道中。在读写数据前,需要移动读写磁头,定位到数据所在的磁道,然后才能访问数据。
- 根据接口来分类。不同的接口,往往分配不同的设备名称。比如,IDE设备会分配一个
hd前缀的设备名,SCSI和SATA设备会分配一个sd前缀的设备名。如果是多种同类型的磁盘,就会按照a,b,c等字母顺序来编号。- IDE (Integrated Drive Electronics)
- SCSI (Small Computer System Interface)
- SAS (Serial Attached SCSI)
- SATA (Serial ATA)
- 根据不同的使用方式,可以把它们划分为多种不同的架构。
- 直接作为独立磁盘设备来使用。这些磁盘往往会根据需要划分为不同的逻辑分区,每个分区再用数字编号。比如,/dev/sda还可以分成/dev/sda1和/dev/sda2
- 把多块磁盘组合成一个逻辑磁盘,构成冗余独立磁盘阵列,即,RAID (Redundant Array of Independent Disks),从而可以提高数据访问的性能,并且提高数据存储的可靠性。根据容量,性能和可靠性需求不同,RAID一般可以划分为多个级别。
- RAID0。有最优的读写性能,但不提供数据冗余的功能
- 而其他级别的RAID,在提供数据冗余的基础上,对读写性能也有一定程度的优化
- 把这些磁盘组合成一个网络存储集群,再通过NFS, SMB, iSCSI等网络存储协议暴露给服务器使用。
其实,在Linux中,磁盘实际上是作为一个块设备来管理的。也就是以块为单位读写数据,并且支持随机读写。每个块设备都会被赋予两个设备号,分别是主,次设备号。主设备号用在驱动程序中,用来区分设备类型;而次设备号则是用来给多个同类设备编号。
通用块层
与VFS类似,为了减少不同块设备的差异带来的影响,Linux通过一个统一的通用块层,来管理各种不同的块设备。通用块层,是处在文件系统和磁盘驱动中间的一个块设备抽象层,它主要有两个功能:
- 向上,为文件系统和应用程序,提供访问块设备的标准接口;向下,把各种异构的磁盘设备抽象为统一的块设备,并提供统一框架管理这些设备的驱动程序。
- 给文件系统和应用程序发来的I/O请求排队,并通过重新排队,请求合并等方式,提高磁盘读写的效率。
对I/O请求排序的过程,也就是I/O调度。Linux内核支持四种I/O调度算法:
- NONE。不使用任何I/O调度器,常用在虚拟机中(此时磁盘I/O调度完全由物理机负责)
- NOOP。先入先出的队列,只做一些最基本的请求合并,常用于SSD磁盘
- CFQ (Completely Fair Scheduler)。完全公平调度器,是现在很多发行版的默认I/O调度器,它为每个进程维护了一个I/O调度队列,并按照时间片来均匀分布每个进程的I/O请求
- DeadLine。分别为读,写请求创建不同的I/O队列,可以提高机械磁盘的吞吐量,并确保达到最终期限的请求被优先处理。此调度算法多用在I/O压力比较重的场景,比如,数据库等。
I/O栈
可以把Linux存储系统的I/O栈,由上到下分为三个层次:
- 文件系统层。包括虚拟文件系统,和其他各种文件系统的具体实现。它为上层的应用程序提供标准的文件访问接口,对下会通过通用块层,来存储和管理磁盘数据。
- 通用块层。包括设备I/O队列和I/O调度器。它会对文件系统的I/O请求进行排队,再通过重新排序和请求合并,然后才要发送给下一级的设备层。
- 设备层。包括存储设备和相应的驱动程序,负责最终物理设备的I/O操作。
磁盘I/O的性能指标
五个常见的指标:
- 使用率。磁盘处理I/O的时间百分比。(注意,使用率只考虑有没有I/O,而不考虑I/O的大小。当使用率为100%的时候,磁盘依然有可能接受新的I/O请求)
- 饱和度。磁盘处理I/O的繁忙程度。(注意,当饱和度为100%时,磁盘无法接受新的I/O请求。饱和度一般没法直接观测到,所以一般是通过实际观测值跟基准测试结果对比来分析)
- IOPS (Input/Output Per Second)。每秒的I/O请求数。
- 吞吐量。每秒的I/O请求大小。
- 响应时间。I/O请求从发出到收到响应的间隔时间。
注意:不能孤立的看待这些指标,而要结合读写比例,I/O类型(随机,连续),以及I/O大小综合来分析。比如,在数据库,大量小文件等这类随机读写比较多的场景中,IOPS更能反映系统的整体性能;而在多媒体等顺序读写比较多的场景中,吞吐量才更能反映系统的整体性能。
一般,在为应用程序的服务器选型时,要先对磁盘的I/O性能进行基准测试,以便可以准确评估,磁盘性能是否可以满足应用程序的需求。推荐使用性能测试工具fio,来测试磁盘的IOPS,吞吐量,以及响应时间等核心指标。当然,需要测试出,不同I/O大小(一般是512B至1MB中间的若干值)分别在随机读,顺序读,随机写,顺序写等各种场景下的性能情况。用性能工具得到这些指标,可以作为后续分析应用程序性能的依据,一旦发现性能问题,就可以把它们作为磁盘性能的极限值,进而评估磁盘I/O的使用情况。
性能工具
磁盘I/O观测
观测每块磁盘的使用情况,常用iostat工具,其指标数据来自于/proc/diskstats。
# -d -x 表示显示所有磁盘 I/O 的指标
$ iostat -dx 1
Device r/s w/s rkB/s wkB/s rrqm/s wrqm/s %rrqm %wrqm r_await w_await aqu-sz rareq-sz wareq-sz svctm %util
loop0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
loop1 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
sda 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
sdb 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
各指标含义如下:
| 指标 | 含义 |
|---|---|
| Device | 磁盘设备的名字 |
| r/s | 每秒发送给磁盘的读请求数 (合并后的请求数) |
| w/s | 每秒发送给磁盘的写请求数 (合并后的请求数) |
| rkB/s | 每秒从磁盘读取的数据量 (单位为kB) |
| wkB/s | 每秒从磁盘写入的数据量 (单位为kB) |
| rrpm/s | 每秒合并的读请求数 (%rrqm/s表示合并读请求的百分比) |
| wrpm/s | 每秒合并的写请求数 (%wrqm/s表示合并写请求的百分比) |
| r_await | 读请求处理完成等待时间 (包括队列中的等待时间和设备实际处理的时间,单位为毫秒) |
| w_await | 写请求处理完成等待时间 (包括队列中的等待时间和设备实际处理的时间,单位为毫秒) |
| aqu-sz | 平均请求队列长度 |
| rareq_sz | 平均读请求大小 (单位为kB) |
| wareq-sz | 平均写请求大小 (单位为kB) |
| svctm | 处理I/O请求所需的平均时间 (不包括等待时间),单位为毫秒,注意这是推断的数据,并不保证完全准确 |
| %util | 磁盘处理I/O的时间百分比 (即,使用率,由于可能存在并行I/O,100%并不一定表明磁盘I/O饱和) |
%util = 磁盘的I/O使用率
r/s + w/s = IOPS
rkB/s + wkB/s = 吞吐量
r_await + w_await = 响应时间
https://linux.die.net/man/1/iostat
进程I/O观测
除了每块磁盘的I/O情况,每个进程的I/O情况也是需要关注的重点。可以使用pidstat和iotop工具来查看进程的I/O情况。
$ pidstat -d 1
13:39:51 UID PID kB_rd/s kB_wr/s kB_ccwr/s iodelay Command
13:39:52 102 916 0.00 4.00 0.00 0 rsyslogd
各指标含义如下:
| 指标 | 含义 |
|---|---|
| UID | 用户ID |
| PID | 进程ID |
| kB_rd/s | 每秒读取的数据大小 (单位是kB) |
| kB_wr/s | 每秒写入的数据大小 (单位是kB) |
| kB_ccwr/s | 每秒取消的写请求数据大小 (单位是kB) |
| iodelay | 块I/O延迟,包括等待同步块I/O和换入块I/O结束的时间,单位是时钟周期 |
$ iotop
Total DISK READ : 0.00 B/s | Total DISK WRITE : 7.85 K/s
Actual DISK READ: 0.00 B/s | Actual DISK WRITE: 0.00 B/s
TID PRIO USER DISK READ DISK WRITE SWAPIN IO> COMMAND
15055 be/3 root 0.00 B/s 7.85 K/s 0.00 % 0.00 % systemd-journald
注意,前两行分别表示,进程的磁盘读写大小总数和磁盘真实的读写大小总数。因为缓存,缓冲区,I/O合并等因素的影响,它们可能并不相等。
I/O基准测试
为了更客观合理地评估优化效果,首先应该对磁盘和文件系统进行基准测试,得到文件系统或磁盘I/O的极限性能。
fio (Flexible I/O Tester)是最常用的文件系统和磁盘I/O性能基准测试工具。
几个常见场景的测试方法:
# 随机读
fio -name=randread -direct=1 -iodepth=64 -rw=randread -ioengine=libaio -bs=4k -size=1G -numjobs=1 -runtime=1000 -group_reporting -filename=/dev/sdb
# 随机写
fio -name=randwrite -direct=1 -iodepth=64 -rw=randwrite -ioengine=libaio -bs=4k -size=1G -numjobs=1 -runtime=1000 -group_reporting -filename=/dev/sdb
# 顺序读
fio -name=read -direct=1 -iodepth=64 -rw=read -ioengine=libaio -bs=4k -size=1G -numjobs=1 -runtime=1000 -group_reporting -filename=/dev/sdb
# 顺序写
fio -name=write -direct=1 -iodepth=64 -rw=write -ioengine=libaio -bs=4k -size=1G -numjobs=1 -runtime=1000 -group_reporting -filename=/dev/sdb
参数说明:
| 参数名称 | 含义 |
|---|---|
| direct | 表示是否跳过缓存。设置1表示跳过系统缓存 |
| iodepth | 表示使用异步I/O (asynchronous I/O)时,同时发出的I/O请求上限 |
| rw | 表示I/O模式。read/write分别表示顺序读/写;randread/randwrite分别表示随机读/写 |
| ioengine | 表示I/O引擎,支持同步(sync),异步(libaio),内存映射(mmap),网络(net)等各种I/O引擎 |
| bs | 表示I/O的大小 |
| filename | 表示文件路径,可以是磁盘路径(测试磁盘性能),也可以是文件路径(测试文件系统性能)。注意:用磁盘路径测试写,会破坏这个磁盘的文件系统,所以在使用前需要做好数据备份 |
fio支持I/O重放,可以得到应用程序I/O模式的基准测试报告:
# 使用 blktrace 跟踪磁盘 I/O,注意指定应用程序正在操作的磁盘
$ blktrace /dev/sdb
# 查看 blktrace 记录的结果
# ls
sdb.blktrace.0 sdb.blktrace.1
# 将结果转化为二进制文件
$ blkparse sdb -d sdb.bin
# 使用 fio 重放日志
$ fio --name=replay --filename=/dev/sdb --direct=1 --read_iolog=sdb.bin
性能调优
应用程序优化:
- 用追加写代替随机写,减少寻址开销,加快I/O写的速度。
- 借助缓存I/O,充分利用系统缓存,降低实际I/O的次数。
- 在应用程序内部构建自己的缓存,或者用Redis这类外部缓存系统。
- 在需要频繁读写同一块磁盘空间时,可以用mmap代替read/write,减少内存的拷贝次数。
- 在需要同步写的场景中,尽量将写请求合并,而不是让每个请求都同步写入磁盘,即可以用fsync()取代O_SYNC。
- 在多个应用程序共享相同磁盘时,为了保证I/O不被某个应用程序完全占用,推荐使用cgroups的I/O子系统,来限制进程、进程组的IOPS以及吞吐量。
- 在使用CFQ调度器时,可以用ionice来调整进程的I/O调度优先级,特别是提高核心应用的I/O优先级。
文件系统优化:
- 可以根据实际负载场景的不同,选择最合适的文件系统。比如,Ubuntu默认使用ext4文件系统,CentOS 7默认使用xfs文件系统。相比于ext4,xfs支持更大的磁盘分区和更大的文件数量,如,xfs支持大于16TB的磁盘,但是缺点在于无法收缩,而ext4可以。
- 在选好文件系统后,可以进一步优化文件系统的配置选项,包括文件系统的特性,日志模式,挂载选项等。
- 优化文件系统的缓存。
- 在不需要持久化时,还可以用内存文件系统tmpfs,以获得更好的I/O性能。比如,/dev/shm/,就是大多数Linux默认配置的一个内存文件系统,它的大小默认为总内存的一半。
磁盘优化:
- 换用性能更好的磁盘,比如,用SSD替代HDD。
- 可以使用RAID,把多块磁盘组合成一个逻辑磁盘,构成冗余独立磁盘阵列。
- 针对磁盘和应用程序模式的特征,可以选择最合适的I/O调度算法。
- 可以对应用程序的数据,进行磁盘级别的隔离。
- 在顺序读比较多的场景中,可以增大磁盘的预读数据。
- 可以优化内核块设备I/O的选项。
- 防止磁盘硬件错误。
网络相关
网络模型
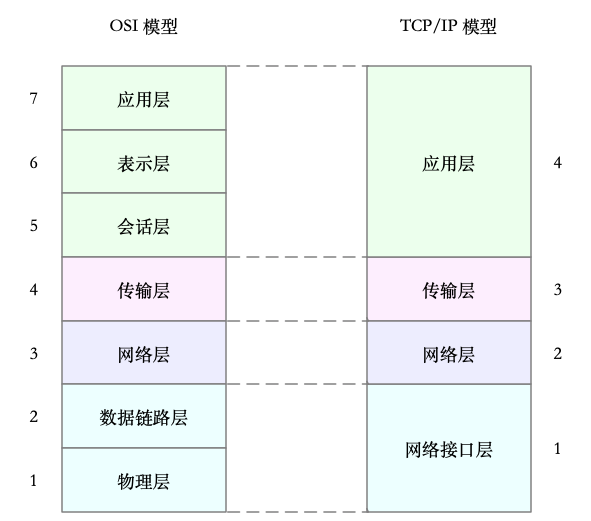
开放式系统互联通信参考模型(Open System Interconnection reference Model),简称为OSI网络模型。为了解决网络互联中,异构设备的兼容性问题,并解耦复杂的网络包处理流程,OSI模型把网络互联的框架分为七层,每层负责不同的功能。
| 名称 | 作用 |
|---|---|
| 应用层 | 负责为应用程序提供统一的接口 |
| 表示层 | 负责把数据转换成兼容接收系统的格式 |
| 会话层 | 负责维护计算机之间的通信连接 |
| 传输层 | 负责为数据加上传输表头,形成数据包 |
| 网络层 | 负责数据的路由和转发 |
| 数据链路层 | 负责MAC寻址,错误侦测和改错 |
| 物理层 | 负责在物理网络中传输数据帧 |
但是,OSI模型太复杂,也没能提供一个可实现的方法。所以,在Linux中,实际上使用的是另一个更实用的四层模型,即,TCP/IP网络模型。
| 名称 | 作用 |
|---|---|
| 应用层 | 负责向用户提供一组应用程序,比如,HTTP, FTP, DNS等 |
| 传输层 | 负责端到端的通信,比如,TCP, UDP等 |
| 网络层 | 负责网络包的封装,寻址和路由,比如,IP, ICMP等 |
| 网络接口层 | 负责网络包在物理网络中的传输,比如,MAC寻址,错误侦测,以及通过网卡传输网络帧等 |
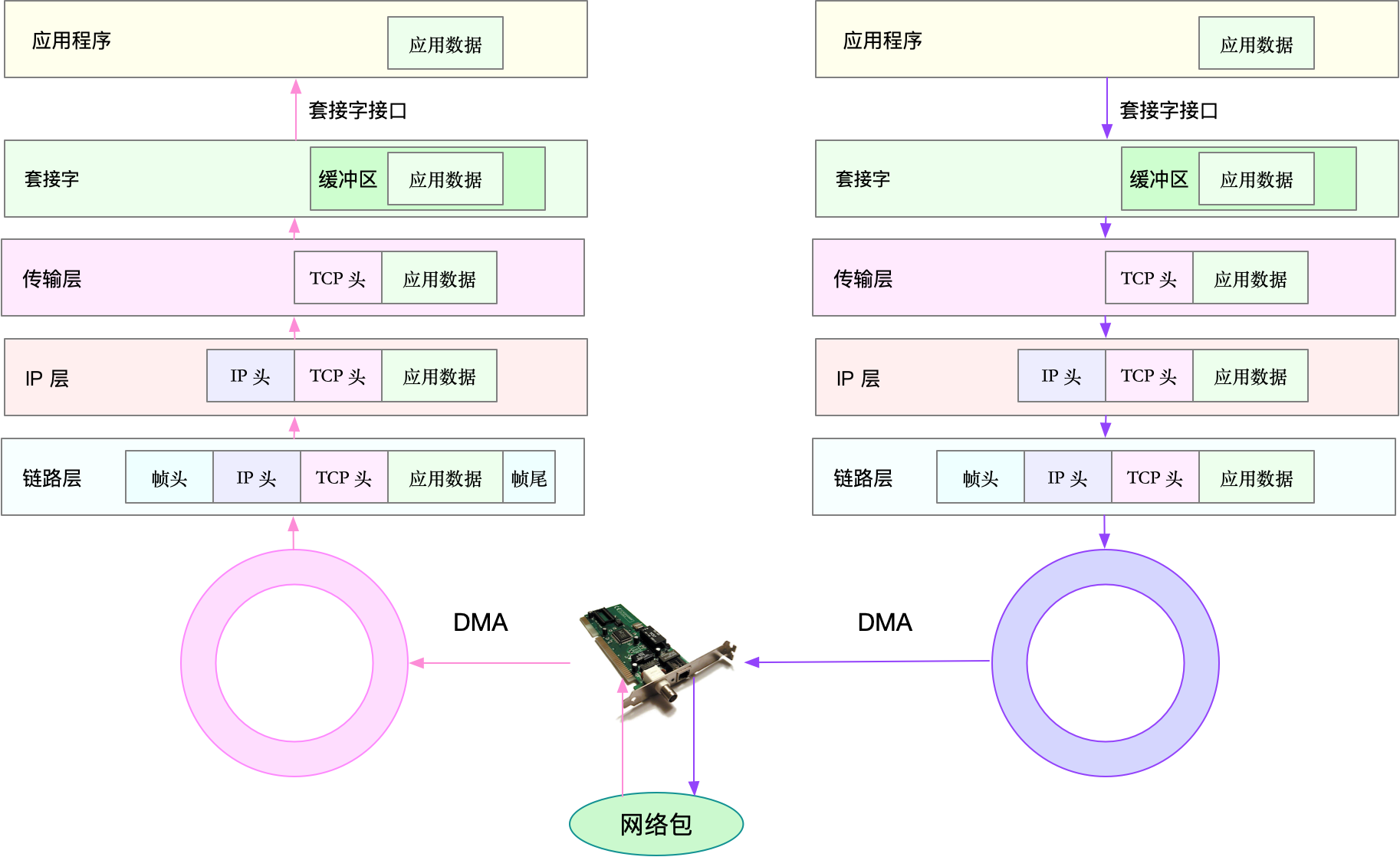
Linux网络收发流程
Linux是怎么收发网络包的?
注意,以下以物理网卡为例,事实上,Linux还支持众多的虚拟网络设备,而它们的网络收发流程会有一些差别。
接收流程
当一个网络帧达到网卡后,网卡会通过DMA方式,把这个网络包放到收包队列中,然后通过硬中断,告诉中断处理程序已经收到了网络包。接着,网卡中断处理程序会为网络帧分配内核数据结构(sk_buff),并将其拷贝到sk_buff缓冲区中,然后再通过软中断,通知内核收到了新的网络帧。接下来,内核协议栈从缓冲区中取出网络帧,并通过网络协议栈,从下到上逐层处理这个网络帧。
- 在链路层检查报文的合法性,找出上层协议的类型(IPv4还是IPv6),再去掉帧头,帧尾,然后交给网络层。
- 网络层取出IP头,判断网络包下一步的走向,比如,是交给上层处理,还是转发。当网络层确认这个包是要发送到本机后,就会取出上层协议的类型(TCP还是UDP),去掉IP头,再交给传输层处理。
- 传输层取出TCP头或者UDP头后,根据<源IP, 源端口, 目的IP, 目的端口>四元组作为标识,找出对应的Socket,并把数据拷贝到Socket的接收缓存中。
- 最后,应用程序就可以使用Socket接口,读取到新接收的数据了。
发送流程
- 应用程序调用Socket API发送网络包。这是一个系统调用,所以会陷入到内核态的套接字层中,套接字层会把数据包放到Socket发送缓冲区中。
- 接下来,网络协议栈从Socket发送缓冲区中,取出数据包;再按照TCP/IP栈,从上到下逐层处理。传输层为其增加TCP头,网络层为其增加IP头,执行路由查找确认下一跳的IP,并按照MTU大小进行分片。
- 分片后的网络包,再送到网络接口层,进行物理地址寻址,以找到下一跳的MAC地址。然后添加帧头和帧尾,放到发包队列中。这一切完成后,会有软中断通知驱动程序,发包队列中有新的网络帧需要发送。最后,驱动程序通过DMA,从发包队列中读出网络帧,并通过物理网卡把它发送出去。
性能指标
| 指标 | 含义 |
|---|---|
| 带宽 | 表示链路的最大传输速率,单位通常为b/s(比特/秒) |
| 吞吐量 | 表示没丢包时的最大数据传输速率。吞吐量/带宽 = 网络使用率 |
| 延时 | 表示从网络请求发出后,一直到收到远端响应,所需要的时间延迟。在不同场景中,这一指标可能含义不同 |
| PPS (Packet Per Second) | 表示以网络包为单位的传输速率 |
网络配置
ifconfig和ip分别属于软件包net-tools和iproute2,iproute2是net-tools的下一代。推荐使用ip工具。
$ ifconfig eth0
eth0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 10.240.0.30 netmask 255.240.0.0 broadcast 10.255.255.255
inet6 fe80::20d:3aff:fe07:cf2a prefixlen 64 scopeid 0x20<link>
ether 78:0d:3a:07:cf:3a txqueuelen 1000 (Ethernet)
RX packets 40809142 bytes 9542369803 (9.5 GB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 32637401 bytes 4815573306 (4.8 GB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
$ ip -s addr show dev eth0
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP group default qlen 1000
link/ether 78:0d:3a:07:cf:3a brd ff:ff:ff:ff:ff:ff
inet 10.240.0.30/12 brd 10.255.255.255 scope global eth0
valid_lft forever preferred_lft forever
inet6 fe80::20d:3aff:fe07:cf2a/64 scope link
valid_lft forever preferred_lft forever
RX: bytes packets errors dropped overrun mcast
9542432350 40809397 0 0 0 193
TX: bytes packets errors dropped carrier collsns
4815625265 32637658 0 0 0 0
- 网络接口状态标志。ifconfig输出中的
RUNNING,或者ip输出中的LOWER_UP都表示物理网络层是连通的,即网卡已经连接到了交换机或者路由器中。如果看不到,通常表示网线被拔掉了。 - MTU的大小。MTU默认大小是1500,根据网络架构的不同,可能需要调整MTU的数值。
- 网络接口的IP地址,子网,以及MAC地址。
- 网络收发的字节数,包数,错误数,以及丢包情况。
- errors,表示发生错误的数据包数,比如,校验错误,帧同步错误等
- dropped,表示丢弃的数据包数,即数据包已经收到了Ring Buffer,但因为内存不足等原因丢包
- overruns,表示超限数据包数,即网络I/O速度过快,导致Ring Buffer中的数据包来不及处理(队列满)而导致的丢包
- carrier,表示发生carrier错误的数据包数,比如,双工模式不匹配,物理电缆出现问题等
- collisions,表示碰撞数据包数
套接字信息
除了ifconfig和ip只显示了网络接口收发数据包的统计信息,网络协议栈中的统计信息也需要关注。可以使用netstat或ss来查看套接字,网络栈,网络接口以及路由表的信息。推荐使用ss来查询网络的连接信息,因为它比netstat速度更快。
# head -n 3 表示只显示前面 3 行
# -l 表示只显示监听套接字
# -n 表示显示数字地址和端口 (而不是名字)
# -p 表示显示进程信息
$ netstat -nlp | head -n 3
Active Internet connections (only servers)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 0 0 127.0.0.53:53 0.0.0.0:* LISTEN 840/systemd-resolve
# -l 表示只显示监听套接字
# -t 表示只显示 TCP 套接字
# -n 表示显示数字地址和端口 (而不是名字)
# -p 表示显示进程信息
$ ss -ltnp | head -n 3
State Recv-Q Send-Q Local Address:Port Peer Address:Port
LISTEN 0 128 127.0.0.53%lo:53 0.0.0.0:* users:(("systemd-resolve",pid=840,fd=13))
LISTEN 0 128 0.0.0.0:22 0.0.0.0:* users:(("sshd",pid=1459,fd=3))
都展示了,套接字的状态,接收队列,发送队列,本地地址,远端地址,进程PID和进程名称等。
注意,Recv-Q和Send-Q通常应该为0,当不为0时,说明有网络包的堆积发生。但在不同套接字状态下的含义不同。
- 当套接字处于连接状态(Established)时
- Recv-Q表示套接字缓冲还没有被应用程序取走的字节数
- Send-Q表示还没有被远端主机确认的字节数
- 当套接字处于监听(Listening)时
- Recv-Q表示syn backlog的当前值
- Send-Q表示最大的syn backlog值
半连接。syn backlog是TCP协议栈中的半连接队列长度(即,还没有完成TCP三次握手的连接,连接只进行了一半,而服务器收到了客户端的SYN包后,就会把这个连接放到半连接队列中,然后再向客户端发送SYN+ACK包),相应的也有一个全连接队列(accept queue),它们都是维护TCP状态的重要机制。
全连接。是指服务器收到了客户端的ACK,完成了TCP三次握手,然后就会把这个连接挪到全连接队列中。这些全连接中的套接字,还需要再被accept()系统调用取走,这样服务器就可以开始真正处理客户端的请求了。
协议栈统计信息
使用netstat可以展示,TCP协议的主动连接,被动连接,失败重试,发送和接收的分段数量等各种信息。
$ netstat -s
...
Tcp:
3244906 active connection openings
23143 passive connection openings
115732 failed connection attempts
2964 connection resets received
1 connections established
13025010 segments received
17606946 segments sent out
44438 segments retransmitted
42 bad segments received
5315 resets sent
InCsumErrors: 42
...
$ ss -s
Total: 186 (kernel 1446)
TCP: 4 (estab 1, closed 0, orphaned 0, synrecv 0, timewait 0/0), ports 0
Transport Total IP IPv6
* 1446 - -
RAW 2 1 1
UDP 2 2 0
TCP 4 3 1
...
网络吞吐和PPS
使用sar -n查看网络的统计信息。
# 数字 1 表示每隔 1 秒输出一组数据
$ sar -n DEV 1
Linux 4.15.0-1035-azure (ubuntu) 01/06/19 _x86_64_ (2 CPU)
13:21:40 IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s %ifutil
13:21:41 eth0 18.00 20.00 5.79 4.25 0.00 0.00 0.00 0.00
13:21:41 docker0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
13:21:41 lo 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
使用ethtool来查询带宽:(注意,单位是比特,小写字母b)
# 一个千兆网卡
$ ethtool eth0 | grep Speed
Speed: 1000Mb/s
连通性和延时
使用ping来测试远程主机的连通性和延时,而这是基于ICMP协议。
# -c3 表示发送三次 ICMP 包后停止
$ ping -c3 114.114.114.114
PING 114.114.114.114 (114.114.114.114) 56(84) bytes of data.
64 bytes from 114.114.114.114: icmp_seq=1 ttl=54 time=244 ms
64 bytes from 114.114.114.114: icmp_seq=2 ttl=47 time=244 ms
64 bytes from 114.114.114.114: icmp_seq=3 ttl=67 time=244 ms
--- 114.114.114.114 ping statistics ---
3 packets transmitted, 3 received, 0% packet loss, time 2001ms
rtt min/avg/max/mdev = 244.023/244.070/244.105/0.034 ms
- 第一部分,是每个ICMP请求的信息。包括,ICMP序列号(icmp_seq),TTL(生存时间或者跳数),往返延时。
- 第二部分,是三次ICMP请求的汇总。
C10K和C1000K问题
C10K和C1000K的首字母C是Client的缩写。C10K就是单机同时处理1万个请求(并发连接1万)的问题,而C1000K就是单机支持处理100万个请求(并发连接100万)的问题。
C10K
The C10K problem最早由Dan Kegel在1999年提出。那时的服务器还只是32位系统,运行着Linux2.2版本,只配置了很少的内存(2GB)和千兆网卡。怎么在这样的系统中支持并发1万的请求呢?
从资源上说,对2GB内存和千兆网卡的服务器来说,同时处理1万个请求,只要每个请求处理占用不到200KB的内存和100Kbit的网络带宽就可以。所以,物理资源是足够的,接下来自然是软件的问题,特别是网络的I/O模型问题。
在C10K以前,Linux中网络处理都用同步阻塞的方式,也就是每个请求都分配一个进程或线程。请求数只有100时,这种方式没有问题,但增加到1万个请求时,1万个进程或线程的调度,上下文切换,它们占用的内存都会成为瓶颈。既然每个请求分配一个线程的方式不合适,那么,为了支持1万个并发请求,这里就有两个问题需要我们解决。
问题1:怎样在一个线程内处理多个请求,也就是要在一个线程内响应多个网络I/O。以前的同步阻塞方式下,一个线程只能处理一个请求,到这里不再适用。是不是可以用非阻塞I/O或异步I/O来处理多个网络请求?
问题2:怎么更节省资源地处理客户请求,也就是要用更少的线程来服务这些请求。是不是可以继续使用原来的100个或更少的线程来服务现在的1万个请求?
I/O模型优化
使用I/O多路复用。两种I/O事件通知的方式:
-
水平触发。只要文件描述符可以非阻塞地执行I/O,就会触发通知。即,应用程序可以随时检查文件描述符的状态,然后再根据状态进行I/O操作。
-
边缘触发。只有在文件描述符的状态发生改变时,才发送一次通知。这时候,应用程序需要尽可能多地执行I/O,直到无法继续读写,才可以停止。如果I/O没有执行完,或者因为某种原因没来得及处理,那么这次通知也就丢失了。
具体的实现方法
方法1:非阻塞I/O和水平触发通知(比如,使用selelct或poll)
根据水平触发的原理,select和poll需要从文件描述符列表中,找出哪些可以执行I/O,然后进行真正的网络I/O读写。由于I/O是非阻塞的,一个线程中就可以同时监控一批套接字的文件描述符,这样就达到了单线程处理多请求的目的。
优点:对应用程序比较友好,API简单。 缺点:
- 应用程序使用select和poll时,需要对这些文件描述符列表进行轮询,这样请求数多的时候就会比较耗时。
- select使用固定长度的位相量,表示文件描述符的集合,因此会有最大描述符数量的限制。比如,在32位系统中,默认限制是1024。并且,在select内部,检查套接字状态是用轮询的方法,再加上应用程序使用时的轮询,就变成了一个O(N^2)的关系。
- poll改进了select的表示方法,换成了一个没有固定长度的数组,这样就没有了最大描述符数量的限制(当然还会受到系统文件描述符限制)。但应用程序在使用poll时,同样需要对文件描述符列表进行轮询,这样,处理时耗跟描述符数量是O(N)的关系。
- 应用程序每次调用select和poll时,需要把文件描述符的集合,从用户空间传入内核空间,由内核修改后再传出到用户空间。这一来一回的内核空间与用户空间的切换,也增加了处理成本。
方法2:非阻塞I/O和边缘触发通知(比如,epoll)
- epoll是在Linux 2.6中才新增的功能(2.4虽然也有,但功能不完善)
- epoll使用红黑树,在内核中管理文件描述符的集合,这样就不需要应用程序在每次操作时都传入,传出这个集合。
- epoll使用事件驱动的机制,只关注有I/O事件发生的文件描述符,不需要轮询扫描整个集合。
- 由于边缘触发只在文件描述可读或可写事件发生时才通知,那么应用程序就需要尽可能多地执行I/O,并要处理更多的异常事件。
方法3:使用异步I/O(Asynchronous I/O,AIO)
- 异步I/O运行应用程序同时发起很多I/O操作,而不用等待这些操作完成。而在I/O完成后,系统会用事件通知(比如,信号或回调函数)的方式告诉应用程序,这时,应用程序才会去查询I/O操作的结果。
- 异步I/O也是到了Linux 2.6才支持,并且不太完善,使用难度比较高。
工作模型优化
第1种:主进程 + 多个worker子进程
- 主进程执行bind() + listen()后,创建多个子进程。
- 然后,在每个子进程中,都通过accept()或epoll_wait(),来处理相同的套接字。
比如,常见的反向代理服务器Nginx就是这么工作的。它也是由主进程和多个worker进程组成。主进程主要用来初始化套接字,并管理子进程的生命周期;而worker进程,则负责实际的请求处理。
注意:这种方式,在accept()或epoll_wait()调用时,存在一个惊群的问题。当网络I/O事件发生时,多个进程被同时唤醒,但实际上只有一个进程来响应这个事件,其他被唤醒的进程都会重新休眠。其中,accept()的惊群问题,已经在Linux 2.6中解决;而epoll_wait()的问题,到了Linux 4.5,才通过
EPOLLEXCLUSIVE解决。为了避免惊群问题,Nginx在每个worker进程中,都增加了一个全局锁(accept_mutex)。这些worker进程需要首先竞争到锁,只有竞争到锁的进程,才会加入到epoll中,这样就确保只有一个worker子进程被唤醒。
Q: 为什么使用多进程模式的Nginx,却具有非常好的性能呢?
最主要的一个原因是,这些worker进程,实际上并不需要经常创建和销毁,而是在没任务时休眠,有任务时唤醒。只有在worker异常退出时,主进程才需要创建新的进程来代替它。
第2种:监听到相同端口的多进程模型
- 在这种方式下,所有进程都监听相同的端口,并且开启
SO_REUSEPORT选项,由内核负责将请求负载均衡到这些监听进程中去。由于内核确保了只有一个进程被唤醒,就不会出现惊群问题了。比如,Nginx在1.9.1中就已经支持了这种模式。 - 注意,使用
SO_REUSEPORT选项,需要使用Linux 3.9以上的版本才可以。
C1000K
基于I/O多路复用和请求处理的优化,C10K问题很容易就可以解决。不过,随着摩尔定律带来的服务器性能提升,以及互联网的普及,新兴服务会对性能提出更高的要求。很快,原来的C10K已经不能满足需求,所以又有了C100K和C1000K,即,并发从原来的1万,增加到10万,乃至100万。从1万到10万,其实还是基于C10K的这些理论,epoll配合线程池,再加上CPU,内存和网络接口的性能和容量提升,C100K也可以达到。
Q: C1000K可以达到吗?
- 从物理资源上,100万个请求需要大量的系统资源。比如:
- 假设每个请求需要16KB内存,那么总共就需要大约15GB内存。
- 从带宽上来说,即使每个连接只需要1KB/s的吞吐量,假设只有20%的活跃连接,总共也需要1.6Gb/s(
1 * 1000000 / 1024 / 1024 * 8 * 0.2)的吞吐量。因此,千兆网卡无法满足,需要配置万兆网卡,或者基于多网卡Bonding承载更大的吞吐量。
- 从软件资源上,大量的连接会占用大量的软件资源,比如,文件描述符数量,网络协议栈的缓存大小等等。
- 大量请求带来的中断处理,也会带来非常高的处理成本。这样,就需要多队列网卡,中断负责均衡,CPU绑定,RPS/RFS(软中断负责均衡到多个CPU核上),以及将网络包的处理卸载(offload)到网络设备等各种硬件和软件的优化。
本质上,C1000K的解决方法还是构建在epoll的非阻塞I/O模型上。只不过,除了I/O模型之外,还需要从应用程序到Linux内核,再到CPU,内存和网络等各个层次的深度优化,特别是需要借助硬件,来卸载那些原来通过软件处理的大量功能。
C10M
Q: 有没有可能在单机中,同时处理1000万的请求?
实际上,在C1000K问题中,各种软件,硬件的优化很可能都已经做到头了。想实现1000万请求并发,都是极其困难的。究其根本,还是Linux内核协议栈做了太繁重的工作。从网卡中断带来的硬件中断处理程序开始,到软件中断中的各层网络协议处理,最后再到应用程序。这个路径实在是太长了,就会导致网络包的处理优化,到了一定程度后就无法更进一步了。
要解决这个问题,最重要就是跳过内核协议栈的冗长路径,把网络包直接送到要处理的应用程序那里去。这里有两种常见机制。
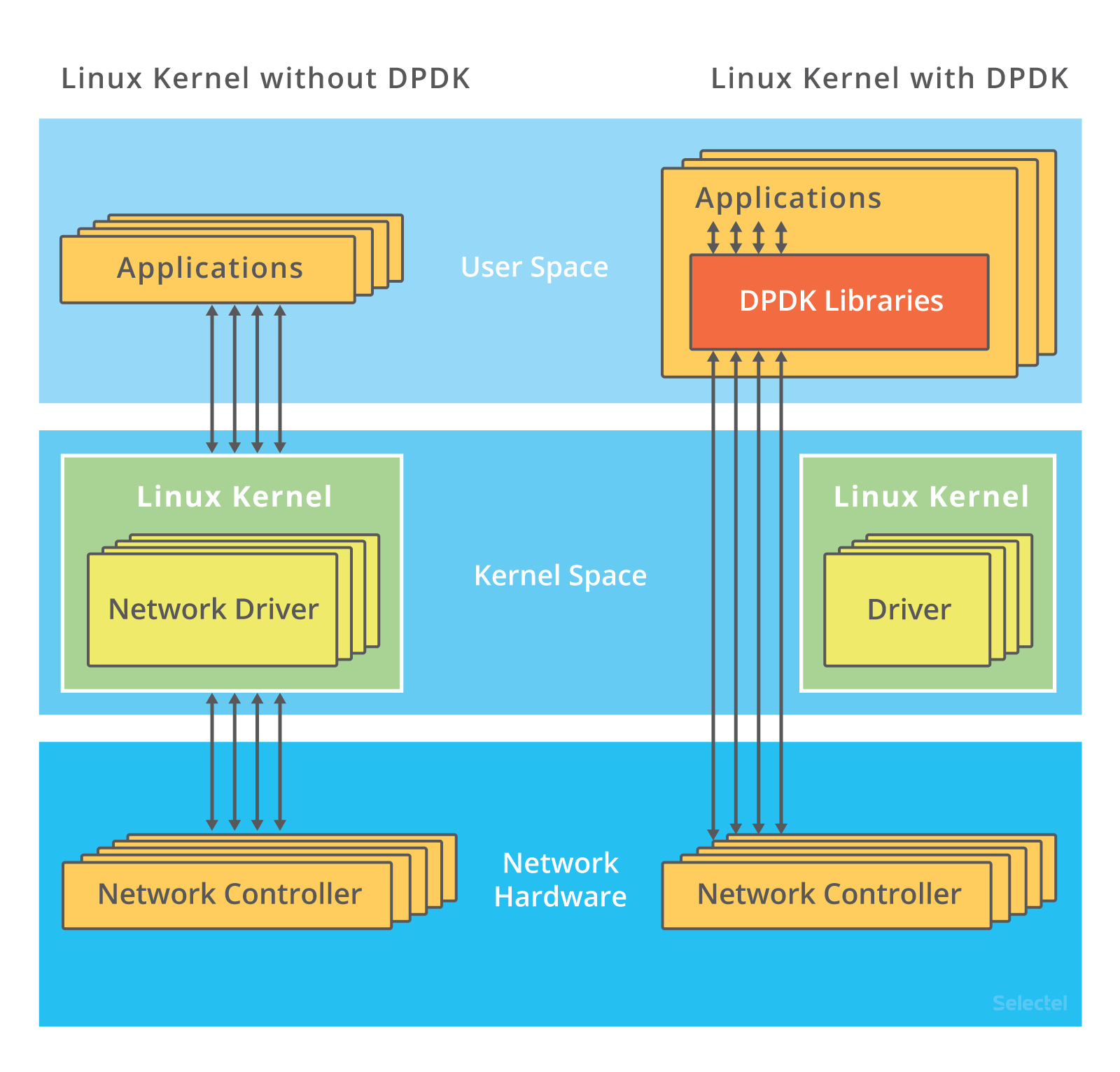
机制1:DPDK。
是用户态网络的标准,它跳过内核协议栈,直接由用户态进程通过轮询的方式来处理网络接收。
- 在PPS非常高的场景中,查询时间比实际工作时间少了很多,绝大部分时间都在处理网络包。
- 而跳过内核协议栈后,就省去了繁杂的硬件中断,软中断再到Linux网络协议栈逐层处理的过程。应用程序可以针对应用的实际场景,有针对性地优化网络包的处理逻辑,而不需要关注所有的细节。
- DPDK还通过大页,CPU绑定,内存对齐,流水线并发等多种机制,优化网络包的处理效率。
Introduction to DPDK: Architecture and Principles
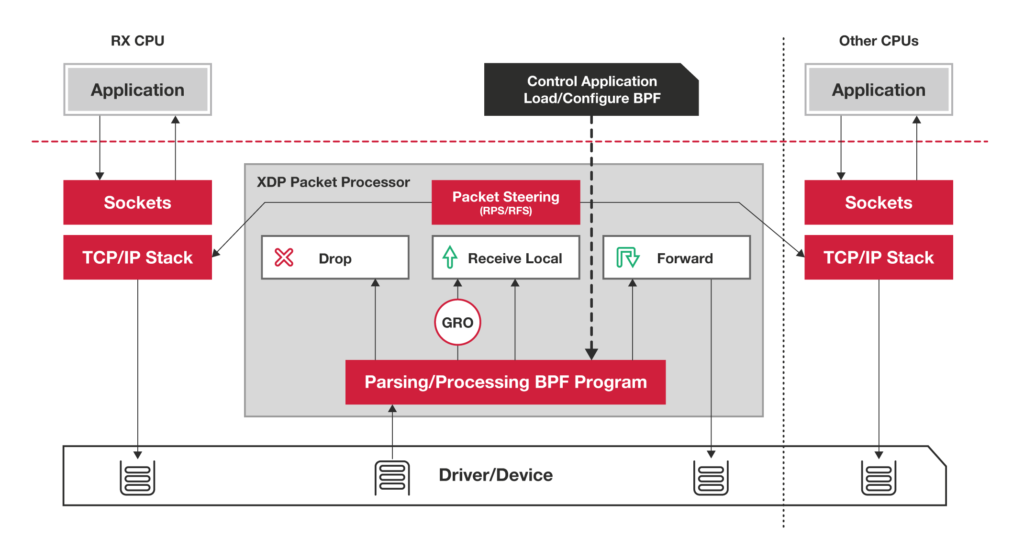
机制2:XDP (eXpress Data Path)
是Linux内核提供的一种高性能网络数据路径。它允许网络包,在进入内核协议栈之前,就进行处理,也可以带来更高的性能。XDP底层跟之前用到的bcc-tools一样,都是基于Linux内核的eBPF机制实现的。
注意,XDP对内核要求比较高,需要Linux 4.8以上版本,并且它也不提供缓存队列。基于XDP的应用程序通常是专用的网络应用,比如,IDS(入侵检测系统),DDoS防御系统等。
其他:
The Secret To 10 Million Concurrent Connections -The Kernel Is The Problem, Not The Solution
性能测试工具
stress
- 一个Linux系统压力测试工具。
- apt install stress
- 模拟一个CPU使用率100%的场景。stress --cpu 1 --timeout 600
- 模拟I/O压力,不停地执行sync。stress -i 1 --hdd 1 --timeout 600 (-i表示调用sync, --hdd表示读写临时文件)
- 模拟大量进程场景。stress -c 8 --timeout 600
- 动态且高亮显示变化的区域 watch -d uptime
top
- 显示了系统总体的CPU和内存使用情况,以及各个进程的资源使用情况。
- top默认显示的是所有CPU的平均值,按数字1可以切换到每个CPU的使用率。('1' single/separate states)
- `-H`显示线程。('H' Threads)
- `-c`显示参数列表。 ('c' Cmd name/line)
- 列字段含义:
+ S列(Status)表示进程的状态
| 进程状态(部分) | 含义 | 发生场景 |
|---|---|---|
| R (Running) | 进程在CPU的就绪队列中,正在运行或正在等待运行 | |
| D (Disk Sleep) | 不可中断状态睡眠,一般表示进程正在与硬件交互,并且交互过程不允许被其他进程或中断打断 | 系统或硬件发生了故障,进程可能会在不可中断状态保持很久,或导致系统中出现大量不可中断进程 |
| S (Interruptible Sleep) | 可中断状态睡眠,表示进程因为等待某个事件而被系统挂起 | |
| Z (Zombie) | 僵尸进程,表示进程实际上已经结束了,但是父进程还没有回收它的资源 | 当一个进程创建了子进程后,它应该通过系统调用wait或waitpid等待子进程结束,回收子进程的资源。而子进程在结束时,会向它的父进程发送SIGCHLD信号,父进程可以注册SIGCHLD信号处理函数异步回收子进程的资源。如果父进程没有处理子进程的状态,子进程就会变成僵尸进程。(打个比喻:父亲应该一直对儿子负责,善始善终,如果不作为或者跟不上,都会导致问题少年的出现)。通常,僵尸进程持续的时间都比较短,在父进程回收它的资源后就会消亡;或者在父进程退出后,由init进程回收后也会消亡。但是,如果父进程没有处理子进程的终止还一直保持运行状态,那么子进程就会一直处于僵尸状态,大量的僵尸进程会用尽PID进程号导致新进程不能创建 |
| I (Idle) | 空闲状态,用在不可中断睡眠的内核线程上。注意,硬件交互导致的不可中断进程用D表示,但对某些内核线程来说,它们有可能实际上并没有任何负载,用Idle是为了区分这种情况。D状态的进程会导致平均负载升高,但I状态的进程却不会 | |
| T (Stopped/Traced) | 进程处于暂停或者跟踪状态。向一个进程发送SIGSTOP信号,它会变成暂停状态(Stopped),再向它发送SIGCONT信号,进程又会恢复运行;或者当用gdb断点中断进程后,进程会变成跟踪状态 | |
| X (Dead) | 进程已经消亡,不会在top或ps中看到 |
$ top
top - 11:41:27 up 224 days, 19:54, 1 user, load average: 0.01, 0.06, 0.06
Tasks: 140 total, 1 running, 139 sleeping, 0 stopped, 0 zombie
Cpu(s): 0.1%us, 0.2%sy, 0.0%ni, 99.7%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st
Mem: 12174404k total, 4983532k used, 7190872k free, 367820k buffers
Swap: 2104508k total, 0k used, 2104508k free, 3361592k cached
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
1 root 20 0 22392 1584 1280 S 0.0 0.0 0:15.06 init
2 root 20 0 0 0 0 S 0.0 0.0 0:01.42 kthreadd
3 root 20 0 0 0 0 S 0.0 0.0 0:39.30 ksoftirqd/0
5 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 kworker/0:0H
7 root RT 0 0 0 0 S 0.0 0.0 0:36.80 migration/0
8 root 20 0 0 0 0 S 0.0 0.0 0:00.00 rcu_bh
9 root 20 0 0 0 0 S 0.0 0.0 0:00.00 rcuob/0
ps
- 显示了每个进程的资源使用情况。
mpstat
- 一个常用的多核CPU性能分析工具,用来实时查看每个CPU的性能指标,以及所有CPU的平均指标。
- apt install sysstat
- 监控所有CPU且5秒输出一次 mpstat -P ALL 5
pidstat
- 一个常用的进程性能分析工具,用来实时查看进程的CPU,内存,I/O以及上下文切换等性能指标。
- apt install sysstat
- 间隔5秒输出一组数据 pidstat -u 5 1
- CentOS的pidstat没有%wait指标(进程等待CPU的时间百分比),这个是sysstat 11.5.5版本才引入的新指标。
- pidstat中的%wait表示进程等待CPU的时间百分比,而top中的iowait%表示等待I/O的CPU时间百分比。两者是不同的指标。
- 数据指标:
+ cswch (voluntary context switches)表示每秒自愿上下文切换的次数。是指进程无法获取所需资源,导致的上下文切换(例如,I/O,内存等系统资源不足时)。
+ nvcswch (non-voluntary context switches)表示每秒非自愿上下文切换的次数。是指进程由于时间片已到等原因,被系统强制调度,而发生的上下文切换(例如,大量进程都在争抢CPU时)。
$ pidstat -wt 5
Linux 3.10.107-1-tlinux2_kvm_guest-0046 (VM_4_14_centos) 12/20/18 _x86_64_ (8 CPU)
09:26:57 UID TGID TID cswch/s nvcswch/s Command
09:27:02 0 1 - 10.47 0.00 systemd
09:27:02 0 - 1 10.47 0.00 |__systemd
09:27:02 0 2 - 0.20 0.00 kthreadd
09:27:02 0 - 2 0.20 0.00 |__kthreadd
09:27:02 0 3 - 7.11 0.00 ksoftirqd/0
09:27:02 0 - 3 7.11 0.00 |__ksoftirqd/0
09:27:02 0 7 - 1.19 0.00 migration/0
09:27:02 0 - 7 1.19 0.00 |__migration/0
09:27:02 0 17 - 91.90 0.00 rcu_sched
09:27:02 0 - 17 91.90 0.00 |__rcu_sched
09:27:02 0 18 - 27.87 0.00 rcuos/0
09:27:02 0 - 18 27.87 0.00 |__rcuos/0
09:27:02 0 19 - 27.87 0.00 rcuos/1
09:27:02 0 - 19 27.87 0.00 |__rcuos/1
vmstat
Q: vmstat输出的第一行数据为什么和其他行差别巨大?
A: The first report produced gives averages since the last reboot. Additional reports give information on a sampling period of length delay. The process and memory reports are instantaneous in either case. (man vmstat)
数据指标:
- r (Running or Runnable)是就绪队列的长度,也就是正在运行和等待CPU的进程数。
- b (Blocked)是处于不可中断睡眠状态的进程数。
- cs (context switch)是每秒上下文切换的次数。
- in (interrupt)是每秒中断的次数。
- bi 块设备读取的大小,单位为块/秒(因为Linux中块的大小是1KB,所以单位等价于KB/s)
- bo 块设备写入的大小,单位为块/秒
# 每隔5秒输出1组数据
$vmstat 5
procs -----------memory---------- ---swap-- -----io---- -system-- -----cpu------
r b swpd free buff cache si so bi bo in cs us sy id wa st
0 0 1032316 6471492 387968 5092564 0 0 0 0 0 0 0 0 99 1 0
0 0 1032316 6471860 387984 5092548 0 0 0 122 312 10741 0 0 99 1 0
0 0 1032316 6472252 387996 5092536 0 0 0 89 302 10531 0 0 99 1 0
0 0 1032316 6471632 388012 5093548 0 0 0 242 326 10559 0 0 99 1 0
sysbench
CentOS
sysbench --num-threads=10 --max-time=300 --max-requests=1000000 --test=threads --thread-yields=1000 --thread-locks=8 run
proc
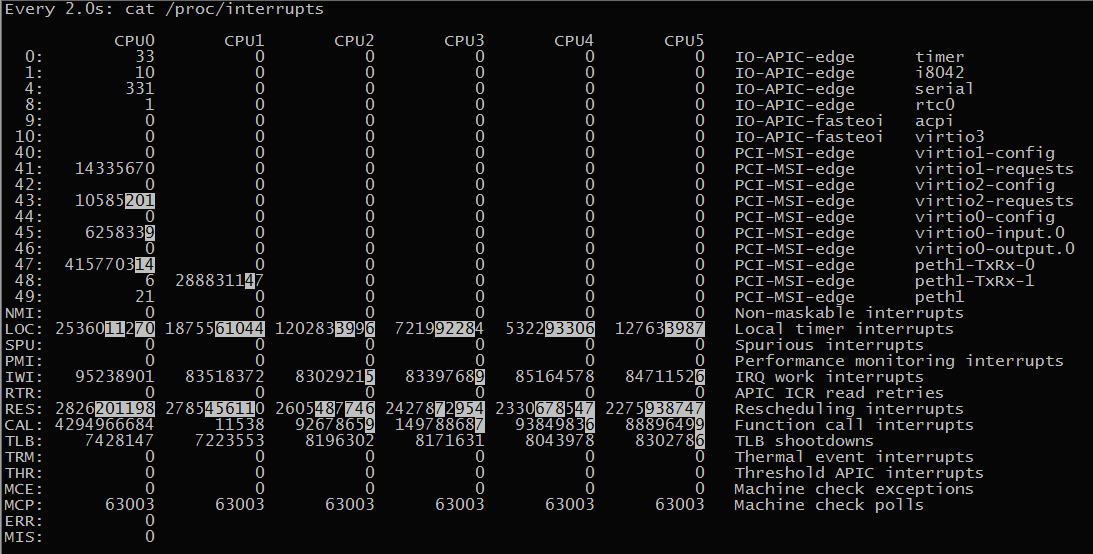
查看中断使用情况,其中RES表示重调度中断(唤醒空闲状态的CPU来调度新的任务运行)
watch -d cat /proc/interrupts
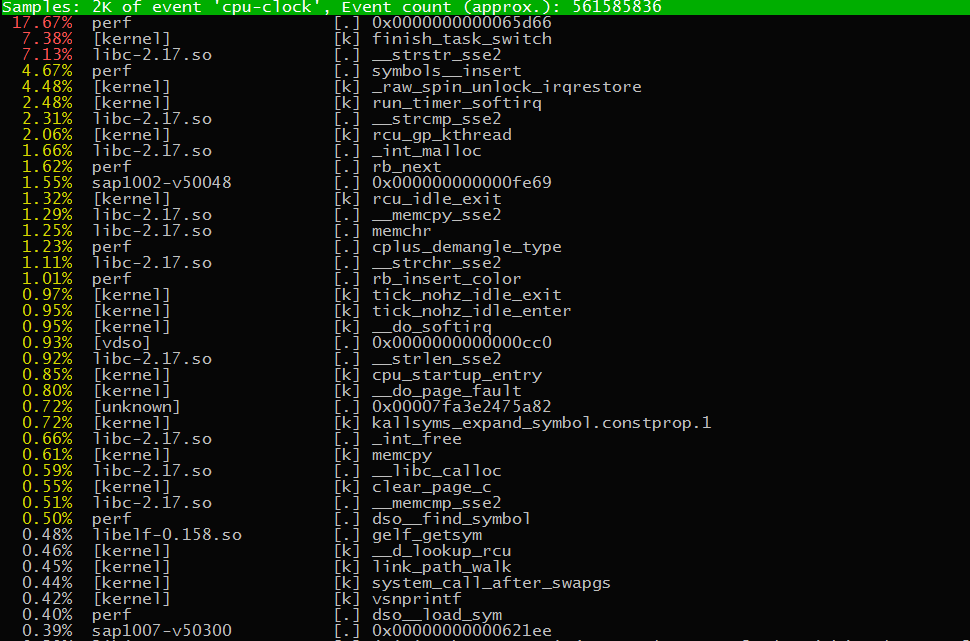
perf
- 实时统计。
- perf top (实时显示占用CPU时钟最多的函数或指令,用来查找热点函数,缺点是无法离线保存数据用于事后分析)
- 第一行包含三个数据,分别是:采样数(Samples),事件类型(event),事件总量(Event count)
- 表格中,第一行包含四列:
- 第一列
Overhead,是该符号的性能事件在所有采样中的比例,用百分比来表示。 - 第二列
Shared,是该函数或指令所在的动态共享对象(Dynamic Shared Object),如内核,进程名,动态链接库名,内核模块名等。 - 第三列
Object,是动态共享对象的类型。比如,[.]表示用户空间的可执行程序,或者动态链接库;[k]表示内核空间。 - 第四列
Symbol,是符号名(即,函数名)。当函数名未知时,用十六进制的地址来表示。
- 第一列
- 离线分析。
- perf record -ag 记录性能事件,等待x秒后Ctrl+C退出
- perf report 查看报告
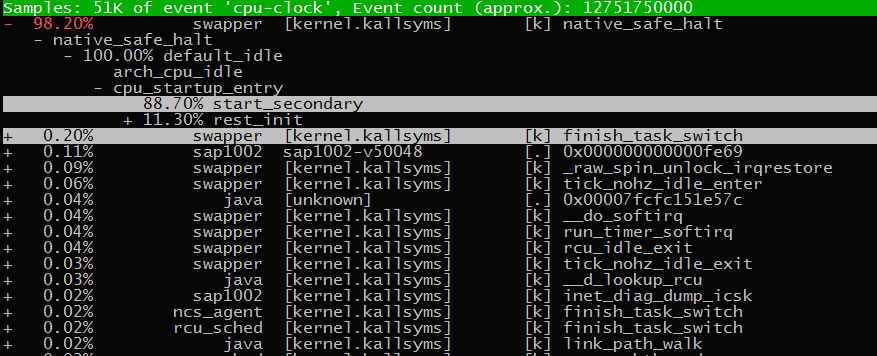
refer: brendangregg: perf Examples
strace
ab
ab -c 10 -n 10000 http://ip:port
sar
- Collect, report, or save system activity information.
- 一个系统活动报告工具,既可以实时查看系统的当前活动,又可以配置保存和报告历史统计数
# 查看CPU使用率
sar -u 1
# -n DEV表示显示网络收发的报告, 间隔1秒输出一组数据
$sar -n DEV 1
Linux 3.10.94-1-tlinux2_kvm_guest-0019.tl2 (TENCENT64.site) 12/31/18 _x86_64_ (8 CPU)
17:41:55 IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s
17:41:56 eth0 0.00 0.00 0.00 0.00 0.00 0.00 0.00
17:41:56 peth1 7.00 20.00 0.85 4.85 0.00 0.00 0.00
17:41:56 eth1 7.00 20.00 0.85 4.85 0.00 0.00 0.00
17:41:56 peth21 0.00 0.00 0.00 0.00 0.00 0.00 0.00
17:41:56 lo 0.00 0.00 0.00 0.00 0.00 0.00 0.00
第一列,是报告的时间。 IFACE,是网卡。 rxpck/s和txpck/s,分别是每秒接收,发送的网络帧数。 rxkB/s和txkB/s,分别是每秒接收,发送的千字节数。
hping3
一个可以构造TCP/IP协议数据包的工具,可以对系统进行安全审计,防火墙测试等
# 模拟SYN FLOOD攻击
# -S参数表示设置TCP协议的SYN(同步序列号),-p表示目的端口为80
# -i u100表示每隔100微妙发送一个网络帧
# 注意:如果在实践过程中现象不明显,可以尝试把100调小
$ hping3 -S -p 80 -i u100 192.168.0.30
PS: SYN FLOOD问题最简单的解决方法,是从交换机或硬件防火墙中封掉来源IP,这样SYN FLOOD网络帧就不会发送到服务器中。
tcpdump
一个常用的网络抓包工具,用于分析网络问题
tcpdump -i eth0 -n tcp port 80
dd
注意,如果使用dd测试文件系统性能,由于缓存的存在,就会导致测试结果严重失真。
测试场景:
使用dd测试读写文件,用vmstat查看,Buffer是对磁盘数据的缓存,而Cache是文件数据的缓存,它们既会用在读请求中,也会用在写请求中。
准备工作:
# 清理文件页,目录项,Inodes等各种缓存:
echo 3 > /proc/sys/vm/drop_caches
# 查看cache使用情况
vmstat 1
写案例:
# 通过读取随机设备,生成一个500MB大小的文件
dd if=/dev/urandom of=/tmp/file bs=1M count=500
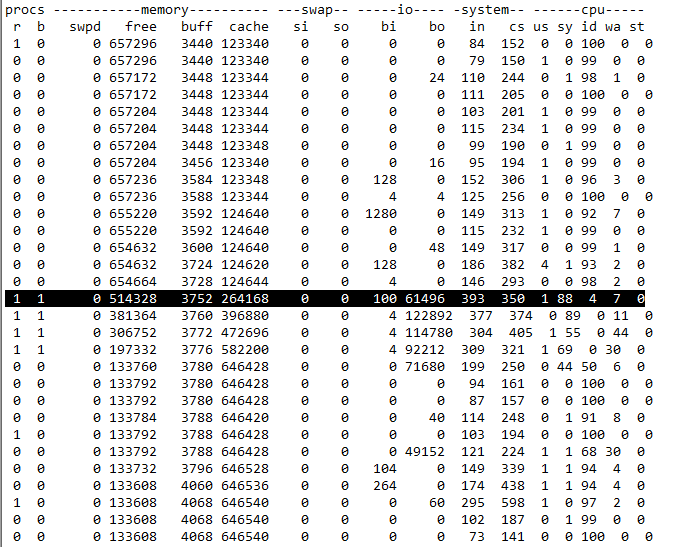
bi和bo,分别表示块设备读取和写入的大小,单位为块/秒(因为Linux中块的大小是1KB,所以单位等价于KB/s)。将bo加起来就是写入的500MB。
读案例:
# 读
dd if=/tmp/file of=/dev/null
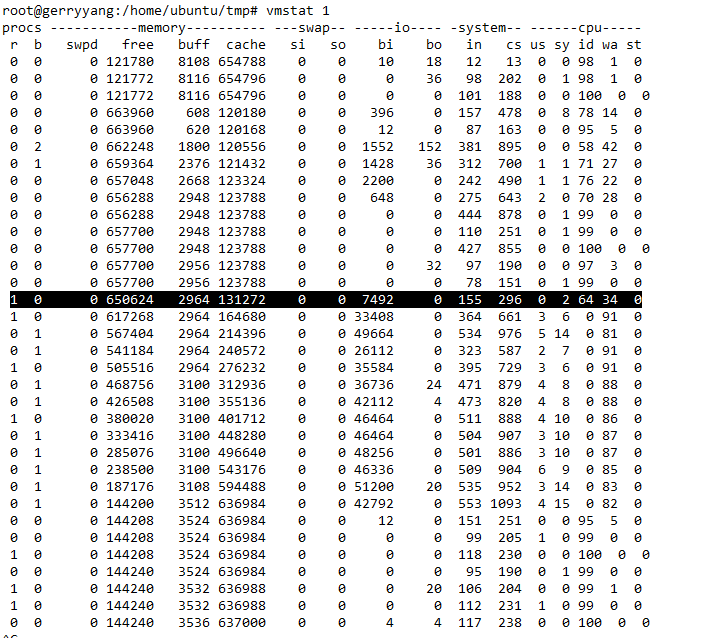
- cachestat
- 提供了整个操作系统缓存的读写命中情况
- TOTAL,总的I/O次数
- MISSES,缓存未命中的次数
- HITS,缓存命中的次数
- DIRTIES,新增到缓存中的脏页数
- BUFFERS_MB,Buffers的大小,以MB为单位
- CACHED_MB,Cache的大小,以MB为单位
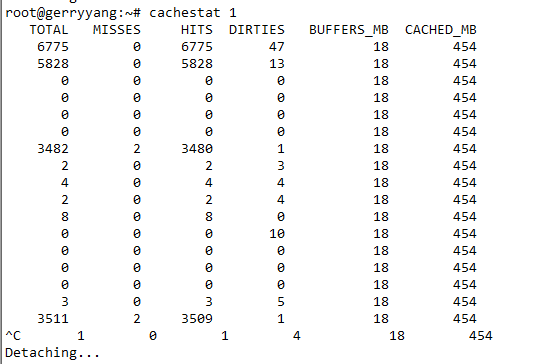
cachetop
提供了每个进程的缓存命中情况
pcstat
pcstat是一个基于Go开发的工具,指定和查看文件的缓存大小。
go get github.com/tobert/pcstat
mtr
mtr - a network diagnostic tool
开发语言性能比较
Web服务性能比较
- Web-server-performance-comparison
- nginx-vs-apache-are-there-any-actual-usage-comparisons-and-statistcs-out-there
- How_does_Apache_httpd_performance_compare_to_other_servers
Other
- Testing Memory Allocators: ptmalloc2 vs tcmalloc vs hoard vs jemalloc While Trying to Simulate Real-World Loads
- Linux Performance Analysis in 60,000 Milliseconds
- Infographics: Operation Costs in CPU Clock Cycles